 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysiology as Language: Translating Respiration to Sleep EEG
Jan 31, 2026This paper introduces a novel cross-physiology translation task: synthesizing sleep electroencephalography (EEG) from respiration signals. To address the significant complexity gap between the two modalities, we propose a waveform-conditional generative framework that preserves fine-grained respiratory dynamics while constraining the EEG target space through discrete tokenization. Trained on over 28,000 individuals, our model achieves a 7% Mean Absolute Error in EEG spectrogram reconstruction. Beyond reconstruction, the synthesized EEG supports downstream tasks with performance comparable to ground truth EEG on age estimation (MAE 5.0 vs. 5.1 years), sex detection (AUROC 0.81 vs. 0.82), and sleep staging (Accuracy 0.84 vs. 0.88), significantly outperforming baselines trained directly on breathing. Finally, we demonstrate that the framework generalizes to contactless sensing by synthesizing EEG from wireless radio-frequency reflections, highlighting the feasibility of remote, non-contact neurological assessment during sleep.
RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning
May 21, 2025Reinforcement learning (RL) has recently emerged as a compelling approach for enhancing the reasoning capabilities of large language models (LLMs), where an LLM generator serves as a policy guided by a verifier (reward model). However, current RL post-training methods for LLMs typically use verifiers that are fixed (rule-based or frozen pretrained) or trained discriminatively via supervised fine-tuning (SFT). Such designs are susceptible to reward hacking and generalize poorly beyond their training distributions. To overcome these limitations, we propose Tango, a novel framework that uses RL to concurrently train both an LLM generator and a verifier in an interleaved manner. A central innovation of Tango is its generative, process-level LLM verifier, which is trained via RL and co-evolves with the generator. Importantly, the verifier is trained solely based on outcome-level verification correctness rewards without requiring explicit process-level annotations. This generative RL-trained verifier exhibits improved robustness and superior generalization compared to deterministic or SFT-trained verifiers, fostering effective mutual reinforcement with the generator. Extensive experiments demonstrate that both components of Tango achieve state-of-the-art results among 7B/8B-scale models: the generator attains best-in-class performance across five competition-level math benchmarks and four challenging out-of-domain reasoning tasks, while the verifier leads on the ProcessBench dataset. Remarkably, both components exhibit particularly substantial improvements on the most difficult mathematical reasoning problems. Code is at: https://github.com/kaiwenzha/rl-tango.
REG: Rectified Gradient Guidance for Conditional Diffusion Models
Jan 31, 2025Guidance techniques are simple yet effective for improving conditional generation in diffusion models. Albeit their empirical success, the practical implementation of guidance diverges significantly from its theoretical motivation. In this paper, we reconcile this discrepancy by replacing the scaled marginal distribution target, which we prove theoretically invalid, with a valid scaled joint distribution objective. Additionally, we show that the established guidance implementations are approximations to the intractable optimal solution under no future foresight constraint. Building on these theoretical insights, we propose rectified gradient guidance (REG), a versatile enhancement designed to boost the performance of existing guidance methods. Experiments on 1D and 2D demonstrate that REG provides a better approximation to the optimal solution than prior guidance techniques, validating the proposed theoretical framework. Extensive experiments on class-conditional ImageNet and text-to-image generation tasks show that incorporating REG consistently improves FID and Inception/CLIP scores across various settings compared to its absence.
