 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocal Guidance: Unlocking Controllability from Semantic-Weak Layers in Video Diffusion Models
Jan 12, 2026The task of Image-to-Video (I2V) generation aims to synthesize a video from a reference image and a text prompt. This requires diffusion models to reconcile high-frequency visual constraints and low-frequency textual guidance during the denoising process. However, while existing I2V models prioritize visual consistency, how to effectively couple this dual guidance to ensure strong adherence to the text prompt remains underexplored. In this work, we observe that in Diffusion Transformer (DiT)-based I2V models, certain intermediate layers exhibit weak semantic responses (termed Semantic-Weak Layers), as indicated by a measurable drop in text-visual similarity. We attribute this to a phenomenon called Condition Isolation, where attention to visual features becomes partially detached from text guidance and overly relies on learned visual priors. To address this, we propose Focal Guidance (FG), which enhances the controllability from Semantic-Weak Layers. FG comprises two mechanisms: (1) Fine-grained Semantic Guidance (FSG) leverages CLIP to identify key regions in the reference frame and uses them as anchors to guide Semantic-Weak Layers. (2) Attention Cache transfers attention maps from semantically responsive layers to Semantic-Weak Layers, injecting explicit semantic signals and alleviating their over-reliance on the model's learned visual priors, thereby enhancing adherence to textual instructions. To further validate our approach and address the lack of evaluation in this direction, we introduce a benchmark for assessing instruction following in I2V models. On this benchmark, Focal Guidance proves its effectiveness and generalizability, raising the total score on Wan2.1-I2V to 0.7250 (+3.97\%) and boosting the MMDiT-based HunyuanVideo-I2V to 0.5571 (+7.44\%).
ProSoftArena: Benchmarking Hierarchical Capabilities of Multimodal Agents in Professional Software Environments
Dec 30, 2025Multimodal agents are making rapid progress on general computer-use tasks, yet existing benchmarks remain largely confined to browsers and basic desktop applications, falling short in professional software workflows that dominate real-world scientific and industrial practice. To close this gap, we introduce ProSoftArena, a benchmark and platform specifically for evaluating multimodal agents in professional software environments. We establish the first capability hierarchy tailored to agent use of professional software and construct a benchmark of 436 realistic work and research tasks spanning 6 disciplines and 13 core professional applications. To ensure reliable and reproducible assessment, we build an executable real-computer environment with an execution-based evaluation framework and uniquely incorporate a human-in-the-loop evaluation paradigm. Extensive experiments show that even the best-performing agent attains only a 24.4\% success rate on L2 tasks and completely fails on L3 multi-software workflow. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents in professional software settings. This project is available at: https://prosoftarena.github.io.
Yume-1.5: A Text-Controlled Interactive World Generation Model
Dec 26, 2025Recent approaches have demonstrated the promise of using diffusion models to generate interactive and explorable worlds. However, most of these methods face critical challenges such as excessively large parameter sizes, reliance on lengthy inference steps, and rapidly growing historical context, which severely limit real-time performance and lack text-controlled generation capabilities. To address these challenges, we propose \method, a novel framework designed to generate realistic, interactive, and continuous worlds from a single image or text prompt. \method achieves this through a carefully designed framework that supports keyboard-based exploration of the generated worlds. The framework comprises three core components: (1) a long-video generation framework integrating unified context compression with linear attention; (2) a real-time streaming acceleration strategy powered by bidirectional attention distillation and an enhanced text embedding scheme; (3) a text-controlled method for generating world events. We have provided the codebase in the supplementary material.
SVBench: Evaluation of Video Generation Models on Social Reasoning
Dec 25, 2025Recent text-to-video generation models exhibit remarkable progress in visual realism, motion fidelity, and text-video alignment, yet they remain fundamentally limited in their ability to generate socially coherent behavior. Unlike humans, who effortlessly infer intentions, beliefs, emotions, and social norms from brief visual cues, current models tend to render literal scenes without capturing the underlying causal or psychological logic. To systematically evaluate this gap, we introduce the first benchmark for social reasoning in video generation. Grounded in findings from developmental and social psychology, our benchmark organizes thirty classic social cognition paradigms into seven core dimensions, including mental-state inference, goal-directed action, joint attention, social coordination, prosocial behavior, social norms, and multi-agent strategy. To operationalize these paradigms, we develop a fully training-free agent-based pipeline that (i) distills the reasoning mechanism of each experiment, (ii) synthesizes diverse video-ready scenarios, (iii) enforces conceptual neutrality and difficulty control through cue-based critique, and (iv) evaluates generated videos using a high-capacity VLM judge across five interpretable dimensions of social reasoning. Using this framework, we conduct the first large-scale study across seven state-of-the-art video generation systems. Our results reveal substantial performance gaps: while modern models excel in surface-level plausibility, they systematically fail in intention recognition, belief reasoning, joint attention, and prosocial inference.
