 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Ego-Exo-centric Adaptation for Action Anticipation via Multi-Label Prototype Growing and Dual-Clue Consistency
Mar 10, 2026Efficient adaptation between Egocentric (Ego) and Exocentric (Exo) views is crucial for applications such as human-robot cooperation. However, the success of most existing Ego-Exo adaptation methods relies heavily on target-view data for training, thereby increasing computational and data collection costs. In this paper, we make the first exploration of a Test-time Ego-Exo Adaptation for Action Anticipation (TE$^{2}$A$^{3}$) task, which aims to adjust the source-view-trained model online during test time to anticipate target-view actions. It is challenging for existing Test-Time Adaptation (TTA) methods to address this task due to the multi-action candidates and significant temporal-spatial inter-view gap. Hence, we propose a novel Dual-Clue enhanced Prototype Growing Network (DCPGN), which accumulates multi-label knowledge and integrates cross-modality clues for effective test-time Ego-Exo adaptation and action anticipation. Specifically, we propose a Multi-Label Prototype Growing Module (ML-PGM) to balance multiple positive classes via multi-label assignment and confidence-based reweighting for class-wise memory banks, which are updated by an entropy priority queue strategy. Then, the Dual-Clue Consistency Module (DCCM) introduces a lightweight narrator to generate textual clues indicating action progressions, which complement the visual clues containing various objects. Moreover, we constrain the inferred textual and visual logits to construct dual-clue consistency for temporally and spatially bridging Ego and Exo views. Extensive experiments on the newly proposed EgoMe-anti and the existing EgoExoLearn benchmarks show the effectiveness of our method, which outperforms related state-of-the-art methods by a large margin. Code is available at \href{https://github.com/ZhaofengSHI/DCPGN}{https://github.com/ZhaofengSHI/DCPGN}.
EgoMe: Follow Me via Egocentric View in Real World
Jan 31, 2025When interacting with the real world, human often take the egocentric (first-person) view as a benchmark, naturally transferring behaviors observed from a exocentric (third-person) view to their own. This cognitive theory provides a foundation for researching how robots can more effectively imitate human behavior. However, current research either employs multiple cameras with different views focusing on the same individual's behavior simultaneously or encounters unpair ego-exo view scenarios, there is no effort to fully exploit human cognitive behavior in the real world. To fill this gap, in this paper, we introduce a novel large-scale egocentric