 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking High-Fidelity Analog Joint Source-Channel Coding on Standard Digital Transceivers
Mar 10, 2026Analog joint source-channel coding (JSCC) has demonstrated superior performance for semantic communications through graceful degradation across channel conditions. However, a fundamental hardware-software mismatch prevents deployment on modern digital physical layers (PHYs): analog JSCC generates continuous-valued symbols requiring infinite waveform diversity, while digital PHYs produce a finite set of discrete waveforms and employ non-differentiable operations that break end-to-end gradient flow. Existing solutions either fundamentally limit representation granularity or require impractical white-box PHY access. We introduce D2AJSCC, a novel framework enabling high-fidelity analog JSCC deployment on standard digital PHYs. Our approach exploits orthogonal frequency-division multiplexing's parallel subcarrier structure as a waveform synthesizer: computational PHY inversion determines input bitstreams that orchestrate subcarrier amplitudes and phases to emulate ideal analog waveforms. To enable end-to-end training despite non-differentiable PHY operations, we develop ProxyNet-a differentiable neural surrogate of the communication link that provides uninterrupted gradient flow while preventing JSCC degeneration. Simulation results for image transmission over WiFi PHY demonstrate that our system achieves near-ideal analog JSCC performance with graceful degradation across SNR conditions, while baselines exhibit cliff effects or catastrophic failures. By enabling next-generation semantic transmission on legacy infrastructure without hardware modification, our framework promotes sustainable network evolution and bridges the critical gap between analog JSCC's theoretical promise and practical deployment on ubiquitous digital hardware.
Generative Semantic Communication: Architectures, Technologies, and Applications
Dec 11, 2024



This paper delves into the applications of generative artificial intelligence (GAI) in semantic communication (SemCom) and presents a thorough study. Three popular SemCom systems enabled by classical GAI models are first introduced, including variational autoencoders, generative adversarial networks, and diffusion models. For each system, the fundamental concept of the GAI model, the corresponding SemCom architecture, and the associated literature review of recent efforts are elucidated. Then, a novel generative SemCom system is proposed by incorporating the cutting-edge GAI technology-large language models (LLMs). This system features two LLM-based AI agents at both the transmitter and receiver, serving as "brains" to enable powerful information understanding and content regeneration capabilities, respectively. This innovative design allows the receiver to directly generate the desired content, instead of recovering the bit stream, based on the coded semantic information conveyed by the transmitter. Therefore, it shifts the communication mindset from "information recovery" to "information regeneration" and thus ushers in a new era of generative SemCom. A case study on point-to-point video retrieval is presented to demonstrate the superiority of the proposed generative SemCom system, showcasing a 99.98% reduction in communication overhead and a 53% improvement in retrieval accuracy compared to the traditional communication system. Furthermore, four typical application scenarios for generative SemCom are delineated, followed by a discussion of three open issues warranting future investigation. In a nutshell, this paper provides a holistic set of guidelines for applying GAI in SemCom, paving the way for the efficient implementation of generative SemCom in future wireless networks.
WDMoE: Wireless Distributed Mixture of Experts for Large Language Models
Nov 11, 2024



Large Language Models (LLMs) have achieved significant success in various natural language processing tasks, but the role of wireless networks in supporting LLMs has not been thoroughly explored. In this paper, we propose a wireless distributed Mixture of Experts (WDMoE) architecture to enable collaborative deployment of LLMs across edge servers at the base station (BS) and mobile devices in wireless networks. Specifically, we decompose the MoE layer in LLMs by placing the gating network and the preceding neural network layer at BS, while distributing the expert networks among the devices. This deployment leverages the parallel inference capabilities of expert networks on mobile devices, effectively utilizing the limited computing and caching resources of these devices. Accordingly, we develop a performance metric for WDMoE-based LLMs, which accounts for both model capability and latency. To minimize the latency while maintaining accuracy, we jointly optimize expert selection and bandwidth allocation based on the performance metric. Moreover, we build a hardware testbed using NVIDIA Jetson kits to validate the effectiveness of WDMoE. Both theoretical simulations and practical hardware experiments demonstrate that the proposed method can significantly reduce the latency without compromising LLM performance.
MambaJSCC: Adaptive Deep Joint Source-Channel Coding with Generalized State Space Model
Sep 25, 2024



