 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue as Discovery: Navigating Human Intent Through Principled Inquiry
Oct 31, 2025A fundamental bottleneck in human-AI collaboration is the "intention expression gap," the difficulty for humans to effectively convey complex, high-dimensional thoughts to AI. This challenge often traps users in inefficient trial-and-error loops and is exacerbated by the diverse expertise levels of users. We reframe this problem from passive instruction following to a Socratic collaboration paradigm, proposing an agent that actively probes for information to resolve its uncertainty about user intent. we name the proposed agent Nous, trained to acquire proficiency in this inquiry policy. The core mechanism of Nous is a training framework grounded in the first principles of information theory. Within this framework, we define the information gain from dialogue as an intrinsic reward signal, which is fundamentally equivalent to the reduction of Shannon entropy over a structured task space. This reward design enables us to avoid reliance on costly human preference annotations or external reward models. To validate our framework, we develop an automated simulation pipeline to generate a large-scale, preference-based dataset for the challenging task of scientific diagram generation. Comprehensive experiments, including ablations, subjective and objective evaluations, and tests across user expertise levels, demonstrate the effectiveness of our proposed framework. Nous achieves leading efficiency and output quality, while remaining robust to varying user expertise. Moreover, its design is domain-agnostic, and we show evidence of generalization beyond diagram generation. Experimental results prove that our work offers a principled, scalable, and adaptive paradigm for resolving uncertainty about user intent in complex human-AI collaboration.
From Pixels to Paths: A Multi-Agent Framework for Editable Scientific Illustration
Oct 31, 2025Scientific illustrations demand both high information density and post-editability. However, current generative models have two major limitations: Frist, image generation models output rasterized images lacking semantic structure, making it impossible to access, edit, or rearrange independent visual components in the images. Second, code-based generation methods (TikZ or SVG), although providing element-level control, force users into the cumbersome cycle of "writing-compiling-reviewing" and lack the intuitiveness of manipulation. Neither of these two approaches can well meet the needs for efficiency, intuitiveness, and iterative modification in scientific creation. To bridge this gap, we introduce VisPainter, a multi-agent framework for scientific illustration built upon the model context protocol. VisPainter orchestrates three specialized modules-a Manager, a Designer, and a Toolbox-to collaboratively produce diagrams compatible with standard vector graphics software. This modular, role-based design allows each element to be explicitly represented and manipulated, enabling true element-level control and any element can be added and modified later. To systematically evaluate the quality of scientific illustrations, we introduce VisBench, a benchmark with seven-dimensional evaluation metrics. It assesses high-information-density scientific illustrations from four aspects: content, layout, visual perception, and interaction cost. To this end, we conducted extensive ablation experiments to verify the rationality of our architecture and the reliability of our evaluation methods. Finally, we evaluated various vision-language models, presenting fair and credible model rankings along with detailed comparisons of their respective capabilities. Additionally, we isolated and quantified the impacts of role division, step control,and description on the quality of illustrations.
A High-Quality Dataset and Reliable Evaluation for Interleaved Image-Text Generation
Jun 11, 2025Recent advancements in Large Multimodal Models (LMMs) have significantly improved multimodal understanding and generation. However, these models still struggle to generate tightly interleaved image-text outputs, primarily due to the limited scale, quality and instructional richness of current training datasets. To address this, we introduce InterSyn, a large-scale multimodal dataset constructed using our Self-Evaluation with Iterative Refinement (SEIR) method. InterSyn features multi-turn, instruction-driven dialogues with tightly interleaved imagetext responses, providing rich object diversity and rigorous automated quality refinement, making it well-suited for training next-generation instruction-following LMMs. Furthermore, to address the lack of reliable evaluation tools capable of assessing interleaved multimodal outputs, we introduce SynJudge, an automatic evaluation model designed to quantitatively assess multimodal outputs along four dimensions: text content, image content, image quality, and image-text synergy. Experimental studies show that the SEIR method leads to substantially higher dataset quality compared to an otherwise identical process without refinement. Moreover, LMMs trained on InterSyn achieve uniform performance gains across all evaluation metrics, confirming InterSyn's utility for advancing multimodal systems.
