 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLEF: EEG Foundation Model for Learning Clinical Semantics
May 11, 2026Clinical EEG interpretation requires reasoning over full EEG sessions and integrating signal patterns with clinical context. Existing EEG foundation models are largely designed for short-window decoding and do not incorporate clinical context. We introduce CLEF, a clinically grounded long-context EEG foundation model. CLEF represents EEG sessions as 3D multitaper spectrogram tokens, enabling tractable Transformer modeling at session scale, and aligns embeddings with neurologist reports and structured EHR data through contrastive objectives. We evaluate CLEF on a new 234-task benchmark spanning disease phenotypes, medication exposures, and EEG findings, with more than 260k EEG sessions from over 108k patients. CLEF outperforms prior EEG foundation models on 229 of 234 tasks, improving mean AUROC from 0.65 to 0.74. Reconstruction-only pretraining surpasses prior EEG foundation models, while report and EHR alignment yields further gains. Held-out concept and external-cohort experiments suggest that these representations transfer beyond observed alignment targets. These results support session-scale, clinically grounded representation learning as a promising foundation-model paradigm for clinical EEG.
WavesFM: Hierarchical Representation Learning for Longitudinal Wearable Sensor Waveforms
May 09, 2026Wearable sensors enable the continuous acquisition of high-resolution physiological waveforms, such as photoplethysmography and accelerometry, under free-living conditions. However, inferring health-related phenotypes from these signals presents significant challenges due to high sampling frequencies, multimodal dependencies, and extreme sequence lengths (e.g., weeks of recordings), compounded by a scarcity of ground-truth labels. To address these challenges, existing self-supervised learning (SSL) methodologies typically follow two paradigms: (1) learning rich morphological representations from short waveform segments while collapsing longitudinal dynamics through simple aggregation, or (2) modeling behavioral patterns from coarse, hand-crafted features (e.g. heart rate, step counts) spanning longer horizons but foregoing subtle, predictive signatures in raw waveforms. To bridge this gap, we propose WavesFM, a foundation model utilizing a two-stage SSL framework for longitudinal physiological data. Specifically, we decompose the learning problem into two stages: first, a segment-level encoder is pretrained to extract local embeddings from short waveforms; subsequently, a temporal encoder is trained to model the sequence of these embeddings across a multi-day horizon. This hierarchical approach overcomes the computational complexity of high-resolution, long-sequence data, allowing the overall model to capture both local signal semantics and the complex circadian and inter-day variations governing physiological dynamics. Pretrained on over 6.8M hours (N=324k individuals) of recordings for the first stage and 5.3M hours (N=10k) for the second stage, WavesFM demonstrates superior performance across 58 diverse tasks spanning demographics, lifestyle, health conditions, and medications.
DREAM: Where Visual Understanding Meets Text-to-Image Generation
Mar 03, 2026Unifying visual representation learning and text-to-image (T2I) generation within a single model remains a central challenge in multimodal learning. We introduce DREAM, a unified framework that jointly optimizes discriminative and generative objectives, while learning strong visual representations. DREAM is built on two key techniques: During training, Masking Warmup, a progressive masking schedule, begins with minimal masking to establish the contrastive alignment necessary for representation learning, then gradually transitions to full masking for stable generative training. At inference, DREAM employs Semantically Aligned Decoding to align partially masked image candidates with the target text and select the best one for further decoding, improving text-image fidelity (+6.3%) without external rerankers. Trained solely on CC12M, DREAM achieves 72.7% ImageNet linear-probing accuracy (+1.1% over CLIP) and an FID of 4.25 (+6.2% over FLUID), with consistent gains in few-shot classification, semantic segmentation, and depth estimation. These results demonstrate that discriminative and generative objectives can be synergistic, allowing unified multimodal models that excel at both visual understanding and generation.
