 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Trends in Egocentric Vision: A Survey
Mar 19, 2025With the rapid development of artificial intelligence technologies and wearable devices, egocentric vision understanding has emerged as a new and challenging research direction, gradually attracting widespread attention from both academia and industry. Egocentric vision captures visual and multimodal data through cameras or sensors worn on the human body, offering a unique perspective that simulates human visual experiences. This paper provides a comprehensive survey of the research on egocentric vision understanding, systematically analyzing the components of egocentric scenes and categorizing the tasks into four main areas: subject understanding, object understanding, environment understanding, and hybrid understanding. We explore in detail the sub-tasks within each category. We also summarize the main challenges and trends currently existing in the field. Furthermore, this paper presents an overview of high-quality egocentric vision datasets, offering valuable resources for future research. By summarizing the latest advancements, we anticipate the broad applications of egocentric vision technologies in fields such as augmented reality, virtual reality, and embodied intelligence, and propose future research directions based on the latest developments in the field.
EgoMe: Follow Me via Egocentric View in Real World
Jan 31, 2025When interacting with the real world, human often take the egocentric (first-person) view as a benchmark, naturally transferring behaviors observed from a exocentric (third-person) view to their own. This cognitive theory provides a foundation for researching how robots can more effectively imitate human behavior. However, current research either employs multiple cameras with different views focusing on the same individual's behavior simultaneously or encounters unpair ego-exo view scenarios, there is no effort to fully exploit human cognitive behavior in the real world. To fill this gap, in this paper, we introduce a novel large-scale egocentric dataset, called EgoMe, which towards following the process of human imitation learning via egocentric view in the real world. Our dataset includes 7902 pairs of videos (15804 videos) for diverse daily behaviors in real-world scenarios. For a pair of videos, one video captures a exocentric view of the imitator observing the demonstrator's actions, while the other captures a egocentric view of the imitator subsequently following those actions. Notably, our dataset also contain exo-ego eye gaze, angular velocity, acceleration, magnetic strength and other sensor multi-modal data for assisting in establishing correlations between observing and following process. In addition, we also propose eight challenging benchmark tasks for fully leveraging this data resource and promoting the research of robot imitation learning ability. Extensive statistical analysis demonstrates significant advantages compared to existing datasets. The proposed EgoMe dataset and benchmark will be released soon.
ARIC: An Activity Recognition Dataset in Classroom Surveillance Images
Oct 16, 2024