dataset, called EgoMe, which towards following the process of human imitation learning via egocentric view in the real world. Our dataset includes 7902 pairs of videos (15804 videos) for diverse daily behaviors in real-world scenarios. For a pair of videos, one video captures a exocentric view of the imitator observing the demonstrator's actions, while the other captures a egocentric view of the imitator subsequently following those actions. Notably, our dataset also contain exo-ego eye gaze, angular velocity, acceleration, magnetic strength and other sensor multi-modal data for assisting in establishing correlations between observing and following process. In addition, we also propose eight challenging benchmark tasks for fully leveraging this data resource and promoting the research of robot imitation learning ability. Extensive statistical analysis demonstrates significant advantages compared to existing datasets. The proposed EgoMe dataset and benchmark will be released soon.
Cognition Transferring and Decoupling for Text-supervised Egocentric Semantic Segmentation
Oct 02, 2024
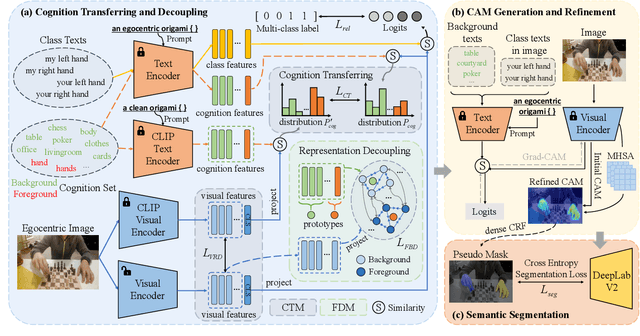
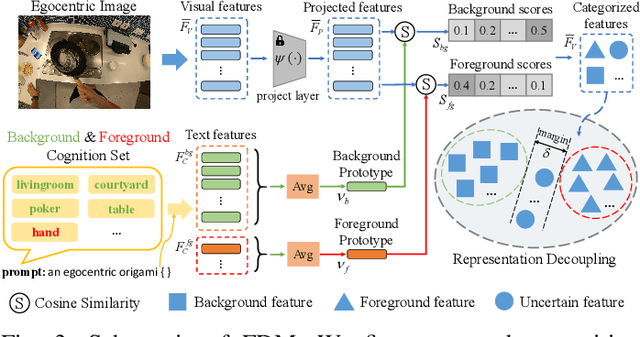
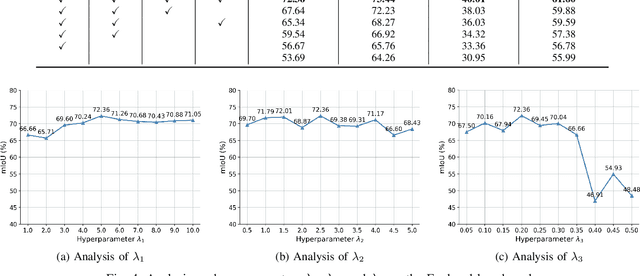
In this paper, we explore a novel Text-supervised Egocentic Semantic Segmentation (TESS) task that aims to assign pixel-level categories to egocentric images weakly supervised by texts from image-level labels. In this task with prospective potential, the egocentric scenes contain dense wearer-object relations and inter-object interference. However, most recent third-view methods leverage the frozen Contrastive Language-Image Pre-training (CLIP) model, which is pre-trained on the semantic-oriented third-view data and lapses in the egocentric view due to the ``relation insensitive" problem. Hence, we propose a Cognition Transferring and Decoupling Network (CTDN) that first learns the egocentric wearer-object relations via correlating the image and text. Besides, a Cognition Transferring Module (CTM) is developed to distill the cognitive knowledge from the large-scale pre-trained model to our model for recognizing egocentric objects with various semantics. Based on the transferred cognition, the Foreground-background Decoupling Module (FDM) disentangles the visual representations to explicitly discriminate the foreground and background regions to mitigate false activation areas caused by foreground-background interferential objects during egocentric relation learning. Extensive experiments on four TESS benchmarks demonstrate the effectiveness of our approach, which outperforms many recent related methods by a large margin. Code will be available at https://github.com/ZhaofengSHI/CTDN.