Code-in-the-Loop Forensics: Agentic Tool Use for Image Forgery Detection
Dec 18, 2025
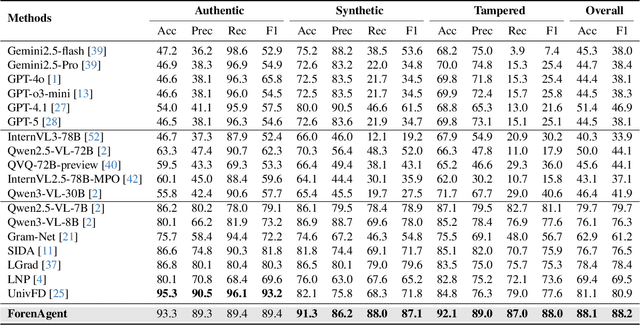
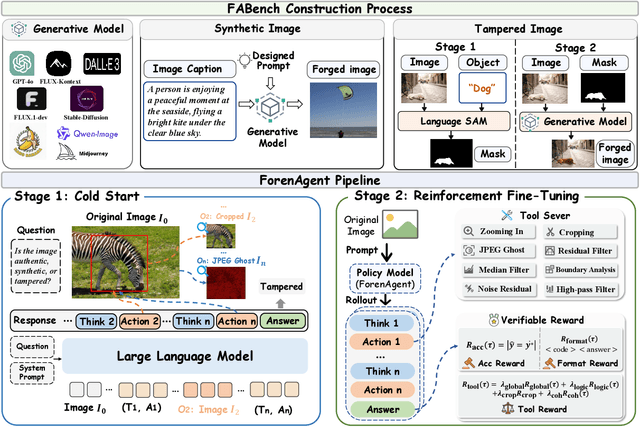
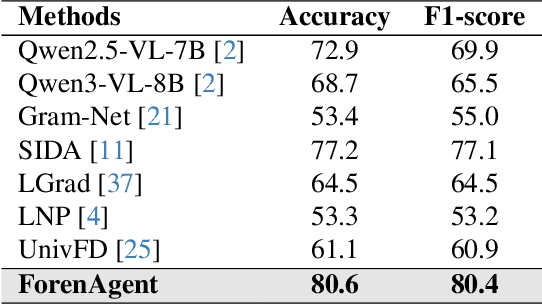
Existing image forgery detection (IFD) methods either exploit low-level, semantics-agnostic artifacts or rely on multimodal large language models (MLLMs) with high-level semantic knowledge. Although naturally complementary, these two information streams are highly heterogeneous in both paradigm and reasoning, making it difficult for existing methods to unify them or effectively model their cross-level interactions. To address this gap, we propose ForenAgent, a multi-round interactive IFD framework that enables MLLMs to autonomously generate, execute, and iteratively refine Python-based low-level tools around the detection objective, thereby achieving more flexible and interpretable forgery analysis. ForenAgent follows a two-stage training pipeline combining Cold Start and Reinforcement Fine-Tuning to enhance its tool interaction capability and reasoning adaptability progressively. Inspired by human reasoning, we design a dynamic reasoning loop comprising global perception, local focusing, iterative probing, and holistic adjudication, and instantiate it as both a data-sampling strategy and a task-aligned process reward. For systematic training and evaluation, we construct FABench, a heterogeneous, high-quality agent-forensics dataset comprising 100k images and approximately 200k agent-interaction question-answer pairs. Experiments show that ForenAgent exhibits emergent tool-use competence and reflective reasoning on challenging IFD tasks when assisted by low-level tools, charting a promising route toward general-purpose IFD. The code will be released after the review process is completed.