ARMOR v0.1: Empowering Autoregressive Multimodal Understanding Model with Interleaved Multimodal Generation via Asymmetric Synergy
Mar 09, 2025



Unified models (UniMs) for multimodal understanding and generation have recently received much attention in the area of vision and language. Existing UniMs are designed to simultaneously learn both multimodal understanding and generation capabilities, demanding substantial computational resources, and often struggle to generate interleaved text-image. We present ARMOR, a resource-efficient and pure autoregressive framework that achieves both understanding and generation by fine-tuning existing multimodal large language models (MLLMs). Specifically, ARMOR extends existing MLLMs from three perspectives: (1) For model architecture, an asymmetric encoder-decoder architecture with a forward-switching mechanism is introduced to unify embedding space integrating textual and visual modalities for enabling natural text-image interleaved generation with minimal computational overhead. (2) For training data, a meticulously curated, high-quality interleaved dataset is collected for fine-tuning MLLMs. (3) For the training algorithm, we propose a ``what or how to generate" algorithm to empower existing MLLMs with multimodal generation capabilities while preserving their multimodal understanding capabilities, through three progressive training stages based on the collected dataset. Experimental results demonstrate that ARMOR upgrades existing MLLMs to UniMs with promising image generation capabilities, using limited training resources. Our code will be released soon at https://armor.github.io.
Modulating CNN Features with Pre-Trained ViT Representations for Open-Vocabulary Object Detection
Jan 28, 2025Owing to large-scale image-text contrastive training, pre-trained vision language model (VLM) like CLIP shows superior open-vocabulary recognition ability. Most existing open-vocabulary object detectors attempt to utilize the pre-trained VLM to attain generative representation. F-ViT uses the pre-trained visual encoder as the backbone network and freezes it during training. However, the frozen backbone doesn't benefit from the labeled data to strengthen the representation. Therefore, we propose a novel two-branch backbone network design, named as ViT-Feature-Modulated Multi-Scale Convolutional network (VMCNet). VMCNet consists of a trainable convolutional branch, a frozen pre-trained ViT branch and a feature modulation module. The trainable CNN branch could be optimized with labeled data while the frozen pre-trained ViT branch could keep the representation ability derived from large-scale pre-training. Then, the proposed feature modulation module could modulate the multi-scale CNN features with the representations from ViT branch. With the proposed mixed structure, detector is more likely to discover novel categories. Evaluated on two popular benchmarks, our method boosts the detection performance on novel category and outperforms the baseline. On OV-COCO, the proposed method achieves 44.3 AP$_{50}^{\mathrm{novel}}$ with ViT-B/16 and 48.5 AP$_{50}^{\mathrm{novel}}$ with ViT-L/14. On OV-LVIS, VMCNet with ViT-B/16 and ViT-L/14 reaches 27.8 and 38.4 mAP$_{r}$.
PSFHS Challenge Report: Pubic Symphysis and Fetal Head Segmentation from Intrapartum Ultrasound Images
