 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndiscriminate Poisoning Attacks on Unsupervised Contrastive Learning
Paper and Code
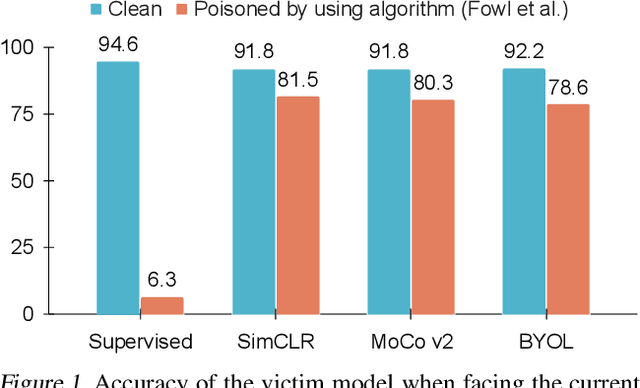
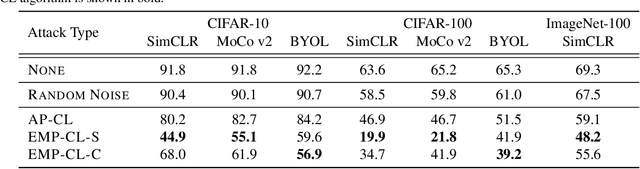
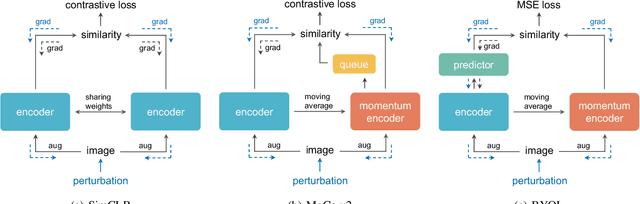

Indiscriminate data poisoning attacks are quite effective against supervised learning. However, not much is known about their impact on unsupervised contrastive learning (CL). This paper is the first to consider indiscriminate data poisoning attacks on contrastive learning, demonstrating the feasibility of such attacks, and their differences from indiscriminate poisoning of supervised learning. We also highlight differences between contrastive learning algorithms, and show that some algorithms (e.g., SimCLR) are more vulnerable than others (e.g., MoCo). We differentiate between two types of data poisoning attacks: sample-wise attacks, which add specific noise to each image, cause the largest drop in accuracy, but do not transfer well across SimCLR, MoCo, and BYOL. In contrast, attacks that use class-wise noise, though cause a smaller drop in accuracy, transfer well across different CL algorithms. Finally, we show that a new data augmentation based on matrix completion can be highly effective in countering data poisoning attacks on unsupervised contrastive learning.