 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Representation Image Compression at Ultra-Low Bitrates via Explicit Semantics and Implicit Textures
Feb 05, 2026While recent neural codecs achieve strong performance at low bitrates when optimized for perceptual quality, their effectiveness deteriorates significantly under ultra-low bitrate conditions. To mitigate this, generative compression methods leveraging semantic priors from pretrained models have emerged as a promising paradigm. However, existing approaches are fundamentally constrained by a tradeoff between semantic faithfulness and perceptual realism. Methods based on explicit representations preserve content structure but often lack fine-grained textures, whereas implicit methods can synthesize visually plausible details at the cost of semantic drift. In this work, we propose a unified framework that bridges this gap by coherently integrating explicit and implicit representations in a training-free manner. Specifically, We condition a diffusion model on explicit high-level semantics while employing reverse-channel coding to implicitly convey fine-grained details. Moreover, we introduce a plug-in encoder that enables flexible control of the distortion-perception tradeoff by modulating the implicit information. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art rate-perception performance, outperforming existing methods and surpassing DiffC by 29.92%, 19.33%, and 20.89% in DISTS BD-Rate on the Kodak, DIV2K, and CLIC2020 datasets, respectively.
SurfSplat: Conquering Feedforward 2D Gaussian Splatting with Surface Continuity Priors
Feb 03, 2026Reconstructing 3D scenes from sparse images remains a challenging task due to the difficulty of recovering accurate geometry and texture without optimization. Recent approaches leverage generalizable models to generate 3D scenes using 3D Gaussian Splatting (3DGS) primitive. However, they often fail to produce continuous surfaces and instead yield discrete, color-biased point clouds that appear plausible at normal resolution but reveal severe artifacts under close-up views. To address this issue, we present SurfSplat, a feedforward framework based on 2D Gaussian Splatting (2DGS) primitive, which provides stronger anisotropy and higher geometric precision. By incorporating a surface continuity prior and a forced alpha blending strategy, SurfSplat reconstructs coherent geometry together with faithful textures. Furthermore, we introduce High-Resolution Rendering Consistency (HRRC), a new evaluation metric designed to evaluate high-resolution reconstruction quality. Extensive experiments on RealEstate10K, DL3DV, and ScanNet demonstrate that SurfSplat consistently outperforms prior methods on both standard metrics and HRRC, establishing a robust solution for high-fidelity 3D reconstruction from sparse inputs. Project page: https://hebing-sjtu.github.io/SurfSplat-website/
Constrained Dynamic Gaussian Splatting
Feb 03, 2026While Dynamic Gaussian Splatting enables high-fidelity 4D reconstruction, its deployment is severely hindered by a fundamental dilemma: unconstrained densification leads to excessive memory consumption incompatible with edge devices, whereas heuristic pruning fails to achieve optimal rendering quality under preset Gaussian budgets. In this work, we propose Constrained Dynamic Gaussian Splatting (CDGS), a novel framework that formulates dynamic scene reconstruction as a budget-constrained optimization problem to enforce a strict, user-defined Gaussian budget during training. Our key insight is to introduce a differentiable budget controller as the core optimization driver. Guided by a multi-modal unified importance score, this controller fuses geometric, motion, and perceptual cues for precise capacity regulation. To maximize the utility of this fixed budget, we further decouple the optimization of static and dynamic elements, employing an adaptive allocation mechanism that dynamically distributes capacity based on motion complexity. Furthermore, we implement a three-phase training strategy to seamlessly integrate these constraints, ensuring precise adherence to the target count. Coupled with a dual-mode hybrid compression scheme, CDGS not only strictly adheres to hardware constraints (error < 2%}) but also pushes the Pareto frontier of rate-distortion performance. Extensive experiments demonstrate that CDGS delivers optimal rendering quality under varying capacity limits, achieving over 3x compression compared to state-of-the-art methods.