Sep 17, 2024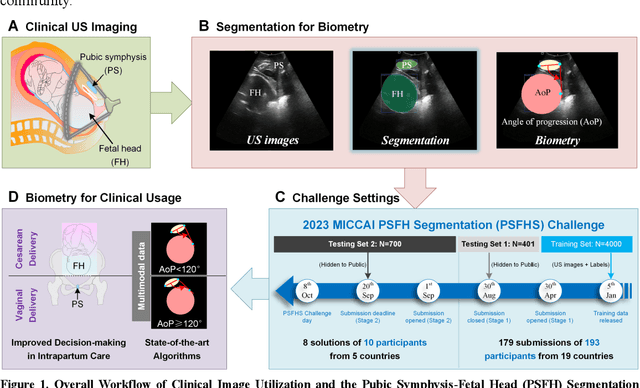
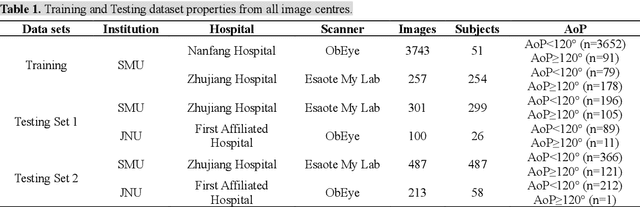
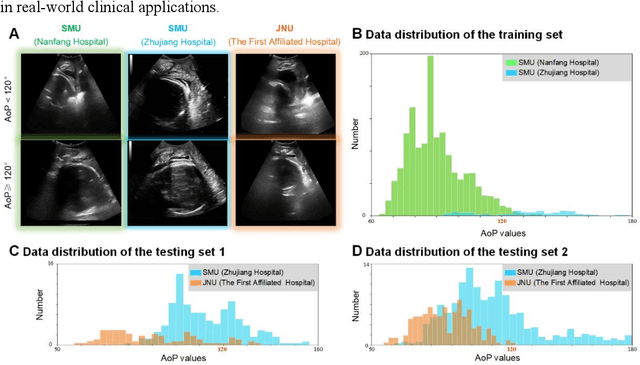

Segmentation of the fetal and maternal structures, particularly intrapartum ultrasound imaging as advocated by the International Society of Ultrasound in Obstetrics and Gynecology (ISUOG) for monitoring labor progression, is a crucial first step for quantitative diagnosis and clinical decision-making. This requires specialized analysis by obstetrics professionals, in a task that i) is highly time- and cost-consuming and ii) often yields inconsistent results. The utility of automatic segmentation algorithms for biometry has been proven, though existing results remain suboptimal. To push forward advancements in this area, the Grand Challenge on Pubic Symphysis-Fetal Head Segmentation (PSFHS) was held alongside the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023). This challenge aimed to enhance the development of automatic segmentation algorithms at an international scale, providing the largest dataset to date with 5,101 intrapartum ultrasound images collected from two ultrasound machines across three hospitals from two institutions. The scientific community's enthusiastic participation led to the selection of the top 8 out of 179 entries from 193 registrants in the initial phase to proceed to the competition's second stage. These algorithms have elevated the state-of-the-art in automatic PSFHS from intrapartum ultrasound images. A thorough analysis of the results pinpointed ongoing challenges in the field and outlined recommendations for future work. The top solutions and the complete dataset remain publicly available, fostering further advancements in automatic segmentation and biometry for intrapartum ultrasound imaging.
VGA: Vision GUI Assistant -- Minimizing Hallucinations through Image-Centric Fine-Tuning
Jun 20, 2024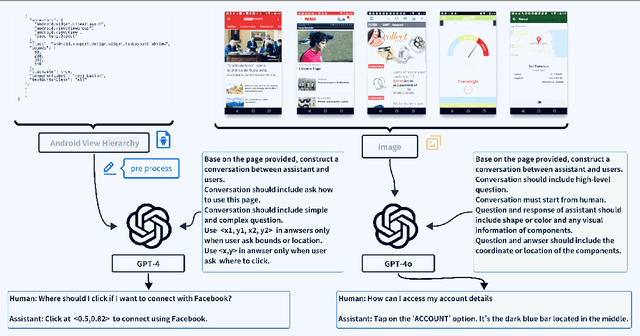
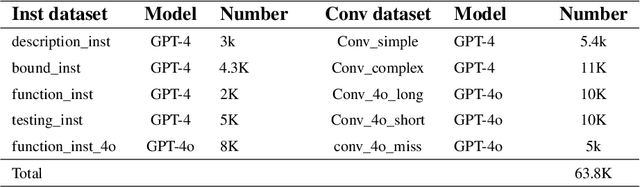

Recent advances in Large Vision-Language Models (LVLMs) have significantly improve performance in image comprehension tasks, such as formatted charts and rich-content images. Yet, Graphical User Interface (GUI) pose a greater challenge due to their structured format and detailed textual information. Existing LVLMs often overly depend on internal knowledge and neglect image content, resulting in hallucinations and incorrect responses in GUI comprehension.To address these issues, we introduce VGA, a fine-tuned model designed for comprehensive GUI understanding. Our model aims to enhance the interpretation of visual data of GUI and reduce hallucinations. We first construct a Vision Question Answering (VQA) dataset of 63.8k high-quality examples with our propose Referent Method, which ensures the model's responses are highly depend on visual content within the image. We then design a two-stage fine-tuning method called Foundation and Advanced Comprehension (FAC) to enhance both the model's ability to extract information from image content and alignment with human intent. Experiments show that our approach enhances the model's ability to extract information from images and achieves state-of-the-art results in GUI understanding tasks. Our dataset and fine-tuning script will be released soon.