Language-Guided Image Tokenization for Generation
Dec 08, 2024



Image tokenization, the process of transforming raw image pixels into a compact low-dimensional latent representation, has proven crucial for scalable and efficient image generation. However, mainstream image tokenization methods generally have limited compression rates, making high-resolution image generation computationally expensive. To address this challenge, we propose to leverage language for efficient image tokenization, and we call our method Text-Conditioned Image Tokenization (TexTok). TexTok is a simple yet effective tokenization framework that leverages language to provide high-level semantics. By conditioning the tokenization process on descriptive text captions, TexTok allows the tokenization process to focus on encoding fine-grained visual details into latent tokens, leading to enhanced reconstruction quality and higher compression rates. Compared to the conventional tokenizer without text conditioning, TexTok achieves average reconstruction FID improvements of 29.2% and 48.1% on ImageNet-256 and -512 benchmarks respectively, across varying numbers of tokens. These tokenization improvements consistently translate to 16.3% and 34.3% average improvements in generation FID. By simply replacing the tokenizer in Diffusion Transformer (DiT) with TexTok, our system can achieve a 93.5x inference speedup while still outperforming the original DiT using only 32 tokens on ImageNet-512. TexTok with a vanilla DiT generator achieves state-of-the-art FID scores of 1.46 and 1.62 on ImageNet-256 and -512 respectively. Furthermore, we demonstrate TexTok's superiority on the text-to-image generation task, effectively utilizing the off-the-shelf text captions in tokenization.
Supervised Contrastive Regression
Oct 03, 2022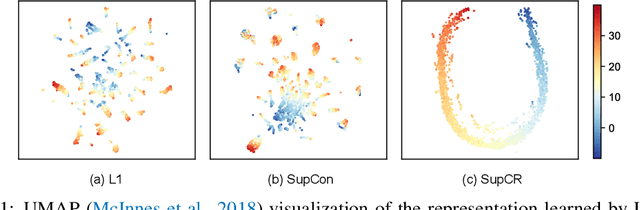
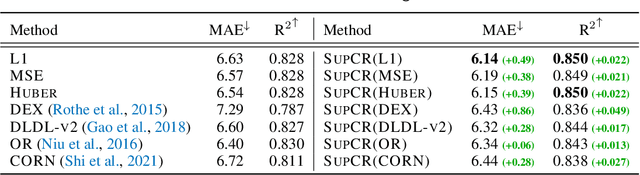
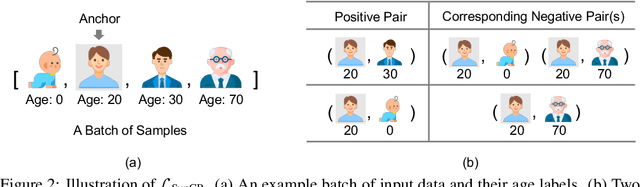
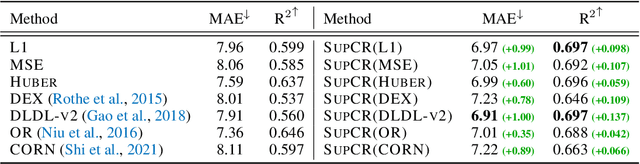
Deep regression models typically learn in an end-to-end fashion and do not explicitly try to learn a regression-aware representation. Their representations tend to be fragmented and fail to capture the continuous nature of regression tasks. In this paper, we propose Supervised Contrastive Regression (SupCR), a framework that learns a regression-aware representation by contrasting samples against each other based on their target distance. SupCR is orthogonal to existing regression models, and can be used in combination with such models to improve performance. Extensive experiments using five real-world regression datasets that span computer vision, human-computer interaction, and healthcare show that using SupCR achieves the state-of-the-art performance and consistently improves prior regression baselines on all datasets, tasks, and input modalities. SupCR also improves robustness to data corruptions, resilience to reduced training data, performance on transfer learning, and generalization to unseen targets.
