 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Enhancing Representation Learning in Federated Multi-Task Settings
Feb 02, 2026Federated multi-task learning (FMTL) seeks to collaboratively train customized models for users with different tasks while preserving data privacy. Most existing approaches assume model congruity (i.e., the use of fully or partially homogeneous models) across users, which limits their applicability in realistic settings. To overcome this limitation, we aim to learn a shared representation space across tasks rather than shared model parameters. To this end, we propose Muscle loss, a novel contrastive learning objective that simultaneously aligns representations from all participating models. Unlike existing multi-view or multi-model contrastive methods, which typically align models pairwise, Muscle loss can effectively capture dependencies across tasks because its minimization is equivalent to the maximization of mutual information among all the models' representations. Building on this principle, we develop FedMuscle, a practical and communication-efficient FMTL algorithm that naturally handles both model and task heterogeneity. Experiments on diverse image and language tasks demonstrate that FedMuscle consistently outperforms state-of-the-art baselines, delivering substantial improvements and robust performance across heterogeneous settings.
Language-Coupled Reinforcement Learning for Multilingual Retrieval-Augmented Generation
Jan 21, 2026Multilingual retrieval-augmented generation (MRAG) requires models to effectively acquire and integrate beneficial external knowledge from multilingual collections. However, most existing studies employ a unitive process where queries of equivalent semantics across different languages are processed through a single-turn retrieval and subsequent optimization. Such a ``one-size-fits-all'' strategy is often suboptimal in multilingual settings, as the models occur to knowledge bias and conflict during the interaction with the search engine. To alleviate the issues, we propose LcRL, a multilingual search-augmented reinforcement learning framework that integrates a language-coupled Group Relative Policy Optimization into the policy and reward models. We adopt the language-coupled group sampling in the rollout module to reduce knowledge bias, and regularize an auxiliary anti-consistency penalty in the reward models to mitigate the knowledge conflict. Experimental results demonstrate that LcRL not only achieves competitive performance but is also appropriate for various practical scenarios such as constrained training data and retrieval over collections encompassing a large number of languages. Our code is available at https://github.com/Cherry-qwq/LcRL-Open.
DK-STN: A Domain Knowledge Embedded Spatio-Temporal Network Model for MJO Forecast
Dec 22, 2025
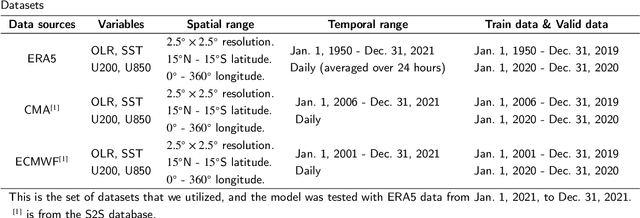


Understanding and predicting the Madden-Julian Oscillation (MJO) is fundamental for precipitation forecasting and disaster prevention. To date, long-term and accurate MJO prediction has remained a challenge for researchers. Conventional MJO prediction methods using Numerical Weather Prediction (NWP) are resource-intensive, time-consuming, and highly unstable (most NWP methods are sensitive to seasons, with better MJO forecast results in winter). While existing Artificial Neural Network (ANN) methods save resources and speed forecasting, their accuracy never reaches the 28 days predicted by the state-of-the-art NWP method, i.e., the operational forecasts from ECMWF, since neural networks cannot handle climate data effectively. In this paper, we present a Domain Knowledge Embedded Spatio-Temporal Network (DK-STN), a stable neural network model for accurate and efficient MJO forecasting. It combines the benefits of NWP and ANN methods and successfully improves the forecast accuracy of ANN methods while maintaining a high level of efficiency and stability. We begin with a spatial-temporal network (STN) and embed domain knowledge in it using two key methods: (i) applying a domain knowledge enhancement method and (ii) integrating a domain knowledge processing method into network training. We evaluated DK-STN with the 5th generation of ECMWF reanalysis (ERA5) data and compared it with ECMWF. Given 7 days of climate data as input, DK-STN can generate reliable forecasts for the following 28 days in 1-2 seconds, with an error of only 2-3 days in different seasons. DK-STN significantly exceeds ECMWF in that its forecast accuracy is equivalent to ECMWF's, while its efficiency and stability are significantly superior.
