 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionSegReID: Advancing Person Re-Identification with Multimodal Retrieval and Precise Segmentation
Mar 27, 2025
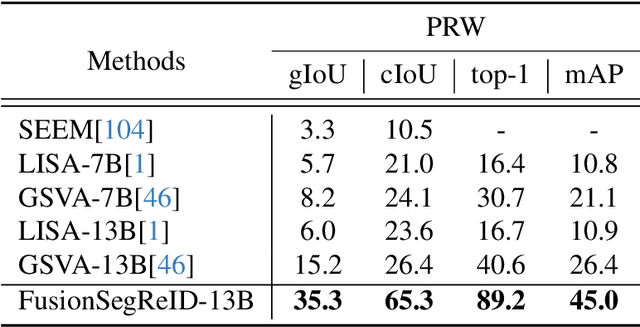
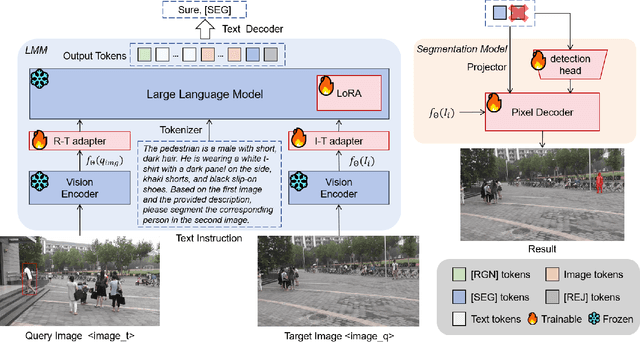
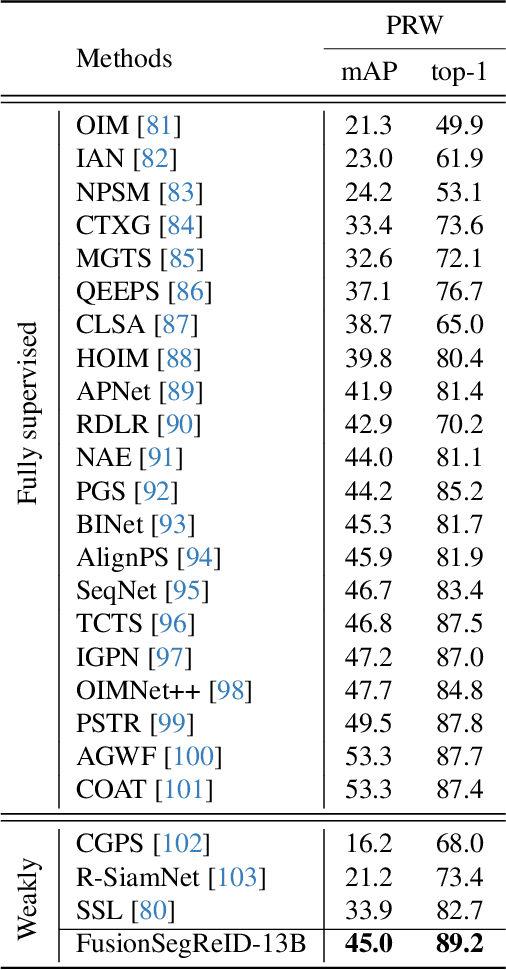
Person re-identification (ReID) plays a critical role in applications like security surveillance and criminal investigations by matching individuals across large image galleries captured by non-overlapping cameras. Traditional ReID methods rely on unimodal inputs, typically images, but face limitations due to challenges like occlusions, lighting changes, and pose variations. While advancements in image-based and text-based ReID systems have been made, the integration of both modalities has remained under-explored. This paper presents FusionSegReID, a multimodal model that combines both image and text inputs for enhanced ReID performance. By leveraging the complementary strengths of these modalities, our model improves matching accuracy and robustness, particularly in complex, real-world scenarios where one modality may struggle. Our experiments show significant improvements in Top-1 accuracy and mean Average Precision (mAP) for ReID, as well as better segmentation results in challenging scenarios like occlusion and low-quality images. Ablation studies further confirm that multimodal fusion and segmentation modules contribute to enhanced re-identification and mask accuracy. The results show that FusionSegReID outperforms traditional unimodal models, offering a more robust and flexible solution for real-world person ReID tasks.
Car-1000: A New Large Scale Fine-Grained Visual Categorization Dataset
Mar 16, 2025



Fine-grained visual categorization (FGVC) is a challenging but significant task in computer vision, which aims to recognize different sub-categories of birds, cars, airplanes, etc. Among them, recognizing models of different cars has significant application value in autonomous driving, traffic surveillance and scene understanding, which has received considerable attention in the past few years. However, Stanford-Car, the most widely used fine-grained dataset for car recognition, only has 196 different categories and only includes vehicle models produced earlier than 2013. Due to the rapid advancements in the automotive industry during recent years, the appearances of various car models have become increasingly intricate and sophisticated. Consequently, the previous Stanford-Car dataset fails to capture this evolving landscape and cannot satisfy the requirements of automotive industry. To address these challenges, in our paper, we introduce Car-1000, a large-scale dataset designed specifically for fine-grained visual categorization of diverse car models. Car-1000 encompasses vehicles from 165 different automakers, spanning a wide range of 1000 distinct car models. Additionally, we have reproduced several state-of-the-art FGVC methods on the Car-1000 dataset, establishing a new benchmark for research in this field. We hope that our work will offer a fresh perspective for future FGVC researchers. Our dataset is available at https://github.com/toggle1995/Car-1000.