Indiscriminate Poisoning Attacks on Unsupervised Contrastive Learning
Feb 22, 2022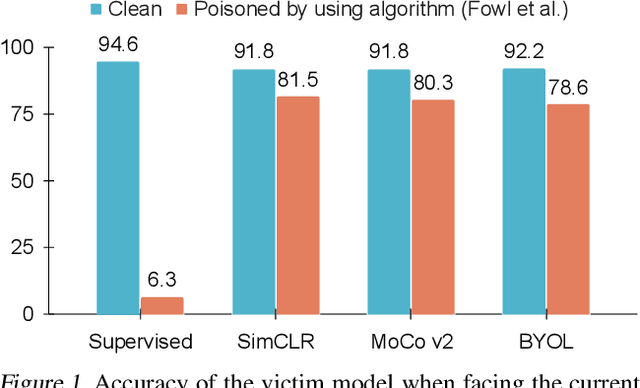
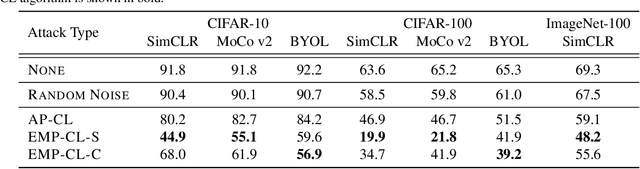
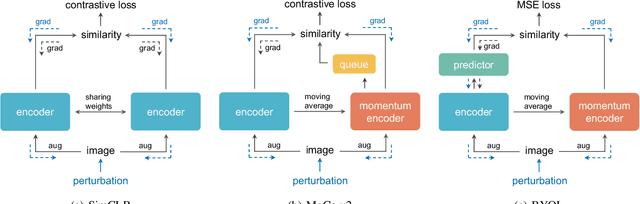

Indiscriminate data poisoning attacks are quite effective against supervised learning. However, not much is known about their impact on unsupervised contrastive learning (CL). This paper is the first to consider indiscriminate data poisoning attacks on contrastive learning, demonstrating the feasibility of such attacks, and their differences from indiscriminate poisoning of supervised learning. We also highlight differences between contrastive learning algorithms, and show that some algorithms (e.g., SimCLR) are more vulnerable than others (e.g., MoCo). We differentiate between two types of data poisoning attacks: sample-wise attacks, which add specific noise to each image, cause the largest drop in accuracy, but do not transfer well across SimCLR, MoCo, and BYOL. In contrast, attacks that use class-wise noise, though cause a smaller drop in accuracy, transfer well across different CL algorithms. Finally, we show that a new data augmentation based on matrix completion can be highly effective in countering data poisoning attacks on unsupervised contrastive learning.
Unsupervised Image Transformation Learning via Generative Adversarial Networks
Mar 13, 2021
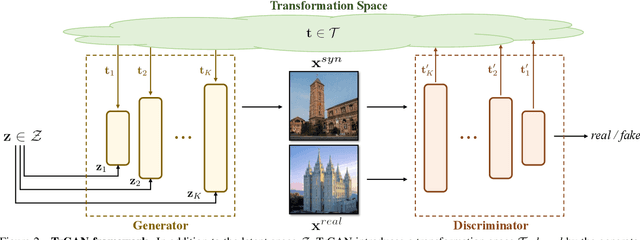


In this work, we study the image transformation problem by learning the underlying transformations from a collection of images using Generative Adversarial Networks (GANs). Specifically, we propose an unsupervised learning framework, termed as TrGAN, to project images onto a transformation space that is shared by the generator and the discriminator. Any two points in this projected space define a transformation that can guide the image generation process, leading to continuous semantic change. By projecting a pair of images onto the transformation space, we are able to adequately extract the semantic variation between them and further apply the extracted semantic to facilitating image editing, including not only transferring image styles (e.g., changing day to night) but also manipulating image contents (e.g., adding clouds in the sky). Code and models are available at https://genforce.github.io/trgan.