Lightweight and efficient neural network models for deep joint source-channel coding (JSCC) are crucial for semantic communications. In this paper, we propose a novel JSCC architecture, named MambaJSCC, that achieves state-of-the-art performance with low computational and parameter overhead. MambaJSCC utilizes the visual state space model with channel adaptation (VSSM-CA) blocks as its backbone for transmitting images over wireless channels, where the VSSM-CA primarily consists of the generalized state space models (GSSM) and the zero-parameter, zero-computational channel adaptation method (CSI-ReST). We design the GSSM module, leveraging reversible matrix transformations to express generalized scan expanding operations, and theoretically prove that two GSSM modules can effectively capture global information. We discover that GSSM inherently possesses the ability to adapt to channels, a form of endogenous intelligence. Based on this, we design the CSI-ReST method, which injects channel state information (CSI) into the initial state of GSSM to utilize its native response, and into the residual state to mitigate CSI forgetting, enabling effective channel adaptation without introducing additional computational and parameter overhead. Experimental results show that MambaJSCC not only outperforms existing JSCC methods (e.g., SwinJSCC) across various scenarios but also significantly reduces parameter size, computational overhead, and inference delay.
WDMoE: Wireless Distributed Large Language Models with Mixture of Experts
May 06, 2024



Large Language Models (LLMs) have achieved significant success in various natural language processing tasks, but how wireless communications can support LLMs has not been extensively studied. In this paper, we propose a wireless distributed LLMs paradigm based on Mixture of Experts (MoE), named WDMoE, deploying LLMs collaboratively across edge servers of base station (BS) and mobile devices in the wireless communications system. Specifically, we decompose the MoE layer in LLMs by deploying the gating network and the preceding neural network layer at BS, while distributing the expert networks across the devices. This arrangement leverages the parallel capabilities of expert networks on distributed devices. Moreover, to overcome the instability of wireless communications, we design an expert selection policy by taking into account both the performance of the model and the end-to-end latency, which includes both transmission delay and inference delay. Evaluations conducted across various LLMs and multiple datasets demonstrate that WDMoE not only outperforms existing models, such as Llama 2 with 70 billion parameters, but also significantly reduces end-to-end latency.
MMW-Carry: Enhancing Carry Object Detection through Millimeter-Wave Radar-Camera Fusion
Feb 24, 2024



This paper introduces MMW-Carry, a system designed to predict the probability of individuals carrying various objects using millimeter-wave radar signals, complemented by camera input. The primary goal of MMW-Carry is to provide a rapid and cost-effective preliminary screening solution, specifically tailored for non-super-sensitive scenarios. Overall, MMW-Carry achieves significant advancements in two crucial aspects. Firstly, it addresses localization challenges in complex indoor environments caused by multi-path reflections, enhancing the system's overall robustness. This is accomplished by the integration of camera-based human detection, tracking, and the radar-camera plane transformation for obtaining subjects' spatial occupancy region, followed by a zooming-in operation on the radar images. Secondly, the system performance is elevated by leveraging long-term observation of a subject. This is realized through the intelligent fusion of neural network results from multiple different-view radar images of an in-track moving subject and their carried objects, facilitated by a proposed knowledge-transfer module. Our experiment results demonstrate that MMW-Carry detects objects with an average error rate of 25.22\% false positives and a 21.71\% missing rate for individuals moving randomly in a large indoor space, carrying the common-in-everyday-life objects, both in open carry or concealed ways. These findings affirm MMW-Carry's potential to extend its capabilities to detect a broader range of objects for diverse applications.
MOC-RVQ: Multilevel Codebook-assisted Digital Generative Semantic Communication
Jan 02, 2024



