 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelect Smarter, Not More: Prompt-Aware Evaluation Scheduling with Submodular Guarantees
Apr 13, 2026Automatic prompt optimization (APO) hinges on the quality of its evaluation signal, yet scoring every prompt candidate on the full training set is prohibitively expensive. Existing methods either fix a single evaluation subset before optimization begins (principled but prompt-agnostic) or adapt it heuristically during optimization (flexible but unstable and lacking formal guarantees). We observe that APO naturally maps to an online adaptive testing problem: prompts are examinees, training examples are test items, and the scheduler should select items that best discriminate among the strongest candidates. This insight motivates Prompt-Aware Online Evaluation Scheduling (POES), which integrates an IRT-based discrimination utility, a facility-location coverage term, and switching-cost-aware warm-start swaps into a unified objective that is provably monotone submodular, yielding a (1-1/e) greedy guarantee for cold starts and bounded drift for warm-start updates. An adaptive controller modulates the exploration-exploitation balance based on optimization progress. Across 36 tasks spanning three benchmark families, POES achieves the highest overall average accuracy (6.2 percent improvement over the best baseline) with negligible token overhead (approximately 4 percent) at the same evaluation budget. Moreover, principled selection at k = 20 examples matches or exceeds the performance of naive evaluation at k = 30-50, reducing token consumption by 35-60 percent, showing that selecting smarter is more effective than selecting more. Our results demonstrate that evaluation scheduling is a first-class component of APO, not an implementation detail.
Differentiable Stroke Planning with Dual Parameterization for Efficient and High-Fidelity Painting Creation
Apr 03, 2026In stroke-based rendering, search methods often get trapped in local minima due to discrete stroke placement, while differentiable optimizers lack structural awareness and produce unstructured layouts. To bridge this gap, we propose a dual representation that couples discrete polylines with continuous Bézier control points via a bidirectional mapping mechanism. This enables collaborative optimization: local gradients refine global stroke structures, while content-aware stroke proposals help escape poor local optima. Our representation further supports Gaussian-splatting-inspired initialization, enabling highly parallel stroke optimization across the image. Experiments show that our approach reduces the number of strokes by 30-50%, achieves more structurally coherent layouts, and improves reconstruction quality, while cutting optimization time by 30-40% compared to existing differentiable vectorization methods.
Learning a Latent Pulse Shape Interface for Photoinjector Laser Systems
Feb 19, 2026Controlling the longitudinal laser pulse shape in photoinjectors of Free-Electron Lasers is a powerful lever for optimizing electron beam quality, but systematic exploration of the vast design space is limited by the cost of brute-force pulse propagation simulations. We present a generative modeling framework based on Wasserstein Autoencoders to learn a differentiable latent interface between pulse shaping and downstream beam dynamics. Our empirical findings show that the learned latent space is continuous and interpretable while maintaining high-fidelity reconstructions. Pulse families such as higher-order Gaussians trace coherent trajectories, while standardizing the temporal pulse lengths shows a latent organization correlated with pulse energy. Analysis via principal components and Gaussian Mixture Models reveals a well behaved latent geometry, enabling smooth transitions between distinct pulse types via linear interpolation. The model generalizes from simulated data to real experimental pulse measurements, accurately reconstructing pulses and embedding them consistently into the learned manifold. Overall, the approach reduces reliance on expensive pulse-propagation simulations and facilitates downstream beam dynamics simulation and analysis.
