 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Oct 16, 2024



The application of activity recognition in the ``AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
Few-Shot Continual Learning for Activity Recognition in Classroom Surveillance Images
Sep 05, 2024
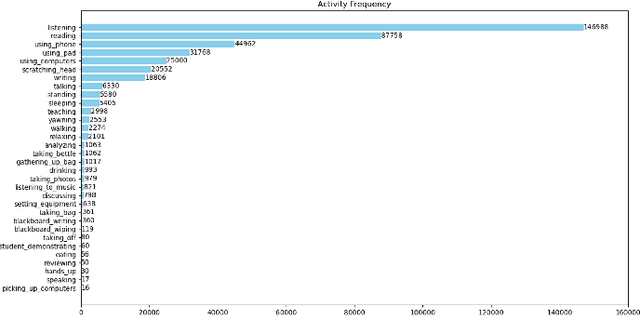
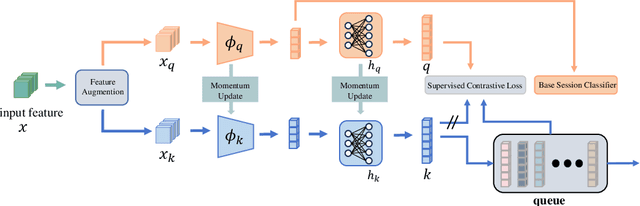
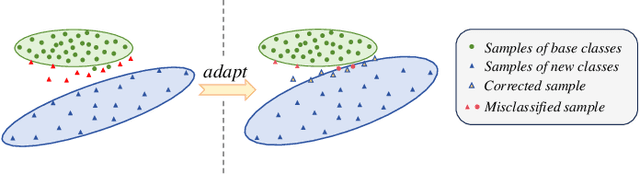
The application of activity recognition in the "AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. In real classroom settings, normal teaching activities such as reading, account for a large proportion of samples, while rare non-teaching activities such as eating, continue to appear. This requires a model that can learn non-teaching activities from few samples without forgetting the normal teaching activities, which necessitates fewshot continual learning (FSCL) capability. To address this gap, we constructed a continual learning dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition in Classroom). The dataset has advantages such as multiple perspectives, a wide variety of activities, and real-world scenarios, but it also presents challenges like similar activities and imbalanced sample distribution. To overcome these challenges, we designed a few-shot continual learning method that combines supervised contrastive learning (SCL) and an adaptive covariance classifier (ACC). During the base phase, we proposed a SCL approach based on feature augmentation to enhance the model's generalization ability. In the incremental phase, we employed an ACC to more accurately describe the distribution of new classes. Experimental results demonstrate that our method outperforms other existing methods on the ARIC dataset.
Distribution-Level Memory Recall for Continual Learning: Preserving Knowledge and Avoiding Confusion
Aug 04, 2024



Continual Learning (CL) aims to enable Deep Neural Networks (DNNs) to learn new data without forgetting previously learned knowledge. The key to achieving this goal is to avoid confusion at the feature level, i.e., avoiding confusion within old tasks and between new and old tasks. Previous prototype-based CL methods generate pseudo features for old knowledge replay by adding Gaussian noise to the centroids of old classes. However, the distribution in the feature space exhibits anisotropy during the incremental process, which prevents the pseudo features from faithfully reproducing the distribution of old knowledge in the feature space, leading to confusion in classification boundaries within old tasks. To address this issue, we propose the Distribution-Level Memory Recall (DMR) method, which uses a Gaussian mixture model to precisely fit the feature distribution of old knowledge at the distribution level and generate pseudo features in the next stage. Furthermore, resistance to confusion at the distribution level is also crucial for multimodal learning, as the problem of multimodal imbalance results in significant differences in feature responses between different modalities, exacerbating confusion within old tasks in prototype-based CL methods. Therefore, we mitigate the multi-modal imbalance problem by using the Inter-modal Guidance and Intra-modal Mining (IGIM) method to guide weaker modalities with prior information from dominant modalities and further explore useful information within modalities. For the second key, We propose the Confusion Index to quantitatively describe a model's ability to distinguish between new and old tasks, and we use the Incremental Mixup Feature Enhancement (IMFE) method to enhance pseudo features with new sample features, alleviating classification confusion between new and old knowledge.
Towards Continual Egocentric Activity Recognition: A Multi-modal Egocentric Activity Dataset for Continual Learning
Jan 26, 2023


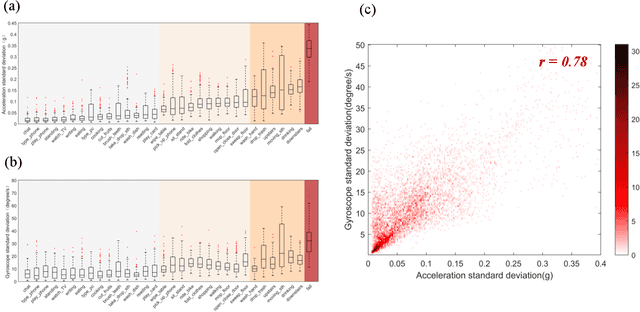
With the rapid development of wearable cameras, a massive collection of egocentric video for first-person visual perception becomes available. Using egocentric videos to predict first-person activity faces many challenges, including limited field of view, occlusions, and unstable motions. Observing that sensor data from wearable devices facilitates human activity recognition, multi-modal activity recognition is attracting increasing attention. However, the deficiency of related dataset hinders the development of multi-modal deep learning for egocentric activity recognition. Nowadays, deep learning in real world has led to a focus on continual learning that often suffers from catastrophic forgetting. But the catastrophic forgetting problem for egocentric activity recognition, especially in the context of multiple modalities, remains unexplored due to unavailability of dataset. In order to assist this research, we present a multi-modal egocentric activity dataset for continual learning named UESTC-MMEA-CL, which is collected by self-developed glasses integrating a first-person camera and wearable sensors. It contains synchronized data of videos, accelerometers, and gyroscopes, for 32 types of daily activities, performed by 10 participants. Its class types and scale are compared with other publicly available datasets. The statistical analysis of the sensor data is given to show the auxiliary effects for different behaviors. And results of egocentric activity recognition are reported when using separately, and jointly, three modalities: RGB, acceleration, and gyroscope, on a base network architecture. To explore the catastrophic forgetting in continual learning tasks, four baseline methods are extensively evaluated with different multi-modal combinations. We hope the UESTC-MMEA-CL can promote future studies on continual learning for first-person activity recognition in wearable applications.