Vector quantization-based image semantic communication systems have successfully boosted transmission efficiency, but face a challenge with conflicting requirements between codebook design and digital constellation modulation. Traditional codebooks need a wide index range, while modulation favors few discrete states. To address this, we propose a multilevel generative semantic communication system with a two-stage training framework. In the first stage, we train a high-quality codebook, using a multi-head octonary codebook (MOC) to compress the index range. We also integrate a residual vector quantization (RVQ) mechanism for effective multilevel communication. In the second stage, a noise reduction block (NRB) based on Swin Transformer is introduced, coupled with the multilevel codebook from the first stage, serving as a high-quality semantic knowledge base (SKB) for generative feature restoration. Experimental results highlight MOC-RVQ's superior performance over methods like BPG or JPEG, even without channel error correction coding.
Learning for Semantic Knowledge Base-Guided Online Feature Transmission in Dynamic Channels
Nov 30, 2023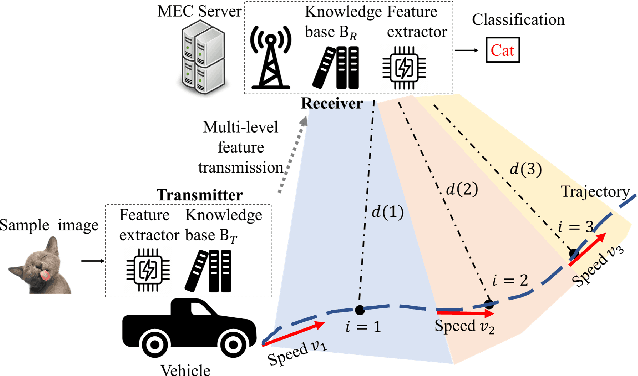
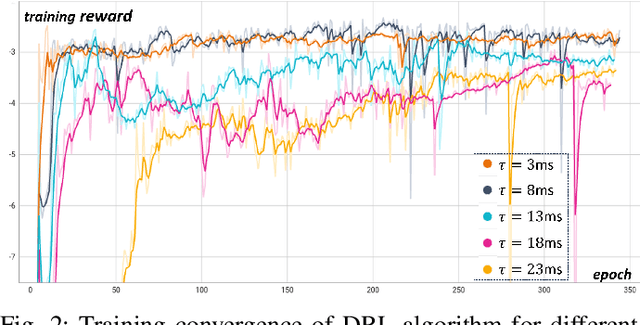
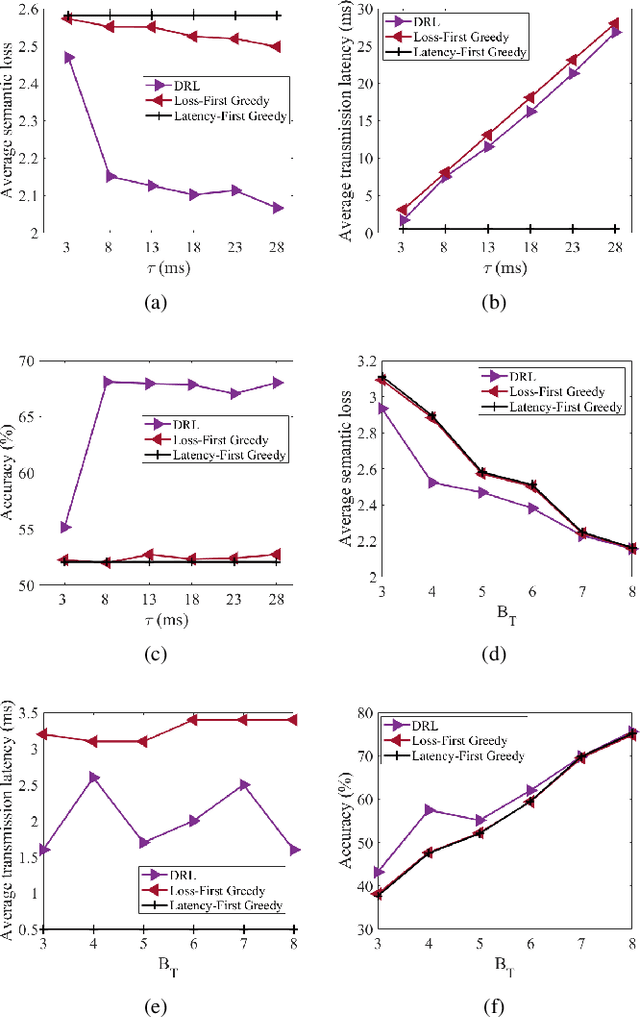
With the proliferation of edge computing, efficient AI inference on edge devices has become essential for intelligent applications such as autonomous vehicles and VR/AR. In this context, we address the problem of efficient remote object recognition by optimizing feature transmission between mobile devices and edge servers. We propose an online optimization framework to address the challenge of dynamic channel conditions and device mobility in an end-to-end communication system. Our approach builds upon existing methods by leveraging a semantic knowledge base to drive multi-level feature transmission, accounting for temporal factors and dynamic elements throughout the transmission process. To solve the online optimization problem, we design a novel soft actor-critic-based deep reinforcement learning system with a carefully designed reward function for real-time decision-making, overcoming the optimization difficulty of the NP-hard problem and achieving the minimization of semantic loss while respecting latency constraints. Numerical results showcase the superiority of our approach compared to traditional greedy methods under various system setups.
Knowledge Base Enabled Semantic Communication: A Generative Perspective
Nov 21, 2023



Semantic communication is widely touted as a key technology for propelling the sixth-generation (6G) wireless networks. However, providing effective semantic representation is quite challenging in practice. To address this issue, this article takes a crack at exploiting semantic knowledge base (KB) to usher in a new era of generative semantic communication. Via semantic KB, source messages can be characterized in low-dimensional subspaces without compromising their desired meaning, thus significantly enhancing the communication efficiency. The fundamental principle of semantic KB is first introduced, and a generative semantic communication architecture is developed by presenting three sub-KBs, namely source, task, and channel KBs. Then, the detailed construction approaches for each sub-KB are described, followed by their utilization in terms of semantic coding and transmission. A case study is also provided to showcase the superiority of generative semantic communication over conventional syntactic communication and classical semantic communication. In a nutshell, this article establishes a scientific foundation for the exciting uncharted frontier of generative semantic communication.