Closing the Oracle Gap: Increment Vector Transformation for Class Incremental Learning
Sep 26, 2025Class Incremental Learning (CIL) aims to sequentially acquire knowledge of new classes without forgetting previously learned ones. Despite recent progress, current CIL methods still exhibit significant performance gaps compared to their oracle counterparts-models trained with full access to historical data. Inspired by recent insights on Linear Mode Connectivity (LMC), we revisit the geometric properties of oracle solutions in CIL and uncover a fundamental observation: these oracle solutions typically maintain low-loss linear connections to the optimum of previous tasks. Motivated by this finding, we propose Increment Vector Transformation (IVT), a novel plug-and-play framework designed to mitigate catastrophic forgetting during training. Rather than directly following CIL updates, IVT periodically teleports the model parameters to transformed solutions that preserve linear connectivity to previous task optimum. By maintaining low-loss along these connecting paths, IVT effectively ensures stable performance on previously learned tasks. The transformation is efficiently approximated using diagonal Fisher Information Matrices, making IVT suitable for both exemplar-free and exemplar-based scenarios, and compatible with various initialization strategies. Extensive experiments on CIFAR-100, FGVCAircraft, ImageNet-Subset, and ImageNet-Full demonstrate that IVT consistently enhances the performance of strong CIL baselines. Specifically, on CIFAR-100, IVT improves the last accuracy of the PASS baseline by +5.12% and reduces forgetting by 2.54%. For the CLIP-pre-trained SLCA baseline on FGVCAircraft, IVT yields gains of +14.93% in average accuracy and +21.95% in last accuracy. The code will be released.
CMP: A Composable Meta Prompt for SAM-Based Cross-Domain Few-Shot Segmentation
Jul 22, 2025Cross-Domain Few-Shot Segmentation (CD-FSS) remains challenging due to limited data and domain shifts. Recent foundation models like the Segment Anything Model (SAM) have shown remarkable zero-shot generalization capability in general segmentation tasks, making it a promising solution for few-shot scenarios. However, adapting SAM to CD-FSS faces two critical challenges: reliance on manual prompt and limited cross-domain ability. Therefore, we propose the Composable Meta-Prompt (CMP) framework that introduces three key modules: (i) the Reference Complement and Transformation (RCT) module for semantic expansion, (ii) the Composable Meta-Prompt Generation (CMPG) module for automated meta-prompt synthesis, and (iii) the Frequency-Aware Interaction (FAI) module for domain discrepancy mitigation. Evaluations across four cross-domain datasets demonstrate CMP's state-of-the-art performance, achieving 71.8\% and 74.5\% mIoU in 1-shot and 5-shot scenarios respectively.
DFR: A Decompose-Fuse-Reconstruct Framework for Multi-Modal Few-Shot Segmentation
Jul 22, 2025This paper presents DFR (Decompose, Fuse and Reconstruct), a novel framework that addresses the fundamental challenge of effectively utilizing multi-modal guidance in few-shot segmentation (FSS). While existing approaches primarily rely on visual support samples or textual descriptions, their single or dual-modal paradigms limit exploitation of rich perceptual information available in real-world scenarios. To overcome this limitation, the proposed approach leverages the Segment Anything Model (SAM) to systematically integrate visual, textual, and audio modalities for enhanced semantic understanding. The DFR framework introduces three key innovations: 1) Multi-modal Decompose: a hierarchical decomposition scheme that extracts visual region proposals via SAM, expands textual semantics into fine-grained descriptors, and processes audio features for contextual enrichment; 2) Multi-modal Contrastive Fuse: a fusion strategy employing contrastive learning to maintain consistency across visual, textual, and audio modalities while enabling dynamic semantic interactions between foreground and background features; 3) Dual-path Reconstruct: an adaptive integration mechanism combining semantic guidance from tri-modal fused tokens with geometric cues from multi-modal location priors. Extensive experiments across visual, textual, and audio modalities under both synthetic and real settings demonstrate DFR's substantial performance improvements over state-of-the-art methods.