Dialogue as Discovery: Navigating Human Intent Through Principled Inquiry
Oct 31, 2025A fundamental bottleneck in human-AI collaboration is the "intention expression gap," the difficulty for humans to effectively convey complex, high-dimensional thoughts to AI. This challenge often traps users in inefficient trial-and-error loops and is exacerbated by the diverse expertise levels of users. We reframe this problem from passive instruction following to a Socratic collaboration paradigm, proposing an agent that actively probes for information to resolve its uncertainty about user intent. we name the proposed agent Nous, trained to acquire proficiency in this inquiry policy. The core mechanism of Nous is a training framework grounded in the first principles of information theory. Within this framework, we define the information gain from dialogue as an intrinsic reward signal, which is fundamentally equivalent to the reduction of Shannon entropy over a structured task space. This reward design enables us to avoid reliance on costly human preference annotations or external reward models. To validate our framework, we develop an automated simulation pipeline to generate a large-scale, preference-based dataset for the challenging task of scientific diagram generation. Comprehensive experiments, including ablations, subjective and objective evaluations, and tests across user expertise levels, demonstrate the effectiveness of our proposed framework. Nous achieves leading efficiency and output quality, while remaining robust to varying user expertise. Moreover, its design is domain-agnostic, and we show evidence of generalization beyond diagram generation. Experimental results prove that our work offers a principled, scalable, and adaptive paradigm for resolving uncertainty about user intent in complex human-AI collaboration.
From Pixels to Paths: A Multi-Agent Framework for Editable Scientific Illustration
Oct 31, 2025Scientific illustrations demand both high information density and post-editability. However, current generative models have two major limitations: Frist, image generation models output rasterized images lacking semantic structure, making it impossible to access, edit, or rearrange independent visual components in the images. Second, code-based generation methods (TikZ or SVG), although providing element-level control, force users into the cumbersome cycle of "writing-compiling-reviewing" and lack the intuitiveness of manipulation. Neither of these two approaches can well meet the needs for efficiency, intuitiveness, and iterative modification in scientific creation. To bridge this gap, we introduce VisPainter, a multi-agent framework for scientific illustration built upon the model context protocol. VisPainter orchestrates three specialized modules-a Manager, a Designer, and a Toolbox-to collaboratively produce diagrams compatible with standard vector graphics software. This modular, role-based design allows each element to be explicitly represented and manipulated, enabling true element-level control and any element can be added and modified later. To systematically evaluate the quality of scientific illustrations, we introduce VisBench, a benchmark with seven-dimensional evaluation metrics. It assesses high-information-density scientific illustrations from four aspects: content, layout, visual perception, and interaction cost. To this end, we conducted extensive ablation experiments to verify the rationality of our architecture and the reliability of our evaluation methods. Finally, we evaluated various vision-language models, presenting fair and credible model rankings along with detailed comparisons of their respective capabilities. Additionally, we isolated and quantified the impacts of role division, step control,and description on the quality of illustrations.
Symbolic Graphics Programming with Large Language Models
Sep 05, 2025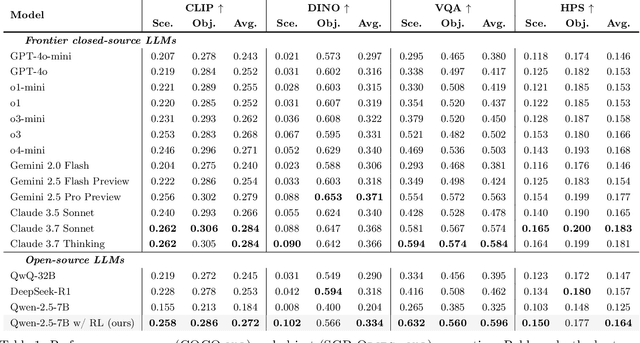
