 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Oracle Gap: Increment Vector Transformation for Class Incremental Learning
Sep 26, 2025Class Incremental Learning (CIL) aims to sequentially acquire knowledge of new classes without forgetting previously learned ones. Despite recent progress, current CIL methods still exhibit significant performance gaps compared to their oracle counterparts-models trained with full access to historical data. Inspired by recent insights on Linear Mode Connectivity (LMC), we revisit the geometric properties of oracle solutions in CIL and uncover a fundamental observation: these oracle solutions typically maintain low-loss linear connections to the optimum of previous tasks. Motivated by this finding, we propose Increment Vector Transformation (IVT), a novel plug-and-play framework designed to mitigate catastrophic forgetting during training. Rather than directly following CIL updates, IVT periodically teleports the model parameters to transformed solutions that preserve linear connectivity to previous task optimum. By maintaining low-loss along these connecting paths, IVT effectively ensures stable performance on previously learned tasks. The transformation is efficiently approximated using diagonal Fisher Information Matrices, making IVT suitable for both exemplar-free and exemplar-based scenarios, and compatible with various initialization strategies. Extensive experiments on CIFAR-100, FGVCAircraft, ImageNet-Subset, and ImageNet-Full demonstrate that IVT consistently enhances the performance of strong CIL baselines. Specifically, on CIFAR-100, IVT improves the last accuracy of the PASS baseline by +5.12% and reduces forgetting by 2.54%. For the CLIP-pre-trained SLCA baseline on FGVCAircraft, IVT yields gains of +14.93% in average accuracy and +21.95% in last accuracy. The code will be released.
DFR: A Decompose-Fuse-Reconstruct Framework for Multi-Modal Few-Shot Segmentation
Jul 22, 2025This paper presents DFR (Decompose, Fuse and Reconstruct), a novel framework that addresses the fundamental challenge of effectively utilizing multi-modal guidance in few-shot segmentation (FSS). While existing approaches primarily rely on visual support samples or textual descriptions, their single or dual-modal paradigms limit exploitation of rich perceptual information available in real-world scenarios. To overcome this limitation, the proposed approach leverages the Segment Anything Model (SAM) to systematically integrate visual, textual, and audio modalities for enhanced semantic understanding. The DFR framework introduces three key innovations: 1) Multi-modal Decompose: a hierarchical decomposition scheme that extracts visual region proposals via SAM, expands textual semantics into fine-grained descriptors, and processes audio features for contextual enrichment; 2) Multi-modal Contrastive Fuse: a fusion strategy employing contrastive learning to maintain consistency across visual, textual, and audio modalities while enabling dynamic semantic interactions between foreground and background features; 3) Dual-path Reconstruct: an adaptive integration mechanism combining semantic guidance from tri-modal fused tokens with geometric cues from multi-modal location priors. Extensive experiments across visual, textual, and audio modalities under both synthetic and real settings demonstrate DFR's substantial performance improvements over state-of-the-art methods.
CMP: A Composable Meta Prompt for SAM-Based Cross-Domain Few-Shot Segmentation
Jul 22, 2025Cross-Domain Few-Shot Segmentation (CD-FSS) remains challenging due to limited data and domain shifts. Recent foundation models like the Segment Anything Model (SAM) have shown remarkable zero-shot generalization capability in general segmentation tasks, making it a promising solution for few-shot scenarios. However, adapting SAM to CD-FSS faces two critical challenges: reliance on manual prompt and limited cross-domain ability. Therefore, we propose the Composable Meta-Prompt (CMP) framework that introduces three key modules: (i) the Reference Complement and Transformation (RCT) module for semantic expansion, (ii) the Composable Meta-Prompt Generation (CMPG) module for automated meta-prompt synthesis, and (iii) the Frequency-Aware Interaction (FAI) module for domain discrepancy mitigation. Evaluations across four cross-domain datasets demonstrate CMP's state-of-the-art performance, achieving 71.8\% and 74.5\% mIoU in 1-shot and 5-shot scenarios respectively.
MINGLE: Mixtures of Null-Space Gated Low-Rank Experts for Test-Time Continual Model Merging
May 17, 2025Continual model merging integrates independently fine-tuned models sequentially without access to original training data, providing a scalable and efficient solution to continual learning. However, current methods still face critical challenges, notably parameter interference among tasks and limited adaptability to evolving test distributions. The former causes catastrophic forgetting of integrated tasks, while the latter hinders effective adaptation to new tasks. To address these, we propose MINGLE, a novel framework for test-time continual model merging, which leverages test-time adaptation using a small set of unlabeled test samples from the current task to dynamically guide the merging process. MINGLE employs a mixture-of-experts architecture composed of parameter-efficient, low-rank experts, enabling efficient adaptation and improving robustness to distribution shifts. To mitigate catastrophic forgetting, we propose Null-Space Constrained Gating, which restricts gating updates to subspaces orthogonal to prior task representations. This suppresses activations on old task inputs and preserves model behavior on past tasks. To further balance stability and adaptability, we design an Adaptive Relaxation Strategy, which dynamically adjusts the constraint strength based on interference signals captured during test-time adaptation. Extensive experiments on standard continual merging benchmarks demonstrate that MINGLE achieves robust generalization, reduces forgetting significantly, and consistently surpasses previous state-of-the-art methods by 7-9\% on average across diverse task orders.