Physiology as Language: Translating Respiration to Sleep EEG
Jan 31, 2026This paper introduces a novel cross-physiology translation task: synthesizing sleep electroencephalography (EEG) from respiration signals. To address the significant complexity gap between the two modalities, we propose a waveform-conditional generative framework that preserves fine-grained respiratory dynamics while constraining the EEG target space through discrete tokenization. Trained on over 28,000 individuals, our model achieves a 7% Mean Absolute Error in EEG spectrogram reconstruction. Beyond reconstruction, the synthesized EEG supports downstream tasks with performance comparable to ground truth EEG on age estimation (MAE 5.0 vs. 5.1 years), sex detection (AUROC 0.81 vs. 0.82), and sleep staging (Accuracy 0.84 vs. 0.88), significantly outperforming baselines trained directly on breathing. Finally, we demonstrate that the framework generalizes to contactless sensing by synthesizing EEG from wireless radio-frequency reflections, highlighting the feasibility of remote, non-contact neurological assessment during sleep.
Single-Teacher View Augmentation: Boosting Knowledge Distillation via Angular Diversity
Oct 26, 2025Knowledge Distillation (KD) aims to train a lightweight student model by transferring knowledge from a large, high-capacity teacher. Recent studies have shown that leveraging diverse teacher perspectives can significantly improve distillation performance; however, achieving such diversity typically requires multiple teacher networks, leading to high computational costs. In this work, we propose a novel cost-efficient knowledge augmentation method for KD that generates diverse multi-views by attaching multiple branches to a single teacher. To ensure meaningful semantic variation across multi-views, we introduce two angular diversity objectives: 1) constrained inter-angle diversify loss, which maximizes angles between augmented views while preserving proximity to the original teacher output, and 2) intra-angle diversify loss, which encourages an even distribution of views around the original output. The ensembled knowledge from these angularly diverse views, along with the original teacher, is distilled into the student. We further theoretically demonstrate that our objectives increase the diversity among ensemble members and thereby reduce the upper bound of the ensemble's expected loss, leading to more effective distillation. Experimental results show that our method surpasses an existing knowledge augmentation method across diverse configurations. Moreover, the proposed method is compatible with other KD frameworks in a plug-and-play fashion, providing consistent improvements in generalization performance.
RL Tango: Reinforcing Generator and Verifier Together for Language Reasoning
May 21, 2025Reinforcement learning (RL) has recently emerged as a compelling approach for enhancing the reasoning capabilities of large language models (LLMs), where an LLM generator serves as a policy guided by a verifier (reward model). However, current RL post-training methods for LLMs typically use verifiers that are fixed (rule-based or frozen pretrained) or trained discriminatively via supervised fine-tuning (SFT). Such designs are susceptible to reward hacking and generalize poorly beyond their training distributions. To overcome these limitations, we propose Tango, a novel framework that uses RL to concurrently train both an LLM generator and a verifier in an interleaved manner. A central innovation of Tango is its generative, process-level LLM verifier, which is trained via RL and co-evolves with the generator. Importantly, the verifier is trained solely based on outcome-level verification correctness rewards without requiring explicit process-level annotations. This generative RL-trained verifier exhibits improved robustness and superior generalization compared to deterministic or SFT-trained verifiers, fostering effective mutual reinforcement with the generator. Extensive experiments demonstrate that both components of Tango achieve state-of-the-art results among 7B/8B-scale models: the generator attains best-in-class performance across five competition-level math benchmarks and four challenging out-of-domain reasoning tasks, while the verifier leads on the ProcessBench dataset. Remarkably, both components exhibit particularly substantial improvements on the most difficult mathematical reasoning problems. Code is at: https://github.com/kaiwenzha/rl-tango.
Quantifying Itch and its Impact on Sleep Using Machine Learning and Radio Signals
Jan 09, 2025



Chronic itch affects 13% of the US population, is highly debilitating, and underlies many medical conditions. A major challenge in clinical care and new therapeutics development is the lack of an objective measure for quantifying itch, leading to reliance on subjective measures like patients' self-assessment of itch severity. In this paper, we show that a home radio device paired with artificial intelligence (AI) can concurrently capture scratching and evaluate its impact on sleep quality by analyzing radio signals bouncing in the environment. The device eliminates the need for wearable sensors or skin contact, enabling monitoring of chronic itch over extended periods at home without burdening patients or interfering with their skin condition. To validate the technology, we conducted an observational clinical study of chronic pruritus patients, monitored at home for one month using both the radio device and an infrared camera. Comparing the output of the device to ground truth data from the camera demonstrates its feasibility and accuracy (ROC AUC = 0.997, sensitivity = 0.825, specificity = 0.997). The results reveal a significant correlation between scratching and low sleep quality, manifested as a reduction in sleep efficiency (R = 0.6, p < 0.001) and an increase in sleep latency (R = 0.68, p < 0.001). Our study underscores the potential of passive, long-term, at-home monitoring of chronic scratching and its sleep implications, offering a valuable tool for both clinical care of chronic itch patients and pharmaceutical clinical trials.