The application of activity recognition in the ``AI + Education" field is gaining increasing attention. However, current work mainly focuses on the recognition of activities in manually captured videos and a limited number of activity types, with little attention given to recognizing activities in surveillance images from real classrooms. Activity recognition in classroom surveillance images faces multiple challenges, such as class imbalance and high activity similarity. To address this gap, we constructed a novel multimodal dataset focused on classroom surveillance image activity recognition called ARIC (Activity Recognition In Classroom). The ARIC dataset has advantages of multiple perspectives, 32 activity categories, three modalities, and real-world classroom scenarios. In addition to the general activity recognition tasks, we also provide settings for continual learning and few-shot continual learning. We hope that the ARIC dataset can act as a facilitator for future analysis and research for open teaching scenarios. You can download preliminary data from https://ivipclab.github.io/publication_ARIC/ARIC.
Cognition Transferring and Decoupling for Text-supervised Egocentric Semantic Segmentation
Oct 02, 2024
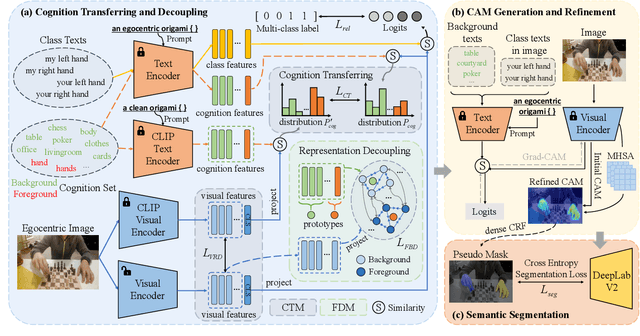
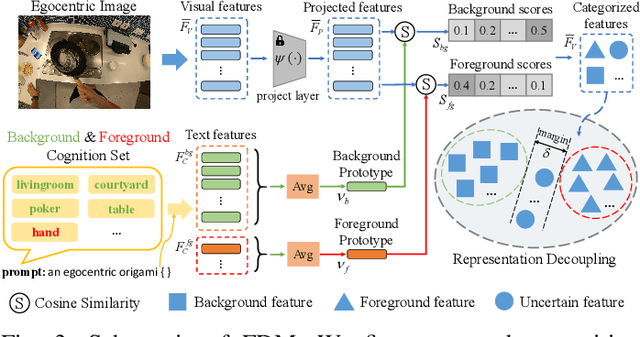
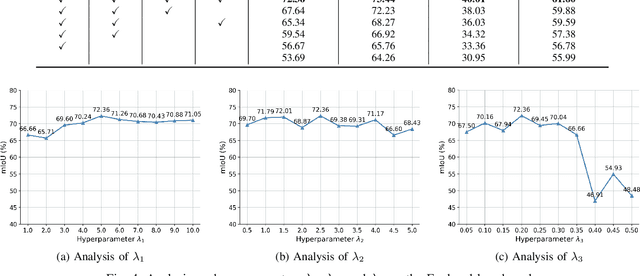
In this paper, we explore a novel Text-supervised Egocentic Semantic Segmentation (TESS) task that aims to assign pixel-level categories to egocentric images weakly supervised by texts from image-level labels. In this task with prospective potential, the egocentric scenes contain dense wearer-object relations and inter-object interference. However, most recent third-view methods leverage the frozen Contrastive Language-Image Pre-training (CLIP) model, which is pre-trained on the semantic-oriented third-view data and lapses in the egocentric view due to the ``relation insensitive" problem. Hence, we propose a Cognition Transferring and Decoupling Network (CTDN) that first learns the egocentric wearer-object relations via correlating the image and text. Besides, a Cognition Transferring Module (CTM) is developed to distill the cognitive knowledge from the large-scale pre-trained model to our model for recognizing egocentric objects with various semantics. Based on the transferred cognition, the Foreground-background Decoupling Module (FDM) disentangles the visual representations to explicitly discriminate the foreground and background regions to mitigate false activation areas caused by foreground-background interferential objects during egocentric relation learning. Extensive experiments on four TESS benchmarks demonstrate the effectiveness of our approach, which outperforms many recent related methods by a large margin. Code will be available at https://github.com/ZhaofengSHI/CTDN.
Distribution-Level Memory Recall for Continual Learning: Preserving Knowledge and Avoiding Confusion
Aug 04, 2024



Continual Learning (CL) aims to enable Deep Neural Networks (DNNs) to learn new data without forgetting previously learned knowledge. The key to achieving this goal is to avoid confusion at the feature level, i.e., avoiding confusion within old tasks and between new and old tasks. Previous prototype-based CL methods generate pseudo features for old knowledge replay by adding Gaussian noise to the centroids of old classes. However, the distribution in the feature space exhibits anisotropy during the incremental process, which prevents the pseudo features from faithfully reproducing the distribution of old knowledge in the feature space, leading to confusion in classification boundaries within old tasks. To address this issue, we propose the Distribution-Level Memory Recall (DMR) method, which uses a Gaussian mixture model to precisely fit the feature distribution of old knowledge at the distribution level and generate pseudo features in the next stage. Furthermore, resistance to confusion at the distribution level is also crucial for multimodal learning, as the problem of multimodal imbalance results in significant differences in feature responses between different modalities, exacerbating confusion within old tasks in prototype-based CL methods. Therefore, we mitigate the multi-modal imbalance problem by using the Inter-modal Guidance and Intra-modal Mining (IGIM) method to guide weaker modalities with prior information from dominant modalities and further explore useful information within modalities. For the second key, We propose the Confusion Index to quantitatively describe a model's ability to distinguish between new and old tasks, and we use the Incremental Mixup Feature Enhancement (IMFE) method to enhance pseudo features with new sample features, alleviating classification confusion between new and old knowledge.
MCF-VC: Mitigate Catastrophic Forgetting in Class-Incremental Learning for Multimodal Video Captioning
Feb 27, 2024