Delving into Deep Imbalanced Regression
Feb 18, 2021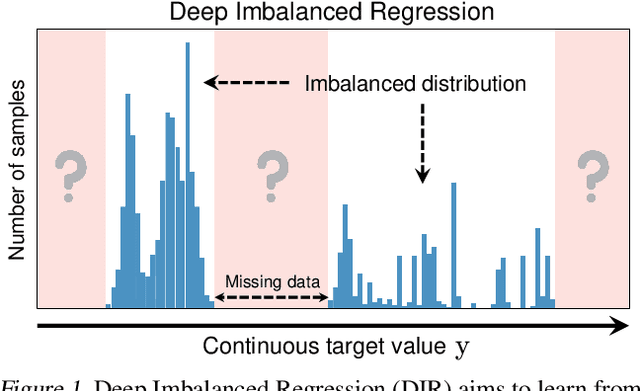
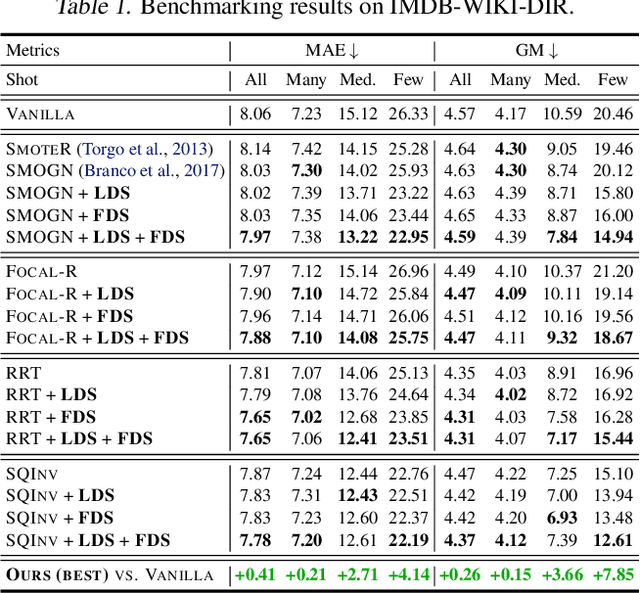
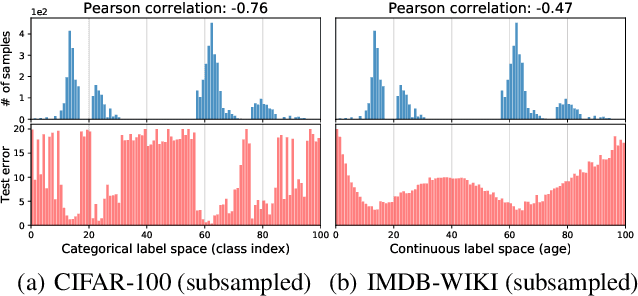
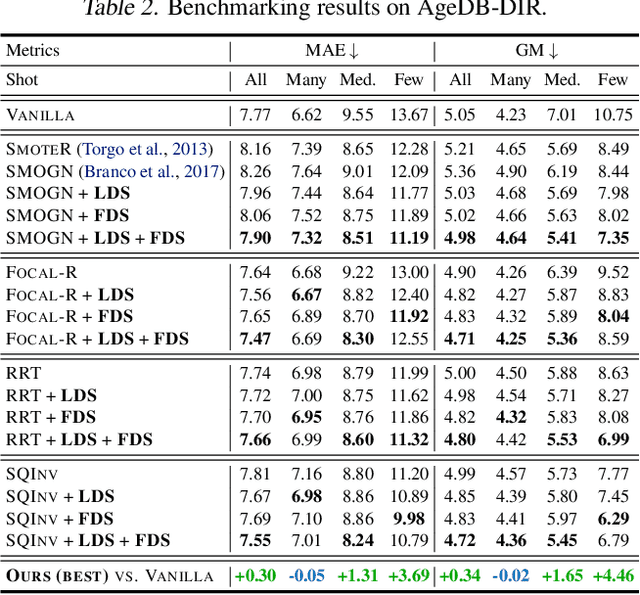
Real-world data often exhibit imbalanced distributions, where certain target values have significantly fewer observations. Existing techniques for dealing with imbalanced data focus on targets with categorical indices, i.e., different classes. However, many tasks involve continuous targets, where hard boundaries between classes do not exist. We define Deep Imbalanced Regression (DIR) as learning from such imbalanced data with continuous targets, dealing with potential missing data for certain target values, and generalizing to the entire target range. Motivated by the intrinsic difference between categorical and continuous label space, we propose distribution smoothing for both labels and features, which explicitly acknowledges the effects of nearby targets, and calibrates both label and learned feature distributions. We curate and benchmark large-scale DIR datasets from common real-world tasks in computer vision, natural language processing, and healthcare domains. Extensive experiments verify the superior performance of our strategies. Our work fills the gap in benchmarks and techniques for practical imbalanced regression problems. Code and data are available at https://github.com/YyzHarry/imbalanced-regression.
