 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Teacher View Augmentation: Boosting Knowledge Distillation via Angular Diversity
Oct 26, 2025Knowledge Distillation (KD) aims to train a lightweight student model by transferring knowledge from a large, high-capacity teacher. Recent studies have shown that leveraging diverse teacher perspectives can significantly improve distillation performance; however, achieving such diversity typically requires multiple teacher networks, leading to high computational costs. In this work, we propose a novel cost-efficient knowledge augmentation method for KD that generates diverse multi-views by attaching multiple branches to a single teacher. To ensure meaningful semantic variation across multi-views, we introduce two angular diversity objectives: 1) constrained inter-angle diversify loss, which maximizes angles between augmented views while preserving proximity to the original teacher output, and 2) intra-angle diversify loss, which encourages an even distribution of views around the original output. The ensembled knowledge from these angularly diverse views, along with the original teacher, is distilled into the student. We further theoretically demonstrate that our objectives increase the diversity among ensemble members and thereby reduce the upper bound of the ensemble's expected loss, leading to more effective distillation. Experimental results show that our method surpasses an existing knowledge augmentation method across diverse configurations. Moreover, the proposed method is compatible with other KD frameworks in a plug-and-play fashion, providing consistent improvements in generalization performance.
Online Generic Event Boundary Detection
Oct 08, 2025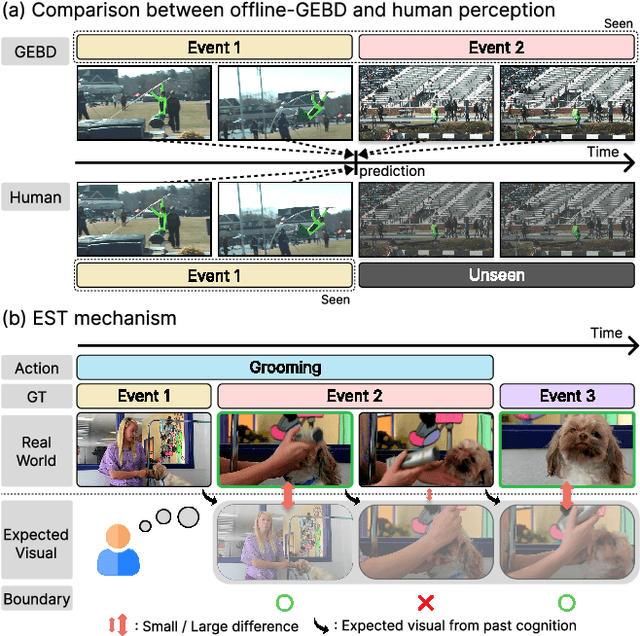
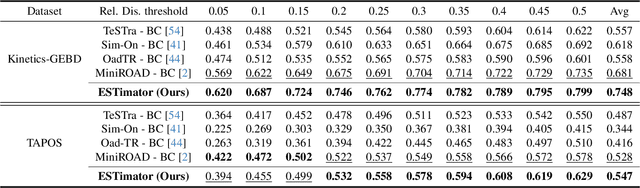
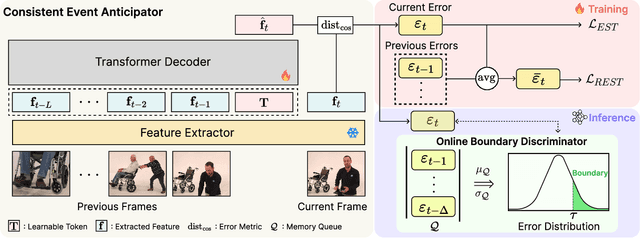
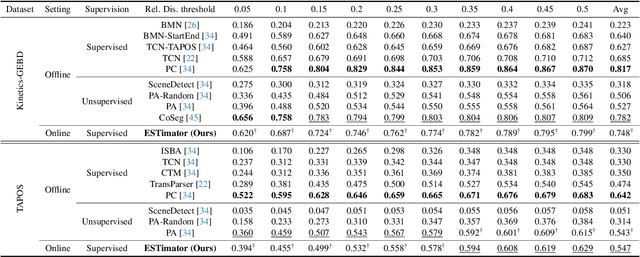
Generic Event Boundary Detection (GEBD) aims to interpret long-form videos through the lens of human perception. However, current GEBD methods require processing complete video frames to make predictions, unlike humans processing data online and in real-time. To bridge this gap, we introduce a new task, Online Generic Event Boundary Detection (On-GEBD), aiming to detect boundaries of generic events immediately in streaming videos. This task faces unique challenges of identifying subtle, taxonomy-free event changes in real-time, without the access to future frames. To tackle these challenges, we propose a novel On-GEBD framework, Estimator, inspired by Event Segmentation Theory (EST) which explains how humans segment ongoing activity into events by leveraging the discrepancies between predicted and actual information. Our framework consists of two key components: the Consistent Event Anticipator (CEA), and the Online Boundary Discriminator (OBD). Specifically, the CEA generates a prediction of the future frame reflecting current event dynamics based solely on prior frames. Then, the OBD measures the prediction error and adaptively adjusts the threshold using statistical tests on past errors to capture diverse, subtle event transitions. Experimental results demonstrate that Estimator outperforms all baselines adapted from recent online video understanding models and achieves performance comparable to prior offline-GEBD methods on the Kinetics-GEBD and TAPOS datasets.