CMaP-SAM: Contraction Mapping Prior for SAM-driven Few-shot Segmentation
Apr 07, 2025



Few-shot segmentation (FSS) aims to segment new classes using few annotated images. While recent FSS methods have shown considerable improvements by leveraging Segment Anything Model (SAM), they face two critical limitations: insufficient utilization of structural correlations in query images, and significant information loss when converting continuous position priors to discrete point prompts. To address these challenges, we propose CMaP-SAM, a novel framework that introduces contraction mapping theory to optimize position priors for SAM-driven few-shot segmentation. CMaP-SAM consists of three key components: (1) a contraction mapping module that formulates position prior optimization as a Banach contraction mapping with convergence guarantees. This module iteratively refines position priors through pixel-wise structural similarity, generating a converged prior that preserves both semantic guidance from reference images and structural correlations in query images; (2) an adaptive distribution alignment module bridging continuous priors with SAM's binary mask prompt encoder; and (3) a foreground-background decoupled refinement architecture producing accurate final segmentation masks. Extensive experiments demonstrate CMaP-SAM's effectiveness, achieving state-of-the-art performance with 71.1 mIoU on PASCAL-$5^i$ and 56.1 on COCO-$20^i$ datasets.
HarmonyIQA: Pioneering Benchmark and Model for Image Harmonization Quality Assessment
Jan 02, 2025



Image composition involves extracting a foreground object from one image and pasting it into another image through Image harmonization algorithms (IHAs), which aim to adjust the appearance of the foreground object to better match the background. Existing image quality assessment (IQA) methods may fail to align with human visual preference on image harmonization due to the insensitivity to minor color or light inconsistency. To address the issue and facilitate the advancement of IHAs, we introduce the first Image Quality Assessment Database for image Harmony evaluation (HarmonyIQAD), which consists of 1,350 harmonized images generated by 9 different IHAs, and the corresponding human visual preference scores. Based on this database, we propose a Harmony Image Quality Assessment (HarmonyIQA), to predict human visual preference for harmonized images. Extensive experiments show that HarmonyIQA achieves state-of-the-art performance on human visual preference evaluation for harmonized images, and also achieves competing results on traditional IQA tasks. Furthermore, cross-dataset evaluation also shows that HarmonyIQA exhibits better generalization ability than self-supervised learning-based IQA methods. Both HarmonyIQAD and HarmonyIQA will be made publicly available upon paper publication.
ARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Oct 16, 2024



The application of activity recognition in the ``AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
Cognition Transferring and Decoupling for Text-supervised Egocentric Semantic Segmentation
Oct 02, 2024
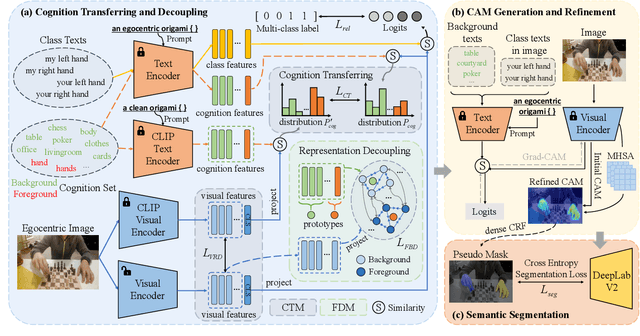
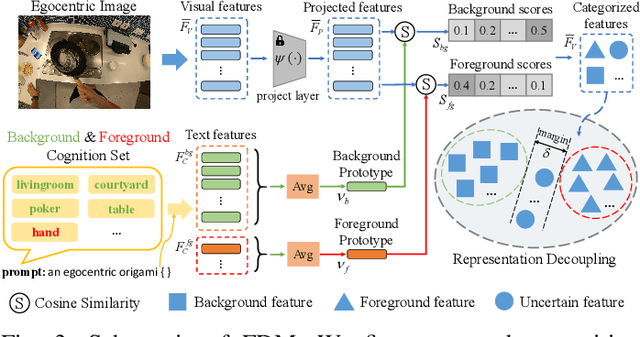
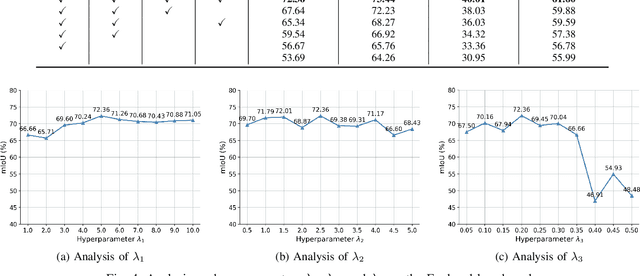
In this paper, we explore a novel Text-supervised Egocentic Semantic Segmentation (TESS) task that aims to assign pixel-level categories to egocentric images weakly supervised by texts from image-level labels. In this task with prospective potential, the egocentric scenes contain dense wearer-object relations and inter-object interference. However, most recent third-view methods leverage the frozen Contrastive Language-Image Pre-training (CLIP) model, which is pre-trained on the semantic-oriented third-view data and lapses in the egocentric view due to the ``relation insensitive" problem. Hence, we propose a Cognition Transferring and Decoupling Network (CTDN) that first learns the egocentric wearer-object relations via correlating the image and text. Besides, a Cognition Transferring Module (CTM) is developed to distill the cognitive knowledge from the large-scale pre-trained model to our model for recognizing egocentric objects with various semantics. Based on the transferred cognition, the Foreground-background Decoupling Module (FDM) disentangles the visual representations to explicitly discriminate the foreground and background regions to mitigate false activation areas caused by foreground-background interferential objects during egocentric relation learning. Extensive experiments on four TESS benchmarks demonstrate the effectiveness of our approach, which outperforms many recent related methods by a large margin. Code will be available at https://github.com/ZhaofengSHI/CTDN.