Language-Guided Image Tokenization for Generation
Dec 08, 2024



Image tokenization, the process of transforming raw image pixels into a compact low-dimensional latent representation, has proven crucial for scalable and efficient image generation. However, mainstream image tokenization methods generally have limited compression rates, making high-resolution image generation computationally expensive. To address this challenge, we propose to leverage language for efficient image tokenization, and we call our method Text-Conditioned Image Tokenization (TexTok). TexTok is a simple yet effective tokenization framework that leverages language to provide high-level semantics. By conditioning the tokenization process on descriptive text captions, TexTok allows the tokenization process to focus on encoding fine-grained visual details into latent tokens, leading to enhanced reconstruction quality and higher compression rates. Compared to the conventional tokenizer without text conditioning, TexTok achieves average reconstruction FID improvements of 29.2% and 48.1% on ImageNet-256 and -512 benchmarks respectively, across varying numbers of tokens. These tokenization improvements consistently translate to 16.3% and 34.3% average improvements in generation FID. By simply replacing the tokenizer in Diffusion Transformer (DiT) with TexTok, our system can achieve a 93.5x inference speedup while still outperforming the original DiT using only 32 tokens on ImageNet-512. TexTok with a vanilla DiT generator achieves state-of-the-art FID scores of 1.46 and 1.62 on ImageNet-256 and -512 respectively. Furthermore, we demonstrate TexTok's superiority on the text-to-image generation task, effectively utilizing the off-the-shelf text captions in tokenization.
Contactless Polysomnography: What Radio Waves Tell Us about Sleep
May 20, 2024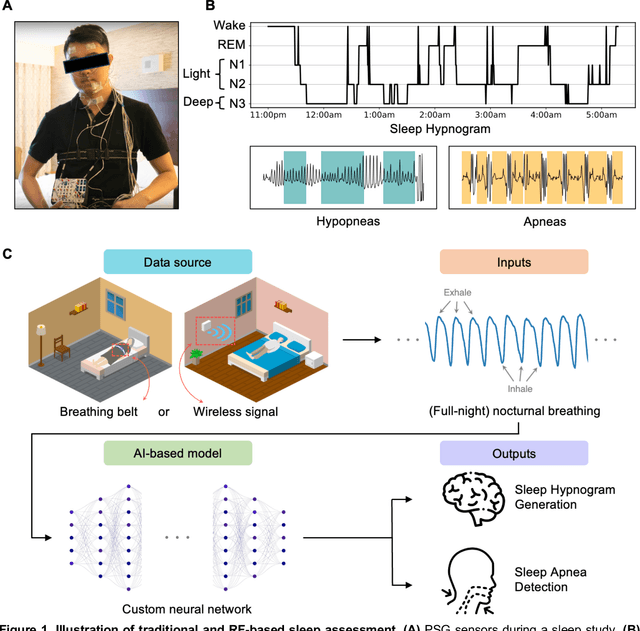
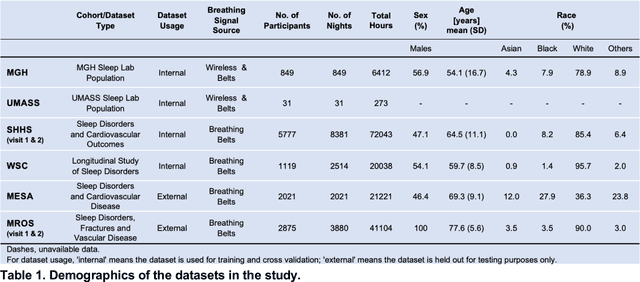
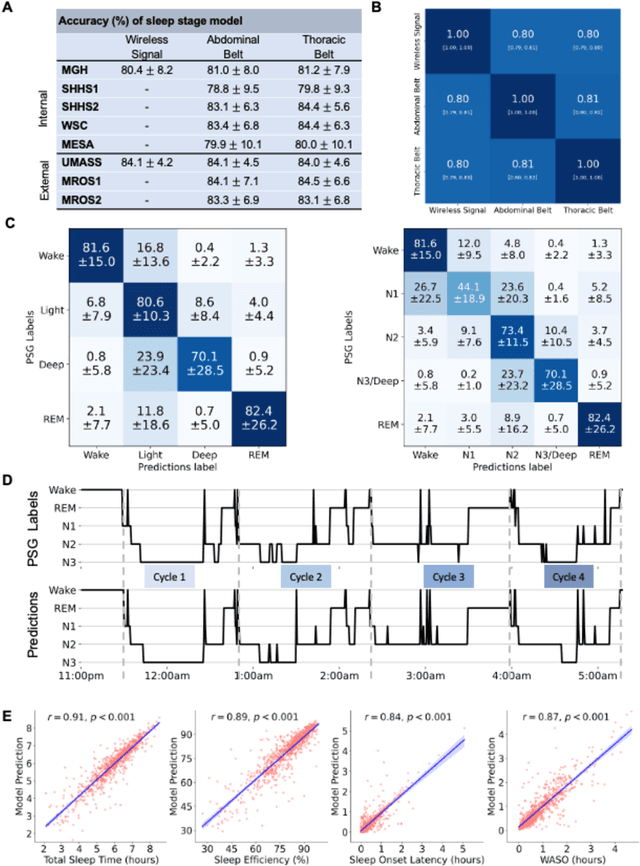
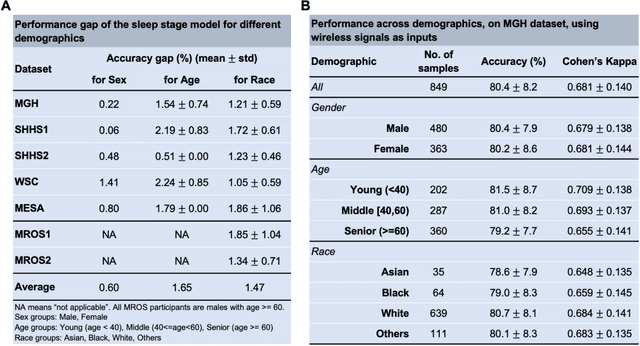