ProxyImg: Towards Highly-Controllable Image Representation via Hierarchical Disentangled Proxy Embedding
Feb 02, 2026Prevailing image representation methods, including explicit representations such as raster images and Gaussian primitives, as well as implicit representations such as latent images, either suffer from representation redundancy that leads to heavy manual editing effort, or lack a direct mapping from latent variables to semantic instances or parts, making fine-grained manipulation difficult. These limitations hinder efficient and controllable image and video editing. To address these issues, we propose a hierarchical proxy-based parametric image representation that disentangles semantic, geometric, and textural attributes into independent and manipulable parameter spaces. Based on a semantic-aware decomposition of the input image, our representation constructs hierarchical proxy geometries through adaptive Bezier fitting and iterative internal region subdivision and meshing. Multi-scale implicit texture parameters are embedded into the resulting geometry-aware distributed proxy nodes, enabling continuous high-fidelity reconstruction in the pixel domain and instance- or part-independent semantic editing. In addition, we introduce a locality-adaptive feature indexing mechanism to ensure spatial texture coherence, which further supports high-quality background completion without relying on generative models. Extensive experiments on image reconstruction and editing benchmarks, including ImageNet, OIR-Bench, and HumanEdit, demonstrate that our method achieves state-of-the-art rendering fidelity with significantly fewer parameters, while enabling intuitive, interactive, and physically plausible manipulation. Moreover, by integrating proxy nodes with Position-Based Dynamics, our framework supports real-time physics-driven animation using lightweight implicit rendering, achieving superior temporal consistency and visual realism compared with generative approaches.
Tissue Classification and Whole-Slide Images Analysis via Modeling of the Tumor Microenvironment and Biological Pathways
Jan 13, 2026Automatic integration of whole slide images (WSIs) and gene expression profiles has demonstrated substantial potential in precision clinical diagnosis and cancer progression studies. However, most existing studies focus on individual gene sequences and slide level classification tasks, with limited attention to spatial transcriptomics and patch level applications. To address this limitation, we propose a multimodal network, BioMorphNet, which automatically integrates tissue morphological features and spatial gene expression to support tissue classification and differential gene analysis. For considering morphological features, BioMorphNet constructs a graph to model the relationships between target patches and their neighbors, and adjusts the response strength based on morphological and molecular level similarity, to better characterize the tumor microenvironment. In terms of multimodal interactions, BioMorphNet derives clinical pathway features from spatial transcriptomic data based on a predefined pathway database, serving as a bridge between tissue morphology and gene expression. In addition, a novel learnable pathway module is designed to automatically simulate the biological pathway formation process, providing a complementary representation to existing clinical pathways. Compared with the latest morphology gene multimodal methods, BioMorphNet's average classification metrics improve by 2.67%, 5.48%, and 6.29% for prostate cancer, colorectal cancer, and breast cancer datasets, respectively. BioMorphNet not only classifies tissue categories within WSIs accurately to support tumor localization, but also analyzes differential gene expression between tissue categories based on prediction confidence, contributing to the discovery of potential tumor biomarkers.
IKFST: IOO and KOO Algorithms for Accelerated and Precise WFST-based End-to-End Automatic Speech Recognition
Jan 01, 2026End-to-end automatic speech recognition has become the dominant paradigm in both academia and industry. To enhance recognition performance, the Weighted Finite-State Transducer (WFST) is widely adopted to integrate acoustic and language models through static graph composition, providing robust decoding and effective error correction. However, WFST decoding relies on a frame-by-frame autoregressive search over CTC posterior probabilities, which severely limits inference efficiency. Motivated by establishing a more principled compatibility between WFST decoding and CTC modeling, we systematically study the two fundamental components of CTC outputs, namely blank and non-blank frames, and identify a key insight: blank frames primarily encode positional information, while non-blank frames carry semantic content. Building on this observation, we introduce Keep-Only-One and Insert-Only-One, two decoding algorithms that explicitly exploit the structural roles of blank and non-blank frames to achieve significantly faster WFST-based inference without compromising recognition accuracy. Experiments on large-scale in-house, AISHELL-1, and LibriSpeech datasets demonstrate state-of-the-art recognition accuracy with substantially reduced decoding latency, enabling truly efficient and high-performance WFST decoding in modern speech recognition systems.