Few-Shot Continual Learning for Activity Recognition in Classroom Surveillance Images
Sep 05, 2024
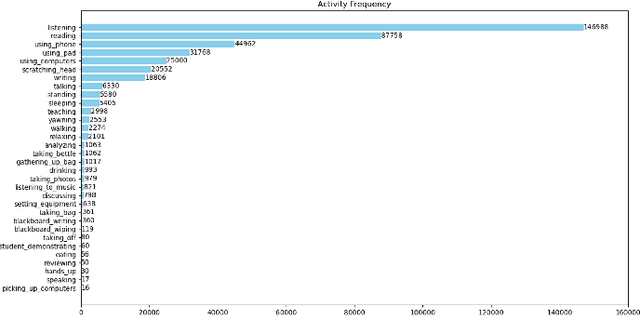
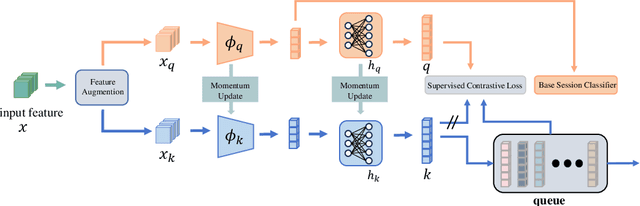
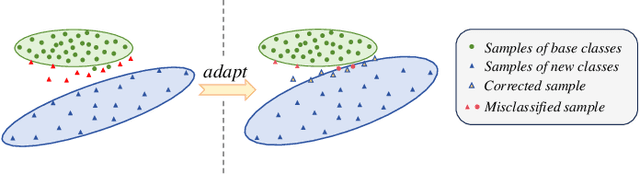
The application of activity recognition in the "AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. In real classroom settings, normal teaching activities such as reading, account for a large proportion of samples, while rare non-teaching activities such as eating, continue to appear. This requires a model that can learn non-teaching activities from few samples without forgetting the normal teaching activities, which necessitates fewshot continual learning (FSCL) capability. To address this gap, we constructed a continual learning dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition in Classroom). The dataset has advantages such as multiple perspectives, a wide variety of activities, and real-world scenarios, but it also presents challenges like similar activities and imbalanced sample distribution. To overcome these challenges, we designed a few-shot continual learning method that combines supervised contrastive learning (SCL) and an adaptive covariance classifier (ACC). During the base phase, we proposed a SCL approach based on feature augmentation to enhance the model's generalization ability. In the incremental phase, we employed an ACC to more accurately describe the distribution of new classes. Experimental results demonstrate that our method outperforms other existing methods on the ARIC dataset.
Distribution-Level Memory Recall for Continual Learning: Preserving Knowledge and Avoiding Confusion
Aug 04, 2024



Continual Learning (CL) aims to enable Deep Neural Networks (DNNs) to learn new data without forgetting previously learned knowledge. The key to achieving this goal is to avoid confusion at the feature level, i.e., avoiding confusion within old tasks and between new and old tasks. Previous prototype-based CL methods generate pseudo features for old knowledge replay by adding Gaussian noise to the centroids of old classes. However, the distribution in the feature space exhibits anisotropy during the incremental process, which prevents the pseudo features from faithfully reproducing the distribution of old knowledge in the feature space, leading to confusion in classification boundaries within old tasks. To address this issue, we propose the Distribution-Level Memory Recall (DMR) method, which uses a Gaussian mixture model to precisely fit the feature distribution of old knowledge at the distribution level and generate pseudo features in the next stage. Furthermore, resistance to confusion at the distribution level is also crucial for multimodal learning, as the problem of multimodal imbalance results in significant differences in feature responses between different modalities, exacerbating confusion within old tasks in prototype-based CL methods. Therefore, we mitigate the multi-modal imbalance problem by using the Inter-modal Guidance and Intra-modal Mining (IGIM) method to guide weaker modalities with prior information from dominant modalities and further explore useful information within modalities. For the second key, We propose the Confusion Index to quantitatively describe a model's ability to distinguish between new and old tasks, and we use the Incremental Mixup Feature Enhancement (IMFE) method to enhance pseudo features with new sample features, alleviating classification confusion between new and old knowledge.