Complex Sequential Understanding through the Awareness of Spatial and Temporal Concepts
May 30, 2020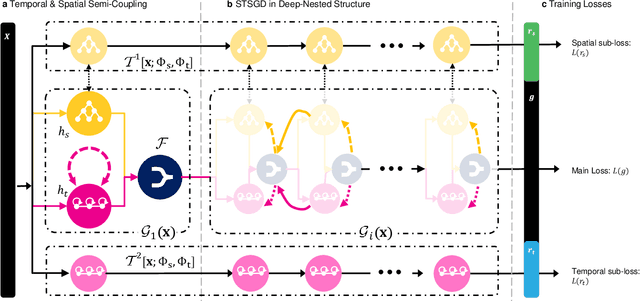
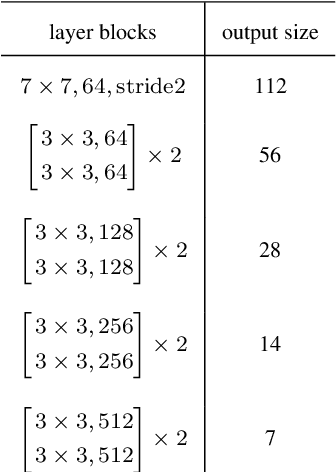
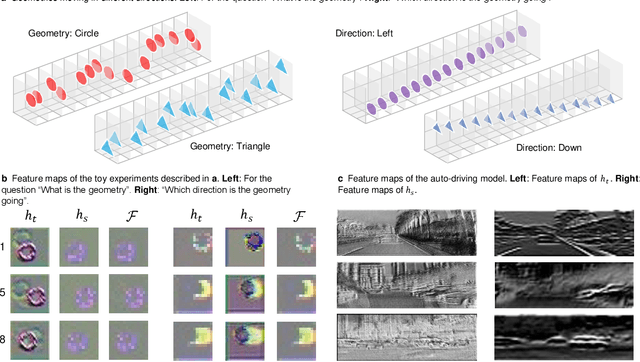
Understanding sequential information is a fundamental task for artificial intelligence. Current neural networks attempt to learn spatial and temporal information as a whole, limited their abilities to represent large scale spatial representations over long-range sequences. Here, we introduce a new modeling strategy called Semi-Coupled Structure (SCS), which consists of deep neural networks that decouple the complex spatial and temporal concepts learning. Semi-Coupled Structure can learn to implicitly separate input information into independent parts and process these parts respectively. Experiments demonstrate that a Semi-Coupled Structure can successfully annotate the outline of an object in images sequentially and perform video action recognition. For sequence-to-sequence problems, a Semi-Coupled Structure can predict future meteorological radar echo images based on observed images. Taken together, our results demonstrate that a Semi-Coupled Structure has the capacity to improve the performance of LSTM-like models on large scale sequential tasks.
