 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcordia: JIT-Compiled Persistent-Kernel Checkpointing for Fault-Tolerant LLM Inference
Jun 22, 2026Long-running LLM agents keep valuable state resident on GPUs: KV caches, request schedulers, communication state, and sometimes online adapters. Losing this state after a GPU or communicator failure can discard minutes to hours of work, yet existing recovery mechanisms either restart the whole serving stack or require application-specific checkpoint logic inside every attention and runtime component. This paper argues that fault tolerance for such workloads needs a GPU-resident execution context: checkpoint hooks must run at device synchronization points, observe binary kernels that frameworks and libraries actually execute, and recover without putting the host CPU on the critical path. We present Concordia, a runtime that uses a device-resident persistent kernel as the substrate for fault-tolerant LLM inference. Concordia interposes on GPU module loading and supports PTX- and SASS-level instrumentation, allowing checkpoint and pause hooks to be inserted below framework code and library boundaries. For each registered LLM state region, Concordia JIT-compiles a specialized delta-checkpoint handler -- for example, a KV-block scanner, adapter-page scanner, or recovery applier -- and hot-swaps it into the persistent kernel's operator table. The persistent kernel consumes a lock-free ring buffer of compute, checkpoint, append-log, and recovery tasks, so the same always-on executor triggers dirty-page detection, stages deltas, and appends committed records to a CPU-visible log in CXL memory or host DRAM.
Fair-Eye Net: A Fair, Trustworthy, Multimodal Integrated Glaucoma Full Chain AI System
Jan 26, 2026Glaucoma is a top cause of irreversible blindness globally, making early detection and longitudinal follow-up pivotal to preventing permanent vision loss. Current screening and progression assessment, however, rely on single tests or loosely linked examinations, introducing subjectivity and fragmented care. Limited access to high-quality imaging tools and specialist expertise further compromises consistency and equity in real-world use. To address these gaps, we developed Fair-Eye Net, a fair, reliable multimodal AI system closing the clinical loop from glaucoma screening to follow-up and risk alerting. It integrates fundus photos, OCT structural metrics, VF functional indices, and demographic factors via a dual-stream heterogeneous fusion architecture, with an uncertainty-aware hierarchical gating strategy for selective prediction and safe referral. A fairness constraint reduces missed diagnoses in disadvantaged subgroups. Experimental results show it achieved an AUC of 0.912 (96.7% specificity), cut racial false-negativity disparity by 73.4% (12.31% to 3.28%), maintained stable cross-domain performance, and enabled 3-12 months of early risk alerts (92% sensitivity, 88% specificity). Unlike post hoc fairness adjustments, Fair-Eye Net optimizes fairness as a primary goal with clinical reliability via multitask learning, offering a reproducible path for clinical translation and large-scale deployment to advance global eye health equity.
Pegasus: A Universal Framework for Scalable Deep Learning Inference on the Dataplane
Jun 06, 2025The paradigm of Intelligent DataPlane (IDP) embeds deep learning (DL) models on the network dataplane to enable intelligent traffic analysis at line-speed. However, the current use of the match-action table (MAT) abstraction on the dataplane is misaligned with DL inference, leading to several key limitations, including accuracy degradation, limited scale, and lack of generality. This paper proposes Pegasus to address these limitations. Pegasus translates DL operations into three dataplane-oriented primitives to achieve generality: Partition, Map, and SumReduce. Specifically, Partition "divides" high-dimensional features into multiple low-dimensional vectors, making them more suitable for the dataplane; Map "conquers" computations on the low-dimensional vectors in parallel with the technique of fuzzy matching, while SumReduce "combines" the computation results. Additionally, Pegasus employs Primitive Fusion to merge computations, improving scalability. Finally, Pegasus adopts full precision weights with fixed-point activations to improve accuracy. Our implementation on a P4 switch demonstrates that Pegasus can effectively support various types of DL models, including Multi-Layer Perceptron (MLP), Recurrent Neural Network (RNN), Convolutional Neural Network (CNN), and AutoEncoder models on the dataplane. Meanwhile, Pegasus outperforms state-of-the-art approaches with an average accuracy improvement of up to 22.8%, along with up to 248x larger model size and 212x larger input scale.