Slightly Shift New Classes to Remember Old Classes for Video Class-Incremental Learning
Apr 01, 2024



Recent video class-incremental learning usually excessively pursues the accuracy of the newly seen classes and relies on memory sets to mitigate catastrophic forgetting of the old classes. However, limited storage only allows storing a few representative videos. So we propose SNRO, which slightly shifts the features of new classes to remember old classes. Specifically, SNRO contains Examples Sparse(ES) and Early Break(EB). ES decimates at a lower sample rate to build memory sets and uses interpolation to align those sparse frames in the future. By this, SNRO stores more examples under the same memory consumption and forces the model to focus on low-semantic features which are harder to be forgotten. EB terminates the training at a small epoch, preventing the model from overstretching into the high-semantic space of the current task. Experiments on UCF101, HMDB51, and UESTC-MMEA-CL datasets show that SNRO performs better than other approaches while consuming the same memory consumption.
BAAF: A Benchmark Attention Adaptive Framework for Medical Ultrasound Image Segmentation Tasks
Oct 02, 2023



The AI-based assisted diagnosis programs have been widely investigated on medical ultrasound images. Complex scenario of ultrasound image, in which the coupled interference of internal and external factors is severe, brings a unique challenge for localize the object region automatically and precisely in ultrasound images. In this study, we seek to propose a more general and robust Benchmark Attention Adaptive Framework (BAAF) to assist doctors segment or diagnose lesions and tissues in ultrasound images more quickly and accurately. Different from existing attention schemes, the BAAF consists of a parallel hybrid attention module (PHAM) and an adaptive calibration mechanism (ACM). Specifically, BAAF first coarsely calibrates the input features from the channel and spatial dimensions, and then adaptively selects more robust lesion or tissue characterizations from the coarse-calibrated feature maps. The design of BAAF further optimizes the "what" and "where" focus and selection problems in CNNs and seeks to improve the segmentation accuracy of lesions or tissues in medical ultrasound images. The method is evaluated on four medical ultrasound segmentation tasks, and the adequate experimental results demonstrate the remarkable performance improvement over existing state-of-the-art methods. In addition, the comparison with existing attention mechanisms also demonstrates the superiority of BAAF. This work provides the possibility for automated medical ultrasound assisted diagnosis and reduces reliance on human accuracy and precision.
Towards Continual Egocentric Activity Recognition: A Multi-modal Egocentric Activity Dataset for Continual Learning
Jan 26, 2023


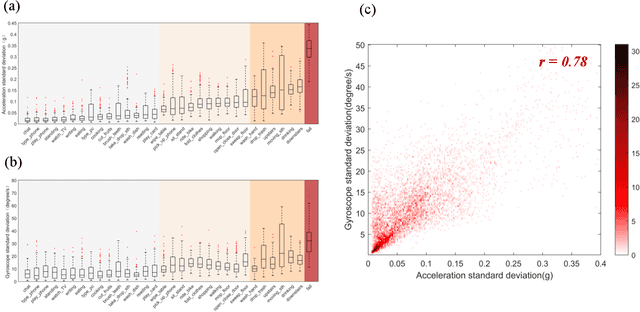
With the rapid development of wearable cameras, a massive collection of egocentric video for first-person visual perception becomes available. Using egocentric videos to predict first-person activity faces many challenges, including limited field of view, occlusions, and unstable motions. Observing that sensor data from wearable devices facilitates human activity recognition, multi-modal activity recognition is attracting increasing attention. However, the deficiency of related dataset hinders the development of multi-modal deep learning for egocentric activity recognition. Nowadays, deep learning in real world has led to a focus on continual learning that often suffers from catastrophic forgetting. But the catastrophic forgetting problem for egocentric activity recognition, especially in the context of multiple modalities, remains unexplored due to unavailability of dataset. In order to assist this research, we present a multi-modal egocentric activity dataset for continual learning named UESTC-MMEA-CL, which is collected by self-developed glasses integrating a first-person camera and wearable sensors. It contains synchronized data of videos, accelerometers, and gyroscopes, for 32 types of daily activities, performed by 10 participants. Its class types and scale are compared with other publicly available datasets. The statistical analysis of the sensor data is given to show the auxiliary effects for different behaviors. And results of egocentric activity recognition are reported when using separately, and jointly, three modalities: RGB, acceleration, and gyroscope, on a base network architecture. To explore the catastrophic forgetting in continual learning tasks, four baseline methods are extensively evaluated with different multi-modal combinations. We hope the UESTC-MMEA-CL can promote future studies on continual learning for first-person activity recognition in wearable applications.