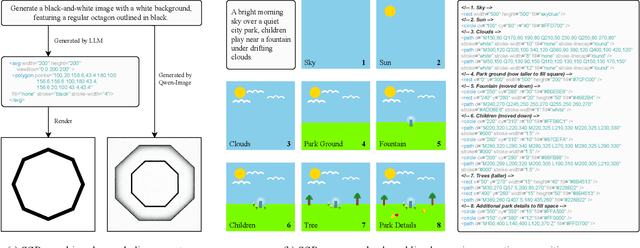
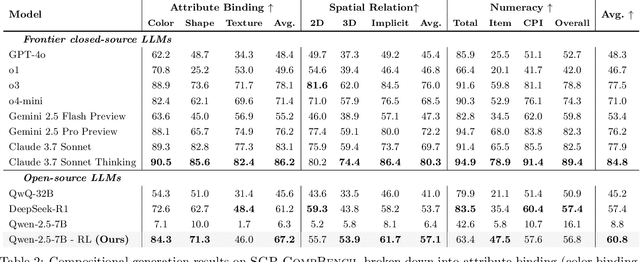
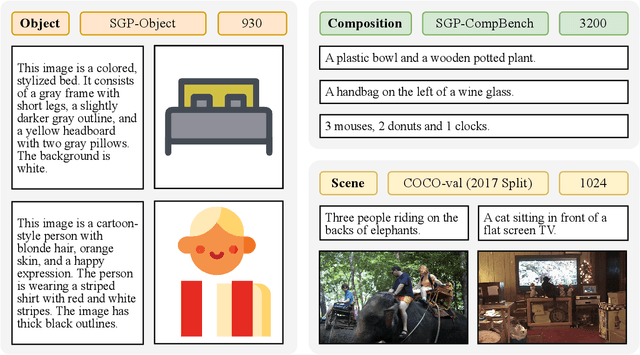
Large language models (LLMs) excel at program synthesis, yet their ability to produce symbolic graphics programs (SGPs) that render into precise visual content remains underexplored. We study symbolic graphics programming, where the goal is to generate an SGP from a natural-language description. This task also serves as a lens into how LLMs understand the visual world by prompting them to generate images rendered from SGPs. Among various SGPs, our paper sticks to scalable vector graphics (SVGs). We begin by examining the extent to which LLMs can generate SGPs. To this end, we introduce SGP-GenBench, a comprehensive benchmark covering object fidelity, scene fidelity, and compositionality (attribute binding, spatial relations, numeracy). On SGP-GenBench, we discover that frontier proprietary models substantially outperform open-source models, and performance correlates well with general coding capabilities. Motivated by this gap, we aim to improve LLMs' ability to generate SGPs. We propose a reinforcement learning (RL) with verifiable rewards approach, where a format-validity gate ensures renderable SVG, and a cross-modal reward aligns text and the rendered image via strong vision encoders (e.g., SigLIP for text-image and DINO for image-image). Applied to Qwen-2.5-7B, our method substantially improves SVG generation quality and semantics, achieving performance on par with frontier systems. We further analyze training dynamics, showing that RL induces (i) finer decomposition of objects into controllable primitives and (ii) contextual details that improve scene coherence. Our results demonstrate that symbolic graphics programming offers a precise and interpretable lens on cross-modal grounding.
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Aug 25, 2025



We introduce InternVL 3.5, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the Cascade Reinforcement Learning (Cascade RL) framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a Visual Resolution Router (ViR) that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled Vision-Language Deployment (DvD) strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05$\times$ inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks -- narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
MDK12-Bench: A Comprehensive Evaluation of Multimodal Large Language Models on Multidisciplinary Exams
Aug 09, 2025Multimodal large language models (MLLMs), which integrate language and visual cues for problem-solving, are crucial for advancing artificial general intelligence (AGI). However, current benchmarks for measuring the intelligence of MLLMs suffer from limited scale, narrow coverage, and unstructured knowledge, offering only static and undifferentiated evaluations. To bridge this gap, we introduce MDK12-Bench, a large-scale multidisciplinary benchmark built from real-world K-12 exams spanning six disciplines with 141K instances and 6,225 knowledge points organized in a six-layer taxonomy. Covering five question formats with difficulty and year annotations, it enables comprehensive evaluation to capture the extent to which MLLMs perform over four dimensions: 1) difficulty levels, 2) temporal (cross-year) shifts, 3) contextual shifts, and 4) knowledge-driven reasoning. We propose a novel dynamic evaluation framework that introduces unfamiliar visual, textual, and question form shifts to challenge model generalization while improving benchmark objectivity and longevity by mitigating data contamination. We further evaluate knowledge-point reference-augmented generation (KP-RAG) to examine the role of knowledge in problem-solving. Key findings reveal limitations in current MLLMs in multiple aspects and provide guidance for enhancing model robustness, interpretability, and AI-assisted education.