Modulating CNN Features with Pre-Trained ViT Representations for Open-Vocabulary Object Detection
Jan 28, 2025Owing to large-scale image-text contrastive training, pre-trained vision language model (VLM) like CLIP shows superior open-vocabulary recognition ability. Most existing open-vocabulary object detectors attempt to utilize the pre-trained VLM to attain generative representation. F-ViT uses the pre-trained visual encoder as the backbone network and freezes it during training. However, the frozen backbone doesn't benefit from the labeled data to strengthen the representation. Therefore, we propose a novel two-branch backbone network design, named as ViT-Feature-Modulated Multi-Scale Convolutional network (VMCNet). VMCNet consists of a trainable convolutional branch, a frozen pre-trained ViT branch and a feature modulation module. The trainable CNN branch could be optimized with labeled data while the frozen pre-trained ViT branch could keep the representation ability derived from large-scale pre-training. Then, the proposed feature modulation module could modulate the multi-scale CNN features with the representations from ViT branch. With the proposed mixed structure, detector is more likely to discover novel categories. Evaluated on two popular benchmarks, our method boosts the detection performance on novel category and outperforms the baseline. On OV-COCO, the proposed method achieves 44.3 AP$_{50}^{\mathrm{novel}}$ with ViT-B/16 and 48.5 AP$_{50}^{\mathrm{novel}}$ with ViT-L/14. On OV-LVIS, VMCNet with ViT-B/16 and ViT-L/14 reaches 27.8 and 38.4 mAP$_{r}$.
MMW-Carry: Enhancing Carry Object Detection through Millimeter-Wave Radar-Camera Fusion
Feb 24, 2024



This paper introduces MMW-Carry, a system designed to predict the probability of individuals carrying various objects using millimeter-wave radar signals, complemented by camera input. The primary goal of MMW-Carry is to provide a rapid and cost-effective preliminary screening solution, specifically tailored for non-super-sensitive scenarios. Overall, MMW-Carry achieves significant advancements in two crucial aspects. Firstly, it addresses localization challenges in complex indoor environments caused by multi-path reflections, enhancing the system's overall robustness. This is accomplished by the integration of camera-based human detection, tracking, and the radar-camera plane transformation for obtaining subjects' spatial occupancy region, followed by a zooming-in operation on the radar images. Secondly, the system performance is elevated by leveraging long-term observation of a subject. This is realized through the intelligent fusion of neural network results from multiple different-view radar images of an in-track moving subject and their carried objects, facilitated by a proposed knowledge-transfer module. Our experiment results demonstrate that MMW-Carry detects objects with an average error rate of 25.22\% false positives and a 21.71\% missing rate for individuals moving randomly in a large indoor space, carrying the common-in-everyday-life objects, both in open carry or concealed ways. These findings affirm MMW-Carry's potential to extend its capabilities to detect a broader range of objects for diverse applications.