* 15 pages, 5 figures, 8 tables
Deep RNN Framework for Visual Sequential Applications
Nov 28, 2018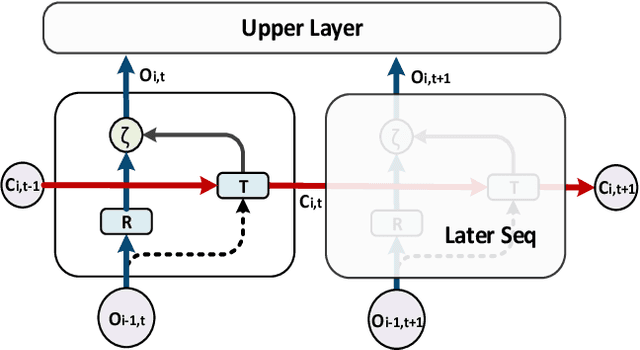
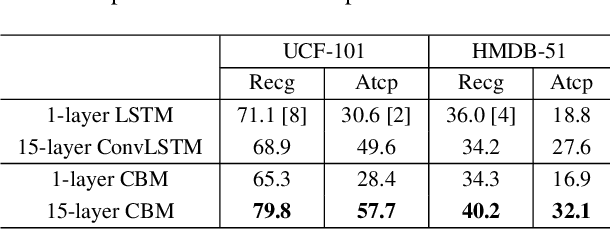
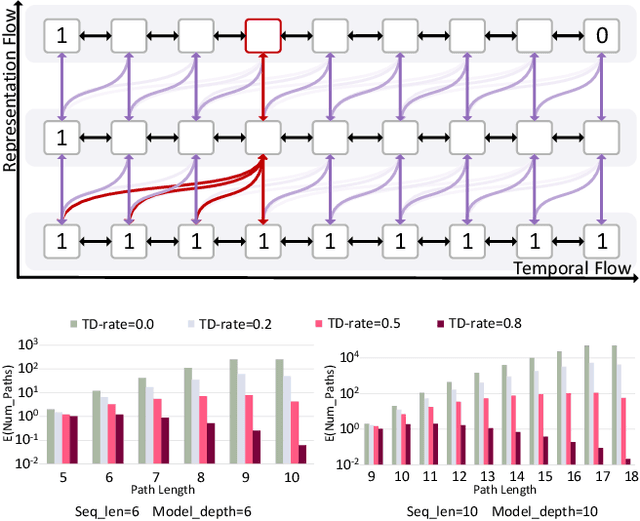

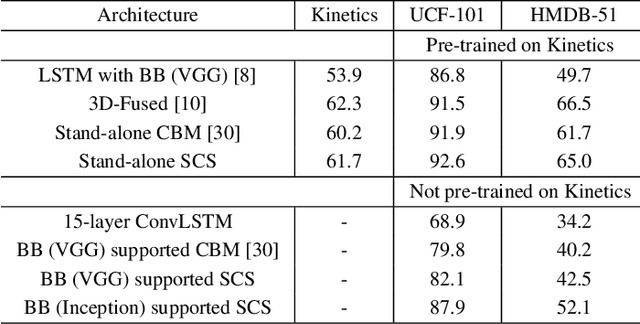
Extracting temporal and representation features efficiently plays a pivotal role in understanding visual sequence information. To deal with this, we propose a new recurrent neural framework that can be stacked deep effectively. There are mainly two novel designs in our deep RNN framework: one is a new RNN module called Representation Bridge Module (RBM) which splits the information flowing along the sequence (temporal direction) and along depth (spatial representation direction), making it easier to train when building deep by balancing these two directions; the other is the Overlap Coherence Training Scheme that reduces the training complexity for long visual sequential tasks on account of the limitation of computing resources. We provide empirical evidence to show that our deep RNN framework is easy to optimize and can gain accuracy from the increased depth on several visual sequence problems. On these tasks, we evaluate our deep RNN framework with 15 layers, 7 times than conventional RNN networks, but it is still easy to train. Our deep framework achieves more than 11% relative improvements over shallow RNN models on Kinetics, UCF-101, and HMDB-51 for video classification. For auxiliary annotation, after replacing the shallow RNN part of Polygon-RNN with our 15-layer deep RBM, the performance improves by 14.7%. For video future prediction, our deep RNN improves the state-of-the-art shallow model's performance by 2.4% on PSNR and SSIM. The code and trained models will publish accompanied by this paper.