Latent Expression Generation for Referring Image Segmentation and Grounding
Aug 07, 2025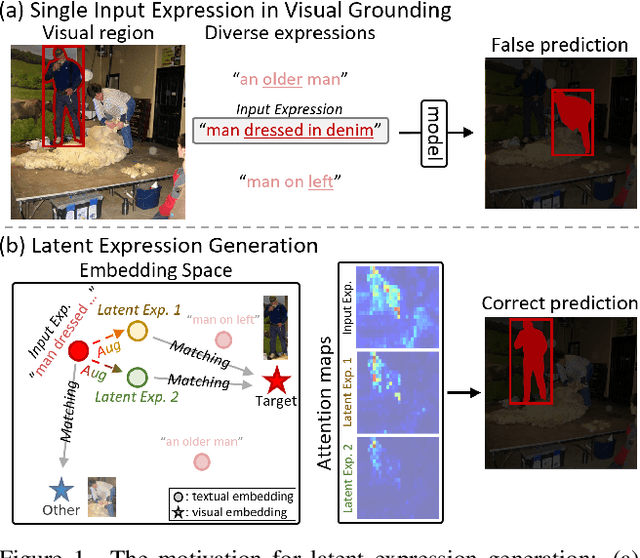
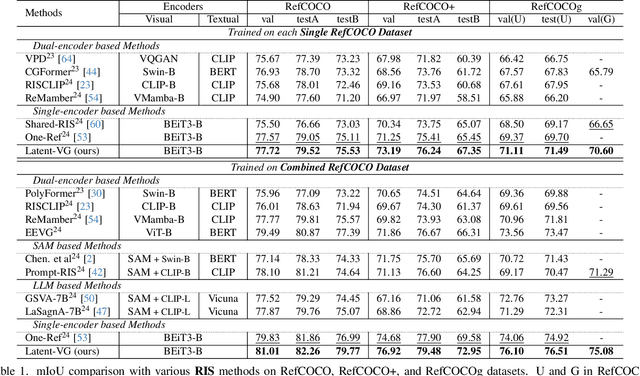
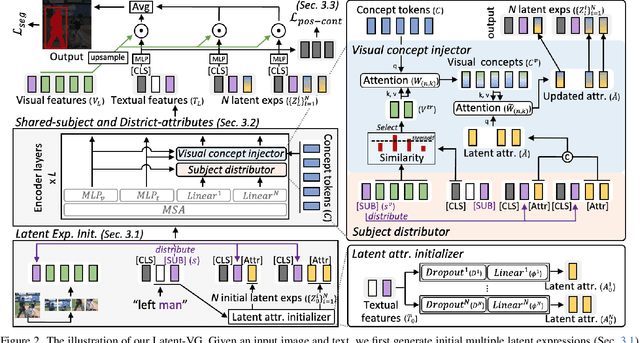
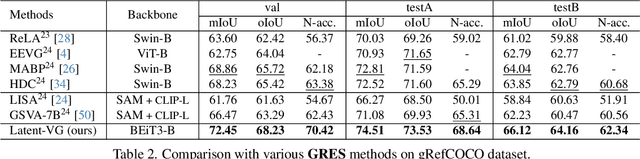
Visual grounding tasks, such as referring image segmentation (RIS) and referring expression comprehension (REC), aim to localize a target object based on a given textual description. The target object in an image can be described in multiple ways, reflecting diverse attributes such as color, position, and more. However, most existing methods rely on a single textual input, which captures only a fraction of the rich information available in the visual domain. This mismatch between rich visual details and sparse textual cues can lead to the misidentification of similar objects. To address this, we propose a novel visual grounding framework that leverages multiple latent expressions generated from a single textual input by incorporating complementary visual details absent from the original description. Specifically, we introduce subject distributor and visual concept injector modules to embed both shared-subject and distinct-attributes concepts into the latent representations, thereby capturing unique and target-specific visual cues. We also propose a positive-margin contrastive learning strategy to align all latent expressions with the original text while preserving subtle variations. Experimental results show that our method not only outperforms state-of-the-art RIS and REC approaches on multiple benchmarks but also achieves outstanding performance on the generalized referring expression segmentation (GRES) benchmark.