Learning for Semantic Knowledge Base-Guided Online Feature Transmission in Dynamic Channels
Nov 30, 2023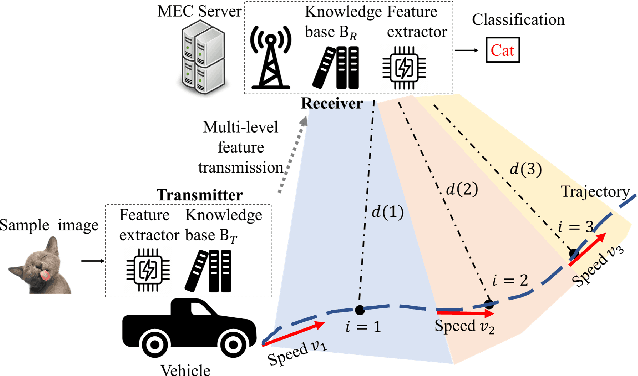
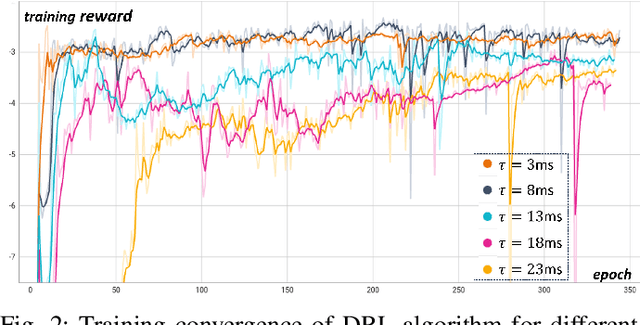
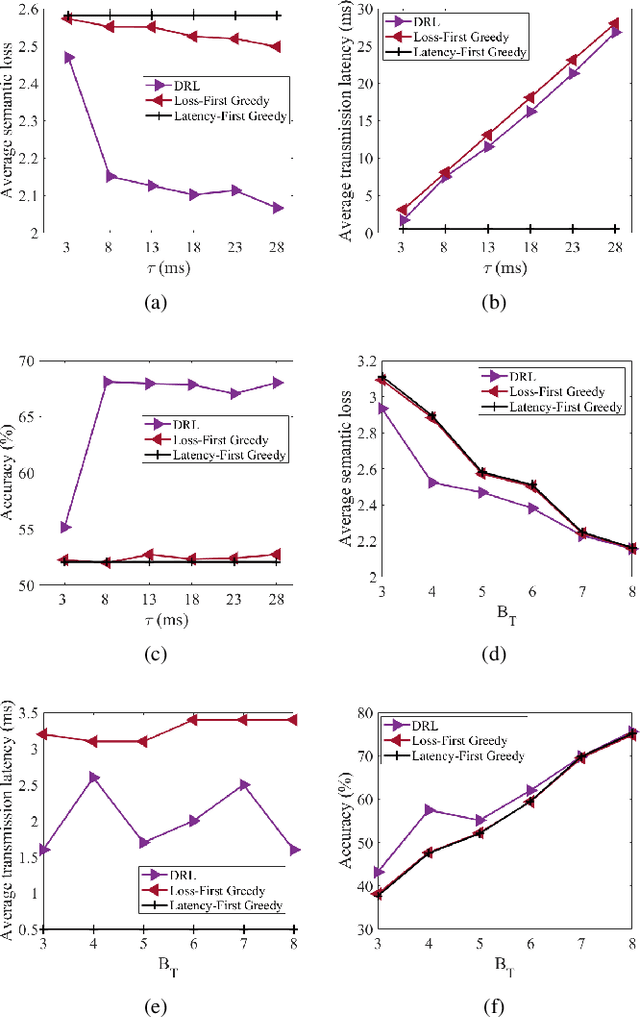
With the proliferation of edge computing, efficient AI inference on edge devices has become essential for intelligent applications such as autonomous vehicles and VR/AR. In this context, we address the problem of efficient remote object recognition by optimizing feature transmission between mobile devices and edge servers. We propose an online optimization framework to address the challenge of dynamic channel conditions and device mobility in an end-to-end communication system. Our approach builds upon existing methods by leveraging a semantic knowledge base to drive multi-level feature transmission, accounting for temporal factors and dynamic elements throughout the transmission process. To solve the online optimization problem, we design a novel soft actor-critic-based deep reinforcement learning system with a carefully designed reward function for real-time decision-making, overcoming the optimization difficulty of the NP-hard problem and achieving the minimization of semantic loss while respecting latency constraints. Numerical results showcase the superiority of our approach compared to traditional greedy methods under various system setups.
