 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionSegReID: Advancing Person Re-Identification with Multimodal Retrieval and Precise Segmentation
Paper and Code
Mar 27, 2025
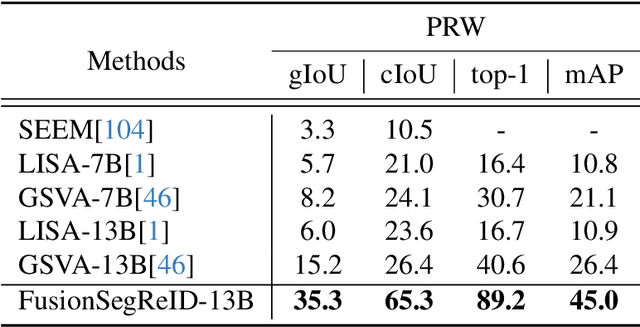
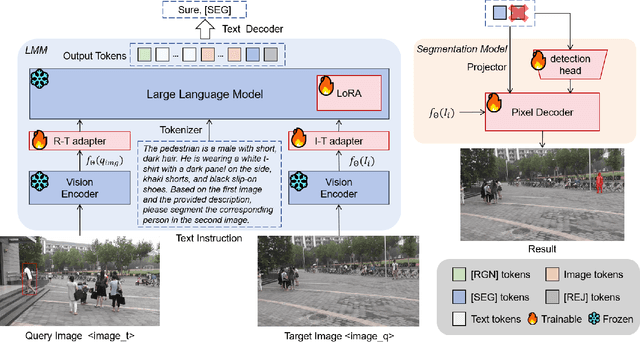
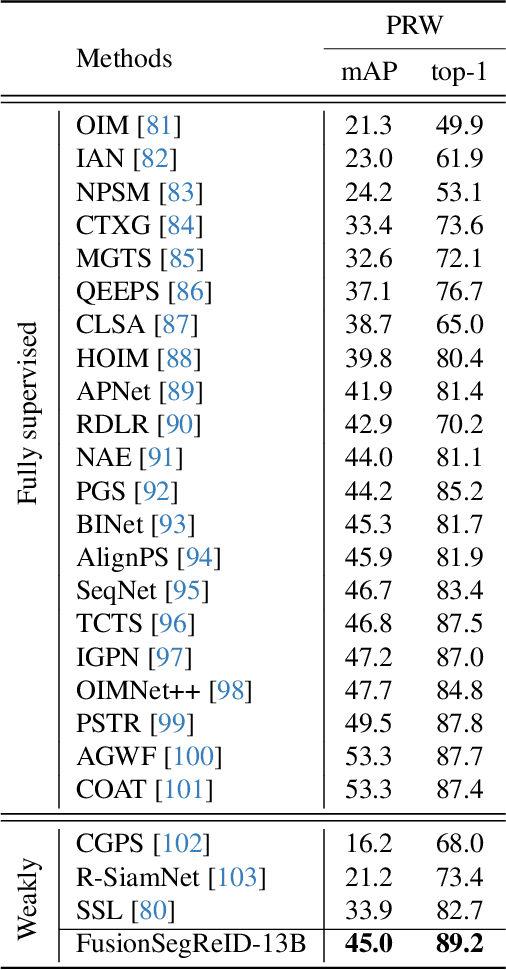
Person re-identification (ReID) plays a critical role in applications like security surveillance and criminal investigations by matching individuals across large image galleries captured by non-overlapping cameras. Traditional ReID methods rely on unimodal inputs, typically images, but face limitations due to challenges like occlusions, lighting changes, and pose variations. While advancements in image-based and text-based ReID systems have been made, the integration of both modalities has remained under-explored. This paper presents FusionSegReID, a multimodal model that combines both image and text inputs for enhanced ReID performance. By leveraging the complementary strengths of these modalities, our model improves matching accuracy and robustness, particularly in complex, real-world scenarios where one modality may struggle. Our experiments show significant improvements in Top-1 accuracy and mean Average Precision (mAP) for ReID, as well as better segmentation results in challenging scenarios like occlusion and low-quality images. Ablation studies further confirm that multimodal fusion and segmentation modules contribute to enhanced re-identification and mask accuracy. The results show that FusionSegReID outperforms traditional unimodal models, offering a more robust and flexible solution for real-world person ReID tasks.