The ability to assess sleep at home, capture sleep stages, and detect the occurrence of apnea (without on-body sensors) simply by analyzing the radio waves bouncing off people's bodies while they sleep is quite powerful. Such a capability would allow for longitudinal data collection in patients' homes, informing our understanding of sleep and its interaction with various diseases and their therapeutic responses, both in clinical trials and routine care. In this article, we develop an advanced machine learning algorithm for passively monitoring sleep and nocturnal breathing from radio waves reflected off people while asleep. Validation results in comparison with the gold standard (i.e., polysomnography) (n=849) demonstrate that the model captures the sleep hypnogram (with an accuracy of 81% for 30-second epochs categorized into Wake, Light Sleep, Deep Sleep, or REM), detects sleep apnea (AUROC = 0.88), and measures the patient's Apnea-Hypopnea Index (ICC=0.95; 95% CI = [0.93, 0.97]). Notably, the model exhibits equitable performance across race, sex, and age. Moreover, the model uncovers informative interactions between sleep stages and a range of diseases including neurological, psychiatric, cardiovascular, and immunological disorders. These findings not only hold promise for clinical practice and interventional trials but also underscore the significance of sleep as a fundamental component in understanding and managing various diseases.
Learning Vision from Models Rivals Learning Vision from Data
Dec 28, 2023



We introduce SynCLR, a novel approach for learning visual representations exclusively from synthetic images and synthetic captions, without any real data. We synthesize a large dataset of image captions using LLMs, then use an off-the-shelf text-to-image model to generate multiple images corresponding to each synthetic caption. We perform visual representation learning on these synthetic images via contrastive learning, treating images sharing the same caption as positive pairs. The resulting representations transfer well to many downstream tasks, competing favorably with other general-purpose visual representation learners such as CLIP and DINO v2 in image classification tasks. Furthermore, in dense prediction tasks such as semantic segmentation, SynCLR outperforms previous self-supervised methods by a significant margin, e.g., improving over MAE and iBOT by 6.2 and 4.3 mIoU on ADE20k for ViT-B/16.