Static Background Removal in Vehicular Radar: Filtering in Azimuth-Elevation-Doppler Domain
Jul 04, 2023



A significant challenge in autonomous driving systems lies in image understanding within complex environments, particularly dense traffic scenarios. An effective solution to this challenge involves removing the background or static objects from the scene, so as to enhance the detection of moving targets as key component of improving overall system performance. In this paper, we present an efficient algorithm for background removal in automotive radar applications, specifically utilizing a frequency-modulated continuous wave (FMCW) radar. Our proposed algorithm follows a three-step approach, encompassing radar signal preprocessing, three-dimensional (3D) ego-motion estimation, and notch filter-based background removal in the azimuth-elevation-Doppler domain. To begin, we model the received signal of the FMCW multiple-input multiple-output (MIMO) radar and develop a signal processing framework for extracting four-dimensional (4D) point clouds. Subsequently, we introduce a robust 3D ego-motion estimation algorithm that accurately estimates radar ego-motion speed, accounting for Doppler ambiguity, by processing the point clouds. Additionally, our algorithm leverages the relationship between Doppler velocity, azimuth angle, elevation angle, and radar ego-motion speed to identify the spectrum belonging to background clutter. Subsequently, we employ notch filters to effectively filter out the background clutter. The performance of our algorithm is evaluated using both simulated data and extensive experiments with real-world data. The results demonstrate its effectiveness in efficiently removing background clutter and enhacing perception within complex environments. By offering a fast and computationally efficient solution, our approach effectively addresses challenges posed by non-homogeneous environments and real-time processing requirements.
MedFMC: A Real-world Dataset and Benchmark For Foundation Model Adaptation in Medical Image Classification
Jun 16, 2023Foundation models, often pre-trained with large-scale data, have achieved paramount success in jump-starting various vision and language applications. Recent advances further enable adapting foundation models in downstream tasks efficiently using only a few training samples, e.g., in-context learning. Yet, the application of such learning paradigms in medical image analysis remains scarce due to the shortage of publicly accessible data and benchmarks. In this paper, we aim at approaches adapting the foundation models for medical image classification and present a novel dataset and benchmark for the evaluation, i.e., examining the overall performance of accommodating the large-scale foundation models downstream on a set of diverse real-world clinical tasks. We collect five sets of medical imaging data from multiple institutes targeting a variety of real-world clinical tasks (22,349 images in total), i.e., thoracic diseases screening in X-rays, pathological lesion tissue screening, lesion detection in endoscopy images, neonatal jaundice evaluation, and diabetic retinopathy grading. Results of multiple baseline methods are demonstrated using the proposed dataset from both accuracy and cost-effective perspectives.
Learning to Detect Open Carry and Concealed Object with 77GHz Radar
Oct 31, 2021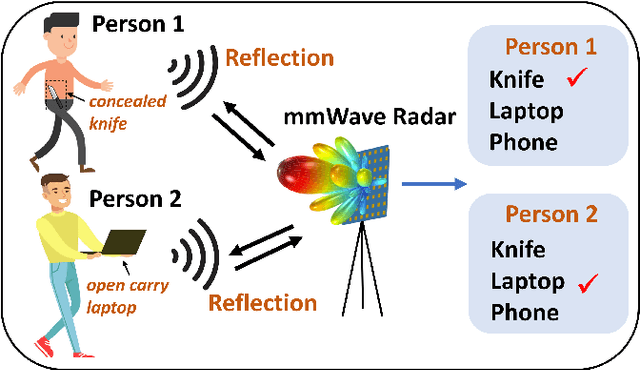

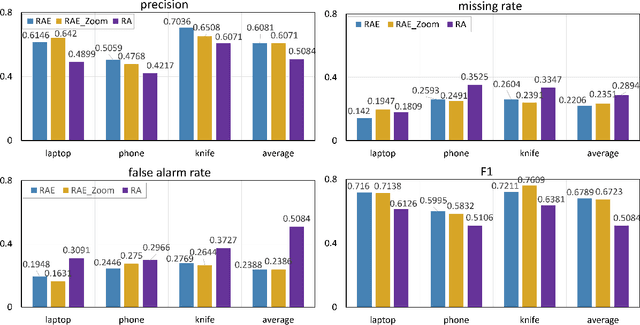
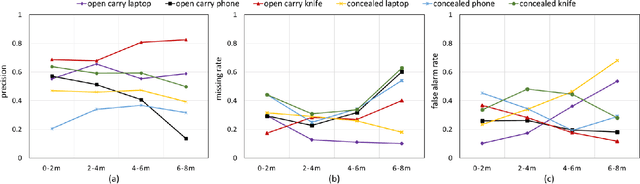
Detecting harmful carried objects plays a key role in intelligent surveillance systems and has widespread applications, for example, in airport security. In this paper, we focus on the relatively unexplored area of using low-cost 77GHz mmWave radar for the carried objects detection problem. The proposed system is capable of real-time detecting three classes of objects - laptop, phone, and knife - under open carry and concealed cases where objects are hidden with clothes or bags. This capability is achieved by initial signal processing for localization and generating range-azimuth-elevation image cubes, followed by a deep learning-based prediction network and a multi-shot post-processing module for detecting objects. Extensive experiments for validating the system performance on detecting open carry and concealed objects have been presented with a self-built radar-camera testbed and dataset. Additionally, the influence of different input, factors, and parameters on system performance is analyzed, providing an intuitive understanding of the system. This system would be the very first baseline for other future works aiming to detect carried objects using 77GHz radar.