Cross-modal Cognitive Consensus guided Audio-Visual Segmentation
Oct 10, 2023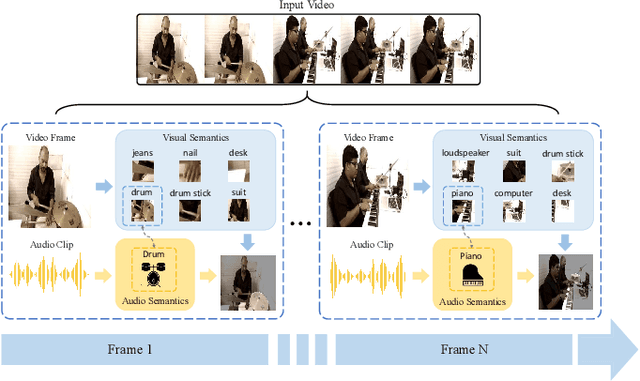
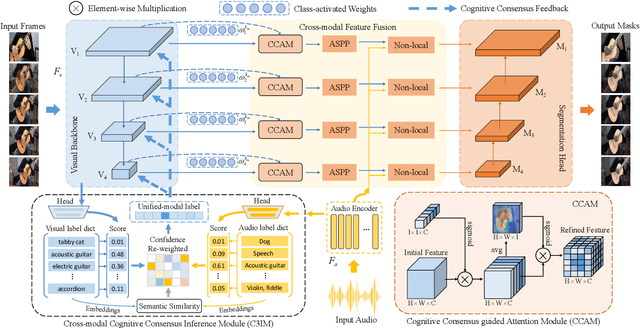
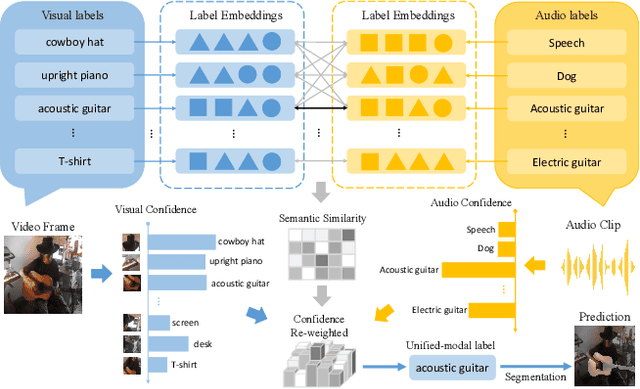
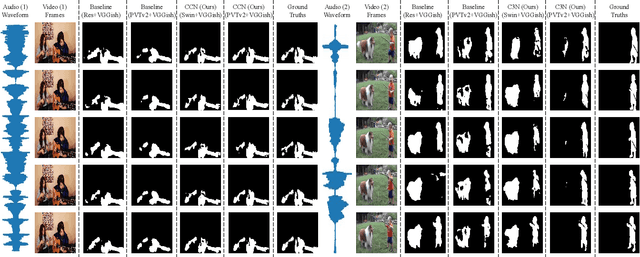
Audio-Visual Segmentation (AVS) aims to extract the sounding object from a video frame, which is represented by a pixel-wise segmentation mask. The pioneering work conducts this task through dense feature-level audio-visual interaction, which ignores the dimension gap between different modalities. More specifically, the audio clip could only provide a \textit{Global} semantic label in each sequence, but the video frame covers multiple semantic objects across different \textit{Local} regions. In this paper, we propose a Cross-modal Cognitive Consensus guided Network (C3N) to align the audio-visual semantics from the global dimension and progressively inject them into the local regions via an attention mechanism. Firstly, a Cross-modal Cognitive Consensus Inference Module (C3IM) is developed to extract a unified-modal label by integrating audio/visual classification confidence and similarities of modality-specific label embeddings. Then, we feed the unified-modal label back to the visual backbone as the explicit semantic-level guidance via a Cognitive Consensus guided Attention Module (CCAM), which highlights the local features corresponding to the interested object. Extensive experiments on the Single Sound Source Segmentation (S4) setting and Multiple Sound Source Segmentation (MS3) setting of the AVSBench dataset demonstrate the effectiveness of the proposed method, which achieves state-of-the-art performance.
A Survey on Audio Synthesis and Audio-Visual Multimodal Processing
Aug 01, 2021
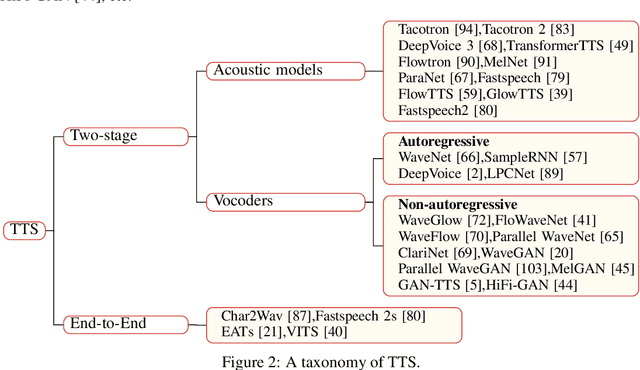
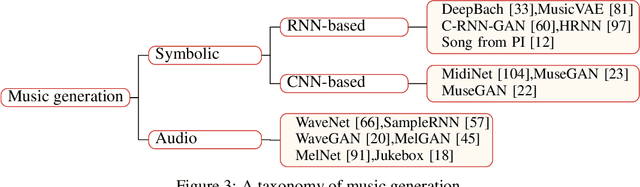
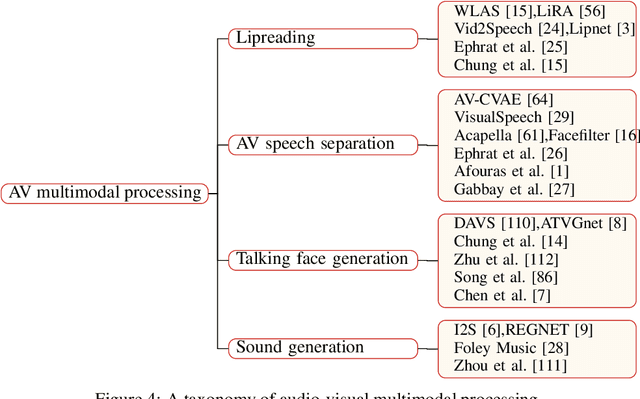
With the development of deep learning and artificial intelligence, audio synthesis has a pivotal role in the area of machine learning and shows strong applicability in the industry. Meanwhile, significant efforts have been dedicated by researchers to handle multimodal tasks at present such as audio-visual multimodal processing. In this paper, we conduct a survey on audio synthesis and audio-visual multimodal processing, which helps understand current research and future trends. This review focuses on text to speech(TTS), music generation and some tasks that combine visual and acoustic information. The corresponding technical methods are comprehensively classified and introduced, and their future development trends are prospected. This survey can provide some guidance for researchers who are interested in the areas like audio synthesis and audio-visual multimodal processing.