To address the problem of catastrophic forgetting due to the invisibility of old categories in sequential input, existing work based on relatively simple categorization tasks has made some progress. In contrast, video captioning is a more complex task in multimodal scenario, which has not been explored in the field of incremental learning. After identifying this stability-plasticity problem when analyzing video with sequential input, we originally propose a method to Mitigate Catastrophic Forgetting in class-incremental learning for multimodal Video Captioning (MCF-VC). As for effectively maintaining good performance on old tasks at the macro level, we design Fine-grained Sensitivity Selection (FgSS) based on the Mask of Linear's Parameters and Fisher Sensitivity to pick useful knowledge from old tasks. Further, in order to better constrain the knowledge characteristics of old and new tasks at the specific feature level, we have created the Two-stage Knowledge Distillation (TsKD), which is able to learn the new task well while weighing the old task. Specifically, we design two distillation losses, which constrain the cross modal semantic information of semantic attention feature map and the textual information of the final outputs respectively, so that the inter-model and intra-model stylized knowledge of the old class is retained while learning the new class. In order to illustrate the ability of our model to resist forgetting, we designed a metric CIDER_t to detect the stage forgetting rate. Our experiments on the public dataset MSR-VTT show that the proposed method significantly resists the forgetting of previous tasks without replaying old samples, and performs well on the new task.
GRSDet: Learning to Generate Local Reverse Samples for Few-shot Object Detection
Dec 29, 2023



Few-shot object detection (FSOD) aims to achieve object detection only using a few novel class training data. Most of the existing methods usually adopt a transfer-learning strategy to construct the novel class distribution by transferring the base class knowledge. However, this direct way easily results in confusion between the novel class and other similar categories in the decision space. To address the problem, we propose generating local reverse samples (LRSamples) in Prototype Reference Frames to adaptively adjust the center position and boundary range of the novel class distribution to learn more discriminative novel class samples for FSOD. Firstly, we propose a Center Calibration Variance Augmentation (CCVA) module, which contains the selection rule of LRSamples, the generator of LRSamples, and augmentation on the calibrated distribution centers. Specifically, we design an intra-class feature converter (IFC) as the generator of CCVA to learn the selecting rule. By transferring the knowledge of IFC from the base training to fine-tuning, the IFC generates plentiful novel samples to calibrate the novel class distribution. Moreover, we propose a Feature Density Boundary Optimization (FDBO) module to adaptively adjust the importance of samples depending on their distance from the decision boundary. It can emphasize the importance of the high-density area of the similar class (closer decision boundary area) and reduce the weight of the low-density area of the similar class (farther decision boundary area), thus optimizing a clearer decision boundary for each category. We conduct extensive experiments to demonstrate the effectiveness of our proposed method. Our method achieves consistent improvement on the Pascal VOC and MS COCO datasets based on DeFRCN and MFDC baselines.
RefCrowd: Grounding the Target in Crowd with Referring Expressions
Jun 16, 2022

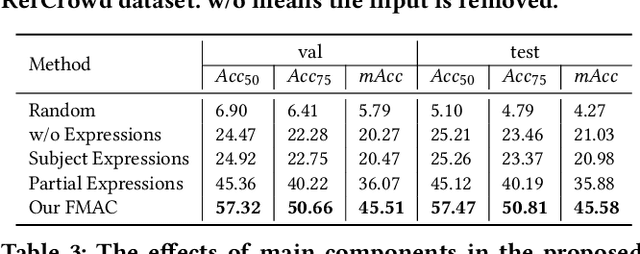
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.