Perception Through 2D-MIMO FMCW Automotive Radar Under Adverse Weather
Apr 23, 2021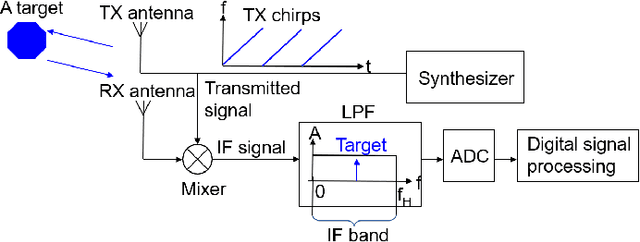

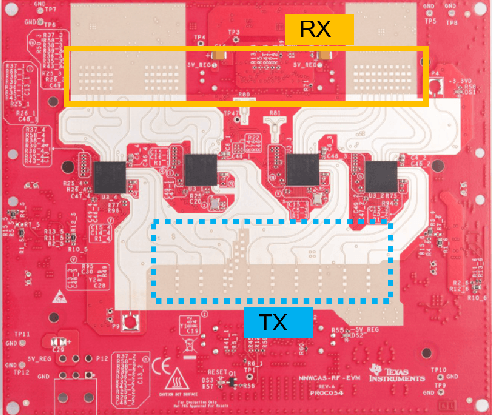
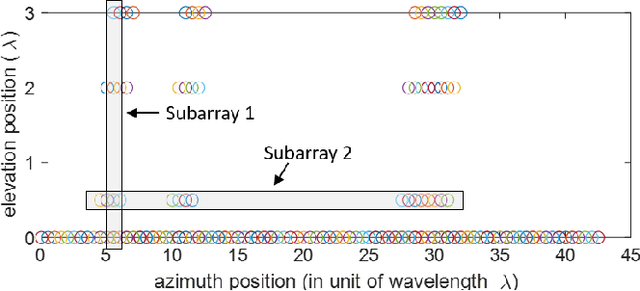
Millimeter-wave (mmWave) radars are being increasingly integrated in commercial vehicles to support new Adaptive Driver Assisted Systems (ADAS) features that require accurate location and Doppler velocity estimates of objects, independent of environmental conditions. To explore radar-based ADAS applications, we have updated our test-bed with Texas Instrument's 4-chip cascaded FMCW radar (TIDEP-01012) that forms a non-uniform 2D MIMO virtual array. In this paper, we develop the necessary received signal models for applying different direction of arrival (DoA) estimation algorithms and experimentally validating their performance on formed virtual array under controlled scenarios. To test the robustness of mmWave radars under adverse weather conditions, we collected raw radar dataset (I-Q samples post demodulated) for various objects by a driven vehicle-mounted platform, specifically for snowy and foggy situations where cameras are largely ineffective. Initial results from radar imaging algorithms to this dataset are presented.