R^2MoE: Redundancy-Removal Mixture of Experts for Lifelong Concept Learning
Jul 17, 2025Enabling large-scale generative models to continuously learn new visual concepts is essential for personalizing pre-trained models to meet individual user preferences. Existing approaches for continual visual concept learning are constrained by two fundamental challenges: catastrophic forgetting and parameter expansion. In this paper, we propose Redundancy-Removal Mixture of Experts (R^2MoE), a parameter-efficient framework for lifelong visual concept learning that effectively learns new concepts while incurring minimal parameter overhead. Our framework includes three key innovative contributions: First, we propose a mixture-of-experts framework with a routing distillation mechanism that enables experts to acquire concept-specific knowledge while preserving the gating network's routing capability, thereby effectively mitigating catastrophic forgetting. Second, we propose a strategy for eliminating redundant layer-wise experts that reduces the number of expert parameters by fully utilizing previously learned experts. Third, we employ a hierarchical local attention-guided inference approach to mitigate interference between generated visual concepts. Extensive experiments have demonstrated that our method generates images with superior conceptual fidelity compared to the state-of-the-art (SOTA) method, achieving an impressive 87.8\% reduction in forgetting rates and 63.3\% fewer parameters on the CustomConcept 101 dataset. Our code is available at {https://github.com/learninginvision/R2MoE}
MINGLE: Mixtures of Null-Space Gated Low-Rank Experts for Test-Time Continual Model Merging
May 17, 2025Continual model merging integrates independently fine-tuned models sequentially without access to original training data, providing a scalable and efficient solution to continual learning. However, current methods still face critical challenges, notably parameter interference among tasks and limited adaptability to evolving test distributions. The former causes catastrophic forgetting of integrated tasks, while the latter hinders effective adaptation to new tasks. To address these, we propose MINGLE, a novel framework for test-time continual model merging, which leverages test-time adaptation using a small set of unlabeled test samples from the current task to dynamically guide the merging process. MINGLE employs a mixture-of-experts architecture composed of parameter-efficient, low-rank experts, enabling efficient adaptation and improving robustness to distribution shifts. To mitigate catastrophic forgetting, we propose Null-Space Constrained Gating, which restricts gating updates to subspaces orthogonal to prior task representations. This suppresses activations on old task inputs and preserves model behavior on past tasks. To further balance stability and adaptability, we design an Adaptive Relaxation Strategy, which dynamically adjusts the constraint strength based on interference signals captured during test-time adaptation. Extensive experiments on standard continual merging benchmarks demonstrate that MINGLE achieves robust generalization, reduces forgetting significantly, and consistently surpasses previous state-of-the-art methods by 7-9\% on average across diverse task orders.
Multilingual Collaborative Defense for Large Language Models
May 17, 2025The robustness and security of large language models (LLMs) has become a prominent research area. One notable vulnerability is the ability to bypass LLM safeguards by translating harmful queries into rare or underrepresented languages, a simple yet effective method of "jailbreaking" these models. Despite the growing concern, there has been limited research addressing the safeguarding of LLMs in multilingual scenarios, highlighting an urgent need to enhance multilingual safety. In this work, we investigate the correlation between various attack features across different languages and propose Multilingual Collaborative Defense (MCD), a novel learning method that optimizes a continuous, soft safety prompt automatically to facilitate multilingual safeguarding of LLMs. The MCD approach offers three advantages: First, it effectively improves safeguarding performance across multiple languages. Second, MCD maintains strong generalization capabilities while minimizing false refusal rates. Third, MCD mitigates the language safety misalignment caused by imbalances in LLM training corpora. To evaluate the effectiveness of MCD, we manually construct multilingual versions of commonly used jailbreak benchmarks, such as MaliciousInstruct and AdvBench, to assess various safeguarding methods. Additionally, we introduce these datasets in underrepresented (zero-shot) languages to verify the language transferability of MCD. The results demonstrate that MCD outperforms existing approaches in safeguarding against multilingual jailbreak attempts while also exhibiting strong language transfer capabilities. Our code is available at https://github.com/HLiang-Lee/MCD.
LoRA-Based Continual Learning with Constraints on Critical Parameter Changes
Apr 18, 2025LoRA-based continual learning represents a promising avenue for leveraging pre-trained models in downstream continual learning tasks. Recent studies have shown that orthogonal LoRA tuning effectively mitigates forgetting. However, this work unveils that under orthogonal LoRA tuning, the critical parameters for pre-tasks still change notably after learning post-tasks. To address this problem, we directly propose freezing the most critical parameter matrices in the Vision Transformer (ViT) for pre-tasks before learning post-tasks. In addition, building on orthogonal LoRA tuning, we propose orthogonal LoRA composition (LoRAC) based on QR decomposition, which may further enhance the plasticity of our method. Elaborate ablation studies and extensive comparisons demonstrate the effectiveness of our proposed method. Our results indicate that our method achieves state-of-the-art (SOTA) performance on several well-known continual learning benchmarks. For instance, on the Split CIFAR-100 dataset, our method shows a 6.35\% improvement in accuracy and a 3.24\% reduction in forgetting compared to previous methods. Our code is available at https://github.com/learninginvision/LoRAC-IPC.