 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognition Transferring and Decoupling for Text-supervised Egocentric Semantic Segmentation
Paper and Code

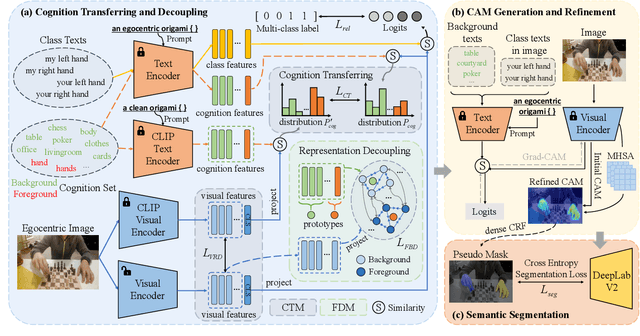
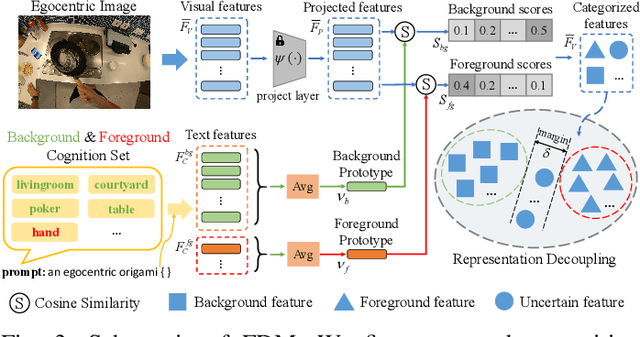
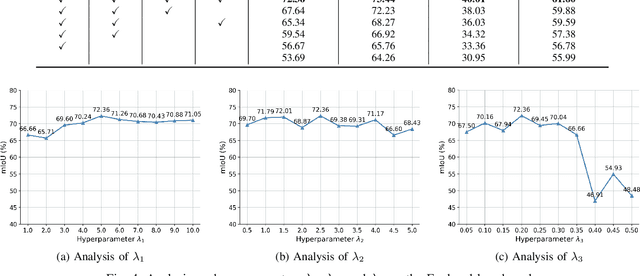
In this paper, we explore a novel Text-supervised Egocentic Semantic Segmentation (TESS) task that aims to assign pixel-level categories to egocentric images weakly supervised by texts from image-level labels. In this task with prospective potential, the egocentric scenes contain dense wearer-object relations and inter-object interference. However, most recent third-view methods leverage the frozen Contrastive Language-Image Pre-training (CLIP) model, which is pre-trained on the semantic-oriented third-view data and lapses in the egocentric view due to the ``relation insensitive" problem. Hence, we propose a Cognition Transferring and Decoupling Network (CTDN) that first learns the egocentric wearer-object relations via correlating the image and text. Besides, a Cognition Transferring Module (CTM) is developed to distill the cognitive knowledge from the large-scale pre-trained model to our model for recognizing egocentric objects with various semantics. Based on the transferred cognition, the Foreground-background Decoupling Module (FDM) disentangles the visual representations to explicitly discriminate the foreground and background regions to mitigate false activation areas caused by foreground-background interferential objects during egocentric relation learning. Extensive experiments on four TESS benchmarks demonstrate the effectiveness of our approach, which outperforms many recent related methods by a large margin. Code will be available at https://github.com/ZhaofengSHI/CTDN.