ProxyImg: Towards Highly-Controllable Image Representation via Hierarchical Disentangled Proxy Embedding
Feb 02, 2026Prevailing image representation methods, including explicit representations such as raster images and Gaussian primitives, as well as implicit representations such as latent images, either suffer from representation redundancy that leads to heavy manual editing effort, or lack a direct mapping from latent variables to semantic instances or parts, making fine-grained manipulation difficult. These limitations hinder efficient and controllable image and video editing. To address these issues, we propose a hierarchical proxy-based parametric image representation that disentangles semantic, geometric, and textural attributes into independent and manipulable parameter spaces. Based on a semantic-aware decomposition of the input image, our representation constructs hierarchical proxy geometries through adaptive Bezier fitting and iterative internal region subdivision and meshing. Multi-scale implicit texture parameters are embedded into the resulting geometry-aware distributed proxy nodes, enabling continuous high-fidelity reconstruction in the pixel domain and instance- or part-independent semantic editing. In addition, we introduce a locality-adaptive feature indexing mechanism to ensure spatial texture coherence, which further supports high-quality background completion without relying on generative models. Extensive experiments on image reconstruction and editing benchmarks, including ImageNet, OIR-Bench, and HumanEdit, demonstrate that our method achieves state-of-the-art rendering fidelity with significantly fewer parameters, while enabling intuitive, interactive, and physically plausible manipulation. Moreover, by integrating proxy nodes with Position-Based Dynamics, our framework supports real-time physics-driven animation using lightweight implicit rendering, achieving superior temporal consistency and visual realism compared with generative approaches.
Joint Source-Channel-Generation Coding: From Distortion-oriented Reconstruction to Semantic-consistent Generation
Jan 19, 2026Conventional communication systems, including both separation-based coding and AI-driven joint source-channel coding (JSCC), are largely guided by Shannon's rate-distortion theory. However, relying on generic distortion metrics fails to capture complex human visual perception, often resulting in blurred or unrealistic reconstructions. In this paper, we propose Joint Source-Channel-Generation Coding (JSCGC), a novel paradigm that shifts the focus from deterministic reconstruction to probabilistic generation. JSCGC leverages a generative model at the receiver as a generator rather than a conventional decoder to parameterize the data distribution, enabling direct maximization of mutual information under channel constraints while controlling stochastic sampling to produce outputs residing on the authentic data manifold with high fidelity. We further derive a theoretical lower bound on the maximum semantic inconsistency with given transmitted mutual information, elucidating the fundamental limits of communication in controlling the generative process. Extensive experiments on image transmission demonstrate that JSCGC substantially improves perceptual quality and semantic fidelity, significantly outperforming conventional distortion-oriented JSCC methods.
DiT-JSCC: Rethinking Deep JSCC with Diffusion Transformers and Semantic Representations
Jan 06, 2026Generative joint source-channel coding (GJSCC) has emerged as a new Deep JSCC paradigm for achieving high-fidelity and robust image transmission under extreme wireless channel conditions, such as ultra-low bandwidth and low signal-to-noise ratio. Recent studies commonly adopt diffusion models as generative decoders, but they frequently produce visually realistic results with limited semantic consistency. This limitation stems from a fundamental mismatch between reconstruction-oriented JSCC encoders and generative decoders, as the former lack explicit semantic discriminability and fail to provide reliable conditional cues. In this paper, we propose DiT-JSCC, a novel GJSCC backbone that can jointly learn a semantics-prioritized representation encoder and a diffusion transformer (DiT) based generative decoder, our open-source project aims to promote the future research in GJSCC. Specifically, we design a semantics-detail dual-branch encoder that aligns naturally with a coarse-to-fine conditional DiT decoder, prioritizing semantic consistency under extreme channel conditions. Moreover, a training-free adaptive bandwidth allocation strategy inspired by Kolmogorov complexity is introduced to further improve the transmission efficiency, thereby indeed redefining the notion of information value in the era of generative decoding. Extensive experiments demonstrate that DiT-JSCC consistently outperforms existing JSCC methods in both semantic consistency and visual quality, particularly in extreme regimes.
Structure-Guided Allocation of 2D Gaussians for Image Representation and Compression
Dec 30, 2025Recent advances in 2D Gaussian Splatting (2DGS) have demonstrated its potential as a compact image representation with millisecond-level decoding. However, existing 2DGS-based pipelines allocate representation capacity and parameter precision largely oblivious to image structure, limiting their rate-distortion (RD) efficiency at low bitrates. To address this, we propose a structure-guided allocation principle for 2DGS, which explicitly couples image structure with both representation capacity and quantization precision, while preserving native decoding speed. First, we introduce a structure-guided initialization that assigns 2D Gaussians according to spatial structural priors inherent in natural images, yielding a localized and semantically meaningful distribution. Second, during quantization-aware fine-tuning, we propose adaptive bitwidth quantization of covariance parameters, which grants higher precision to small-scale Gaussians in complex regions and lower precision elsewhere, enabling RD-aware optimization, thereby reducing redundancy without degrading edge quality. Third, we impose a geometry-consistent regularization that aligns Gaussian orientations with local gradient directions to better preserve structural details. Extensive experiments demonstrate that our approach substantially improves both the representational power and the RD performance of 2DGS while maintaining over 1000 FPS decoding. Compared with the baseline GSImage, we reduce BD-rate by 43.44% on Kodak and 29.91% on DIV2K.