3DProxyImg: Controllable 3D-Aware Animation Synthesis from Single Image via 2D-3D Aligned Proxy Embedding
Dec 19, 20253D animation is central to modern visual media, yet traditional production pipelines remain labor-intensive, expertise-demanding, and computationally expensive. Recent AIGC-based approaches partially automate asset creation and rigging, but they either inherit the heavy costs of full 3D pipelines or rely on video-synthesis paradigms that sacrifice 3D controllability and interactivity. We focus on single-image 3D animation generation and argue that progress is fundamentally constrained by a trade-off between rendering quality and 3D control. To address this limitation, we propose a lightweight 3D animation framework that decouples geometric control from appearance synthesis. The core idea is a 2D-3D aligned proxy representation that uses a coarse 3D estimate as a structural carrier, while delegating high-fidelity appearance and view synthesis to learned image-space generative priors. This proxy formulation enables 3D-aware motion control and interaction comparable to classical pipelines, without requiring accurate geometry or expensive optimization, and naturally extends to coherent background animation. Extensive experiments demonstrate that our method achieves efficient animation generation on low-power platforms and outperforms video-based 3D animation generation in identity preservation, geometric and textural consistency, and the level of precise, interactive control it offers to users.
Neural emulation of gravity-driven geohazard runout
Dec 18, 2025Predicting geohazard runout is critical for protecting lives, infrastructure and ecosystems. Rapid mass flows, including landslides and avalanches, cause several thousand deaths across a wide range of environments, often travelling many kilometres from their source. The wide range of source conditions and material properties governing these flows makes their runout difficult to anticipate, particularly for downstream communities that may be suddenly exposed to severe impacts. Accurately predicting runout at scale requires models that are both physically realistic and computationally efficient, yet existing approaches face a fundamental speed-realism trade-off. Here we train a machine learning model to predict geohazard runout across representative real world terrains. The model predicts both flow extent and deposit thickness with high accuracy and 100 to 10,000 times faster computation than numerical solvers. It is trained on over 100,000 numerical simulations across over 10,000 real world digital elevation model chips and reproduces key physical behaviours, including avulsion and deposition patterns, while generalizing across different flow types, sizes and landscapes. Our results demonstrate that neural emulation enables rapid, spatially resolved runout prediction across diverse real world terrains, opening new opportunities for disaster risk reduction and impact-based forecasting. These results highlight neural emulation as a promising pathway for extending physically realistic geohazard modelling to spatial and temporal scales relevant for large scale early warning systems.
CoDA: A Context-Decoupled Hierarchical Agent with Reinforcement Learning
Dec 14, 2025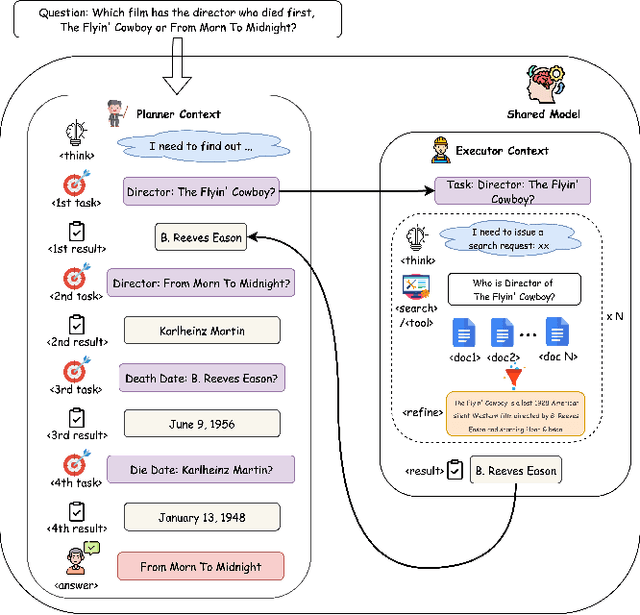
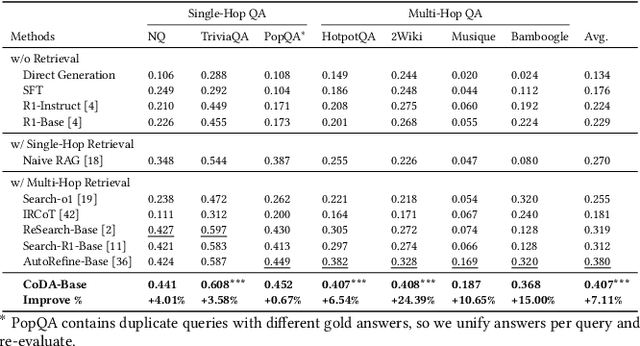
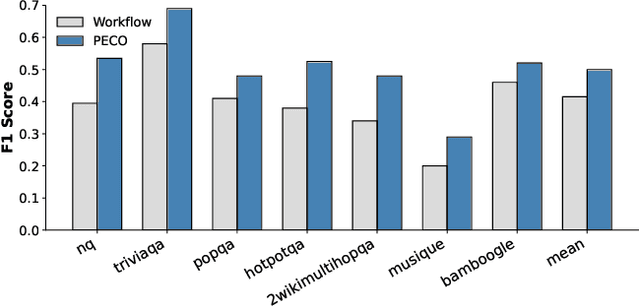
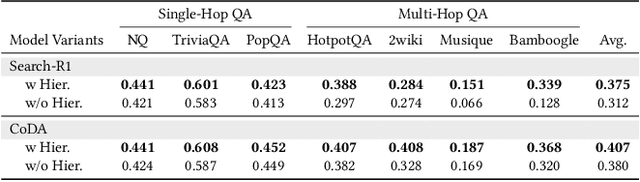
