 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAACR-Bench: Evaluating Automatic Code Review with Holistic Repository-Level Context
Jan 27, 2026High-quality evaluation benchmarks are pivotal for deploying Large Language Models (LLMs) in Automated Code Review (ACR). However, existing benchmarks suffer from two critical limitations: first, the lack of multi-language support in repository-level contexts, which restricts the generalizability of evaluation results; second, the reliance on noisy, incomplete ground truth derived from raw Pull Request (PR) comments, which constrains the scope of issue detection. To address these challenges, we introduce AACR-Bench a comprehensive benchmark that provides full cross-file context across multiple programming languages. Unlike traditional datasets, AACR-Bench employs an "AI-assisted, Expert-verified" annotation pipeline to uncover latent defects often overlooked in original PRs, resulting in a 285\% increase in defect coverage. Extensive evaluations of mainstream LLMs on AACR-Bench reveal that previous assessments may have either misjudged or only partially captured model capabilities due to data limitations. Our work establishes a more rigorous standard for ACR evaluation and offers new insights on LLM based ACR, i.e., the granularity/level of context and the choice of retrieval methods significantly impact ACR performance, and this influence varies depending on the LLM, programming language, and the LLM usage paradigm e.g., whether an Agent architecture is employed. The code, data, and other artifacts of our evaluation set are available at https://github.com/alibaba/aacr-bench .
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Self-Prediction for Joint Instance and Semantic Segmentation of Point Clouds
Jul 27, 2020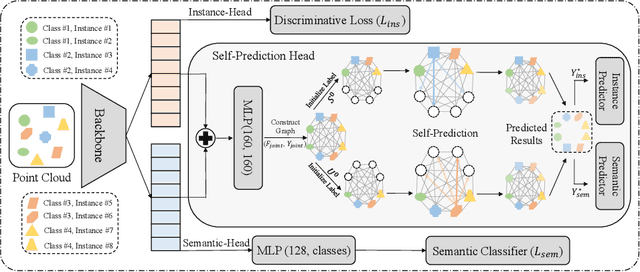
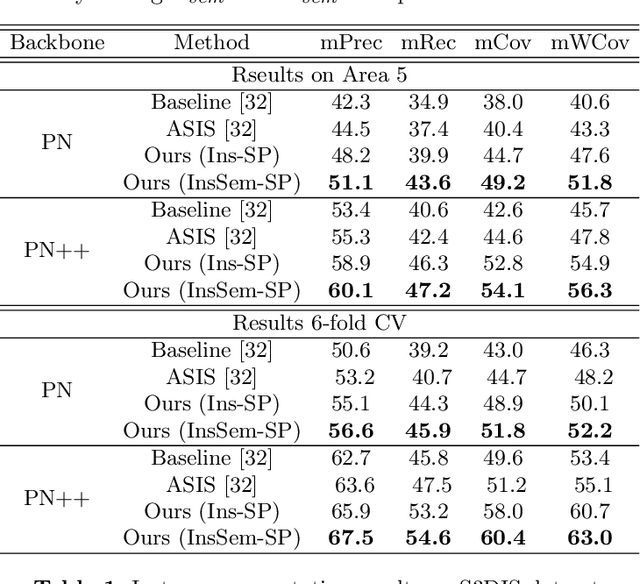
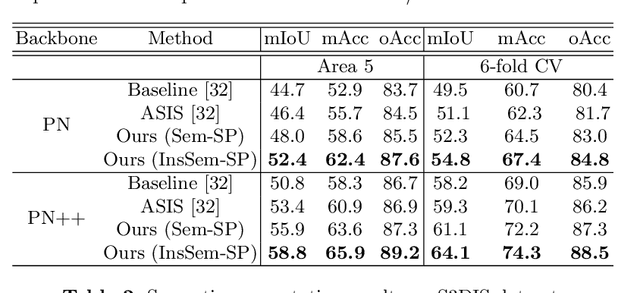
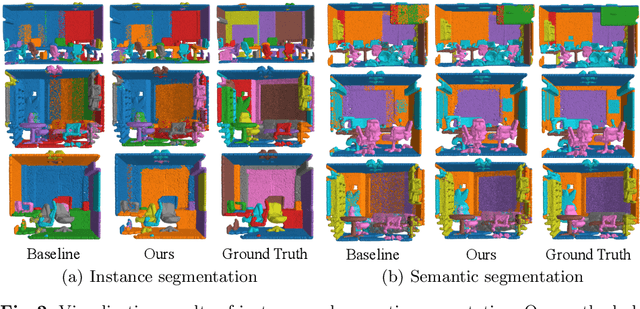
We develop a novel learning scheme named Self-Prediction for 3D instance and semantic segmentation of point clouds. Distinct from most existing methods that focus on designing convolutional operators, our method designs a new learning scheme to enhance point relation exploring for better segmentation. More specifically, we divide a point cloud sample into two subsets and construct a complete graph based on their representations. Then we use label propagation algorithm to predict labels of one subset when given labels of the other subset. By training with this Self-Prediction task, the backbone network is constrained to fully explore relational context/geometric/shape information and learn more discriminative features for segmentation. Moreover, a general associated framework equipped with our Self-Prediction scheme is designed for enhancing instance and semantic segmentation simultaneously, where instance and semantic representations are combined to perform Self-Prediction. Through this way, instance and semantic segmentation are collaborated and mutually reinforced. Significant performance improvements on instance and semantic segmentation compared with baseline are achieved on S3DIS and ShapeNet. Our method achieves state-of-the-art instance segmentation results on S3DIS and comparable semantic segmentation results compared with state-of-the-arts on S3DIS and ShapeNet when we only take PointNet++ as the backbone network.
