 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-free Universal Adversarial Perturbation with Pseudo-semantic Prior
Feb 28, 2025Data-free Universal Adversarial Perturbation (UAP) is an image-agnostic adversarial attack that deceives deep neural networks using a single perturbation generated solely from random noise, without any data priors. However, traditional data-free UAP methods often suffer from limited transferability due to the absence of semantic information in random noise. To address this, we propose a novel data-free universal attack approach that generates a pseudo-semantic prior recursively from the UAPs, enriching semantic contents within the data-free UAP framework. Our method is based on the observation that UAPs inherently contain latent semantic information, enabling the generated UAP to act as an alternative data prior, by capturing a diverse range of semantics through region sampling. We further introduce a sample reweighting technique to emphasize hard examples by focusing on samples that are less affected by the UAP. By leveraging the semantic information from the pseudo-semantic prior, we also incorporate input transformations, typically ineffective in data-free UAPs due to the lack of semantic content in random priors, to boost black-box transferability. Comprehensive experiments on ImageNet show that our method achieves state-of-the-art performance in average fooling rate by a substantial margin, significantly improves attack transferability across various CNN architectures compared to existing data-free UAP methods, and even surpasses data-dependent UAP methods.
Unsupervised Object Localization with Representer Point Selection
Sep 08, 2023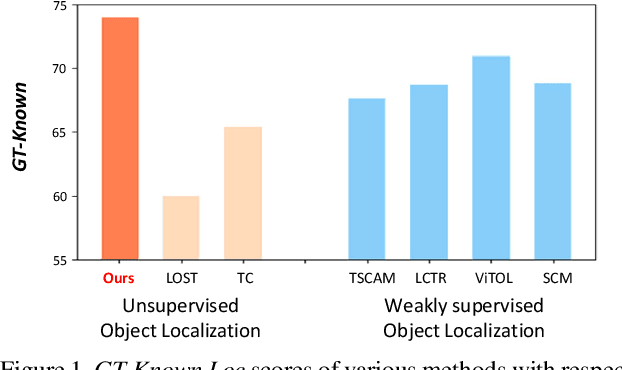
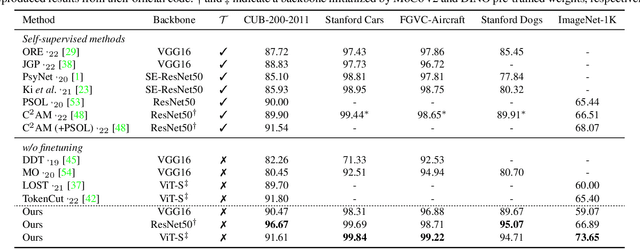
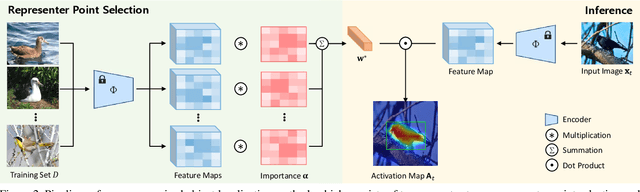
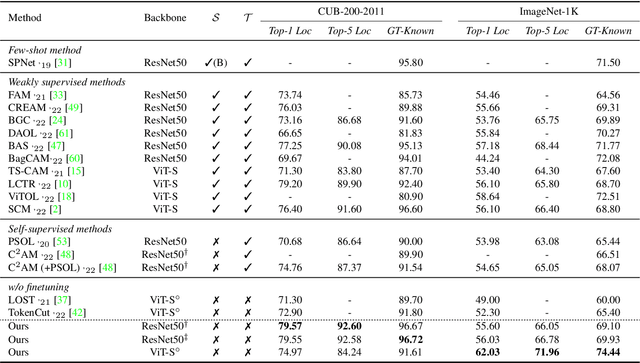
We propose a novel unsupervised object localization method that allows us to explain the predictions of the model by utilizing self-supervised pre-trained models without additional finetuning. Existing unsupervised and self-supervised object localization methods often utilize class-agnostic activation maps or self-similarity maps of a pre-trained model. Although these maps can offer valuable information for localization, their limited ability to explain how the model makes predictions remains challenging. In this paper, we propose a simple yet effective unsupervised object localization method based on representer point selection, where the predictions of the model can be represented as a linear combination of representer values of training points. By selecting representer points, which are the most important examples for the model predictions, our model can provide insights into how the model predicts the foreground object by providing relevant examples as well as their importance. Our method outperforms the state-of-the-art unsupervised and self-supervised object localization methods on various datasets with significant margins and even outperforms recent weakly supervised and few-shot methods.