Large Language Model (LLM) agents trained with reinforcement learning (RL) show great promise for solving complex, multi-step tasks. However, their performance is often crippled by "Context Explosion", where the accumulation of long text outputs overwhelms the model's context window and leads to reasoning failures. To address this, we introduce CoDA, a Context-Decoupled hierarchical Agent, a simple but effective reinforcement learning framework that decouples high-level planning from low-level execution. It employs a single, shared LLM backbone that learns to operate in two distinct, contextually isolated roles: a high-level Planner that decomposes tasks within a concise strategic context, and a low-level Executor that handles tool interactions in an ephemeral, isolated workspace. We train this unified agent end-to-end using PECO (Planner-Executor Co-Optimization), a reinforcement learning methodology that applies a trajectory-level reward to jointly optimize both roles, fostering seamless collaboration through context-dependent policy updates. Extensive experiments demonstrate that CoDA achieves significant performance improvements over state-of-the-art baselines on complex multi-hop question-answering benchmarks, and it exhibits strong robustness in long-context scenarios, maintaining stable performance while all other baselines suffer severe degradation, thus further validating the effectiveness of our hierarchical design in mitigating context overload.
PaintFlow: A Unified Framework for Interactive Oil Paintings Editing and Generation
Dec 09, 2025Oil painting, as a high-level medium that blends human abstract thinking with artistic expression, poses substantial challenges for digital generation and editing due to its intricate brushstroke dynamics and stylized characteristics. Existing generation and editing techniques are often constrained by the distribution of training data and primarily focus on modifying real photographs. In this work, we introduce a unified multimodal framework for oil painting generation and editing. The proposed system allows users to incorporate reference images for precise semantic control, hand-drawn sketches for spatial structure alignment, and natural language prompts for high-level semantic guidance, while consistently maintaining a unified painting style across all outputs. Our method achieves interactive oil painting creation through three crucial technical advancements. First, we enhance the training stage with spatial alignment and semantic enhancement conditioning strategy, which map masks and sketches into spatial constraints, and encode contextual embedding from reference images and text into feature constraints, enabling object-level semantic alignment. Second, to overcome data scarcity, we propose a self-supervised style transfer pipeline based on Stroke-Based Rendering (SBR), which simulates the inpainting dynamics of oil painting restoration, converting real images into stylized oil paintings with preserved brushstroke textures to construct a large-scale paired training dataset. Finally, during inference, we integrate features using the AdaIN operator to ensure stylistic consistency. Extensive experiments demonstrate that our interactive system enables fine-grained editing while preserving the artistic qualities of oil paintings, achieving an unprecedented level of imagination realization in stylized oil paintings generation and editing.