Complex Sequential Understanding through the Awareness of Spatial and Temporal Concepts
May 30, 2020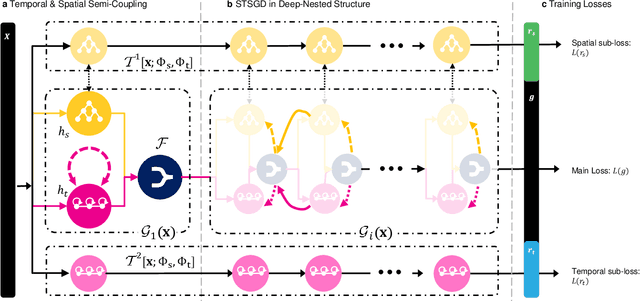
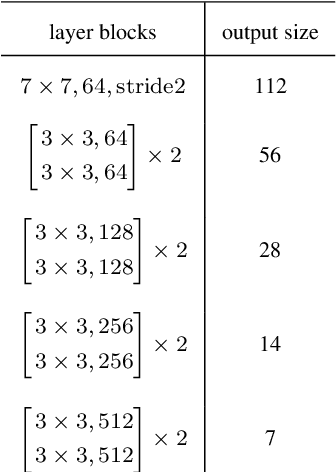
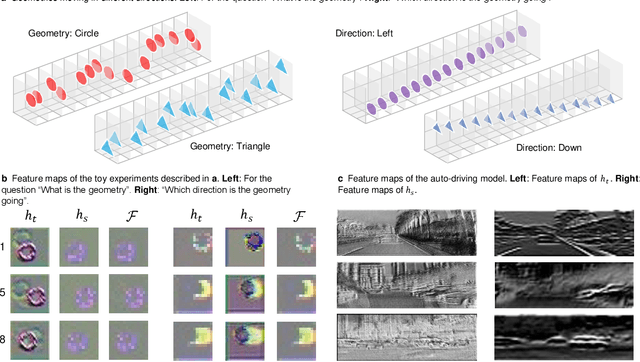
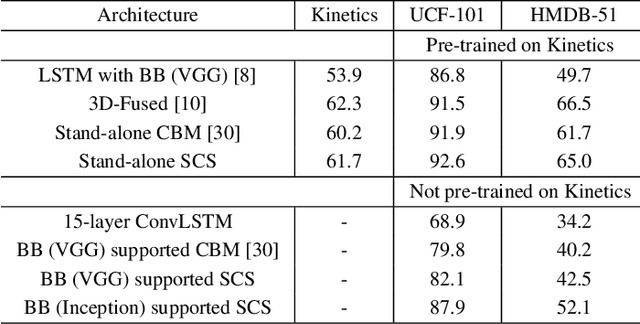
Understanding sequential information is a fundamental task for artificial intelligence. Current neural networks attempt to learn spatial and temporal information as a whole, limited their abilities to represent large scale spatial representations over long-range sequences. Here, we introduce a new modeling strategy called Semi-Coupled Structure (SCS), which consists of deep neural networks that decouple the complex spatial and temporal concepts learning. Semi-Coupled Structure can learn to implicitly separate input information into independent parts and process these parts respectively. Experiments demonstrate that a Semi-Coupled Structure can successfully annotate the outline of an object in images sequentially and perform video action recognition. For sequence-to-sequence problems, a Semi-Coupled Structure can predict future meteorological radar echo images based on observed images. Taken together, our results demonstrate that a Semi-Coupled Structure has the capacity to improve the performance of LSTM-like models on large scale sequential tasks.
* 15 pages, 5 figures, 8 tables