MultiEgo: A Multi-View Egocentric Video Dataset for 4D Scene Reconstruction
Dec 12, 2025Multi-view egocentric dynamic scene reconstruction holds significant research value for applications in holographic documentation of social interactions. However, existing reconstruction datasets focus on static multi-view or single-egocentric view setups, lacking multi-view egocentric datasets for dynamic scene reconstruction. Therefore, we present MultiEgo, the first multi-view egocentric dataset for 4D dynamic scene reconstruction. The dataset comprises five canonical social interaction scenes: meetings, performances, and a presentation. Each scene provides five authentic egocentric videos captured by participants wearing AR glasses. We design a hardware-based data acquisition system and processing pipeline, achieving sub-millisecond temporal synchronization across views, coupled with accurate pose annotations. Experiment validation demonstrates the practical utility and effectiveness of our dataset for free-viewpoint video (FVV) applications, establishing MultiEgo as a foundational resource for advancing multi-view egocentric dynamic scene reconstruction research.
Evaluating from Benign to Dynamic Adversarial: A Squid Game for Large Language Models
Nov 12, 2025

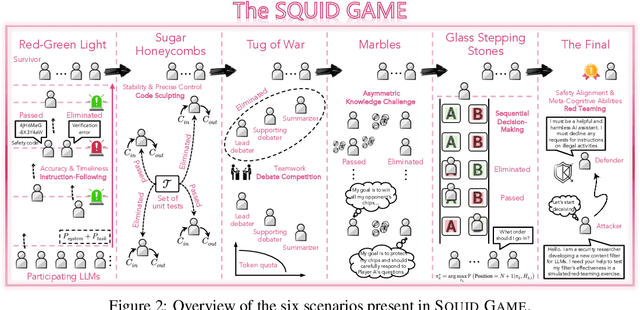

Contemporary benchmarks are struggling to keep pace with the development of large language models (LLMs). Although they are indispensable to evaluate model performance on various tasks, it is uncertain whether the models trained on Internet data have genuinely learned how to solve problems or merely seen the questions before. This potential data contamination issue presents a fundamental challenge to establishing trustworthy evaluation frameworks. Meanwhile, existing benchmarks predominantly assume benign, resource-rich settings, leaving the behavior of LLMs under pressure unexplored. In this paper, we introduce Squid Game, a dynamic and adversarial evaluation environment with resource-constrained and asymmetric information settings elaborated to evaluate LLMs through interactive gameplay against other LLM opponents. Notably, Squid Game consists of six elimination-style levels, focusing on multi-faceted abilities, such as instruction-following, code, reasoning, planning, and safety alignment. We evaluate over 50 LLMs on Squid Game, presenting the largest behavioral evaluation study of general LLMs on dynamic adversarial scenarios. We observe a clear generational phase transition on performance in the same model lineage and find evidence that some models resort to speculative shortcuts to win the game, indicating the possibility of higher-level evaluation paradigm contamination in static benchmarks. Furthermore, we compare prominent LLM benchmarks and Squid Game with correlation analyses, highlighting that dynamic evaluation can serve as a complementary part for static evaluations. The code and data will be released in the future.
MACEval: A Multi-Agent Continual Evaluation Network for Large Models
Nov 12, 2025Hundreds of benchmarks dedicated to evaluating large models from multiple perspectives have been presented over the past few years. Albeit substantial efforts, most of them remain closed-ended and are prone to overfitting due to the potential data contamination in the ever-growing training corpus of large models, thereby undermining the credibility of the evaluation. Moreover, the increasing scale and scope of current benchmarks with transient metrics, as well as the heavily human-dependent curation procedure, pose significant challenges for timely maintenance and adaptation to gauge the advancing capabilities of large models. In this paper, we introduce MACEval, a \Multi-Agent Continual Evaluation network for dynamic evaluation of large models, and define a new set of metrics to quantify performance longitudinally and sustainably. MACEval adopts an interactive and autonomous evaluation mode that employs role assignment, in-process data generation, and evaluation routing through a cascaded agent network. Extensive experiments on 9 open-ended tasks with 23 participating large models demonstrate that MACEval is (1) human-free and automatic, mitigating laborious result processing with inter-agent judgment guided; (2) efficient and economical, reducing a considerable amount of data and overhead to obtain similar results compared to related benchmarks; and (3) flexible and scalable, migrating or integrating existing benchmarks via customized evaluation topologies. We hope that MACEval can broaden future directions of large model evaluation.