Data-free Universal Adversarial Perturbation with Pseudo-semantic Prior
Feb 28, 2025Data-free Universal Adversarial Perturbation (UAP) is an image-agnostic adversarial attack that deceives deep neural networks using a single perturbation generated solely from random noise, without any data priors. However, traditional data-free UAP methods often suffer from limited transferability due to the absence of semantic information in random noise. To address this, we propose a novel data-free universal attack approach that generates a pseudo-semantic prior recursively from the UAPs, enriching semantic contents within the data-free UAP framework. Our method is based on the observation that UAPs inherently contain latent semantic information, enabling the generated UAP to act as an alternative data prior, by capturing a diverse range of semantics through region sampling. We further introduce a sample reweighting technique to emphasize hard examples by focusing on samples that are less affected by the UAP. By leveraging the semantic information from the pseudo-semantic prior, we also incorporate input transformations, typically ineffective in data-free UAPs due to the lack of semantic content in random priors, to boost black-box transferability. Comprehensive experiments on ImageNet show that our method achieves state-of-the-art performance in average fooling rate by a substantial margin, significantly improves attack transferability across various CNN architectures compared to existing data-free UAP methods, and even surpasses data-dependent UAP methods.
A Simple Baseline with Single-encoder for Referring Image Segmentation
Aug 28, 2024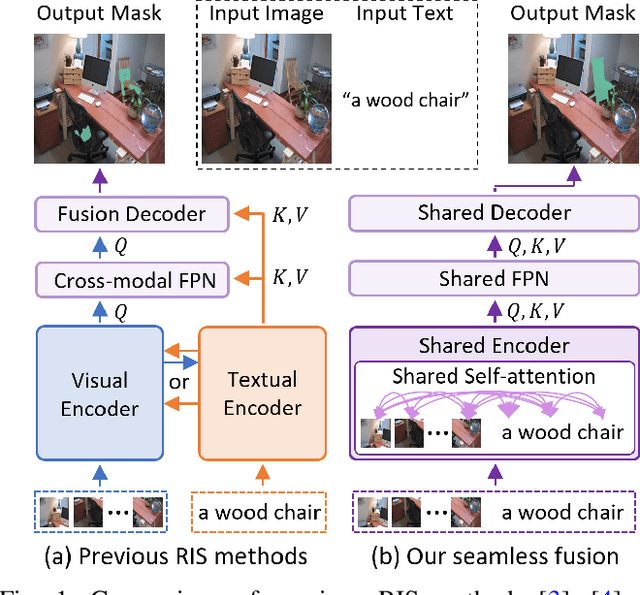
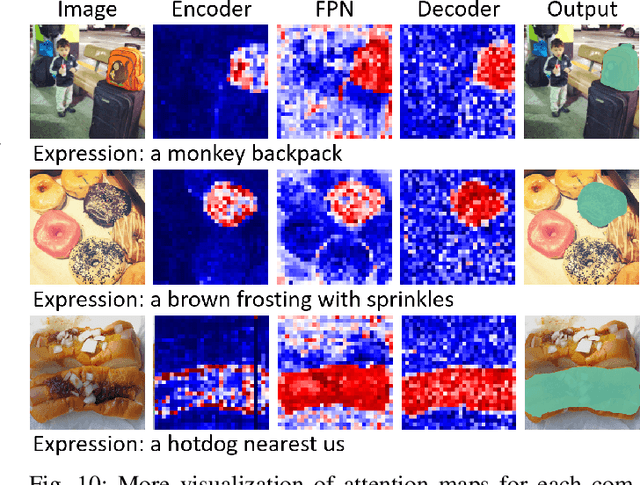


Referring image segmentation (RIS) requires dense vision-language interactions between visual pixels and textual words to segment objects based on a given description. However, commonly adapted dual-encoders in RIS, e.g., Swin transformer and BERT (uni-modal encoders) or CLIP (a multi-modal dual-encoder), lack dense multi-modal interactions during pre-training, leading to a gap with a pixel-level RIS task. To bridge this gap, existing RIS methods often rely on multi-modal fusion modules that interact two encoders, but this approach leads to high computational costs. In this paper, we present a novel RIS method with a single-encoder, i.e., BEiT-3, maximizing the potential of shared self-attention across all framework components. This enables seamless interactions of two modalities from input to final prediction, producing granularly aligned multi-modal features. Furthermore, we propose lightweight yet effective decoder modules, a Shared FPN and a Shared Mask Decoder, which contribute to the high efficiency of our model. Our simple baseline with a single encoder achieves outstanding performances on the RIS benchmark datasets while maintaining computational efficiency, compared to the most recent SoTA methods based on dual-encoders.
Pseudo-RIS: Distinctive Pseudo-supervision Generation for Referring Image Segmentation
Jul 10, 2024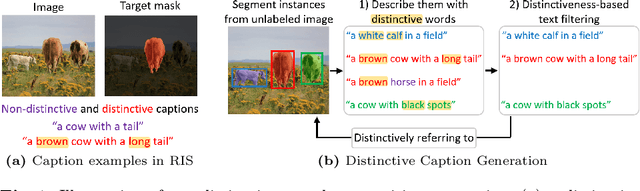
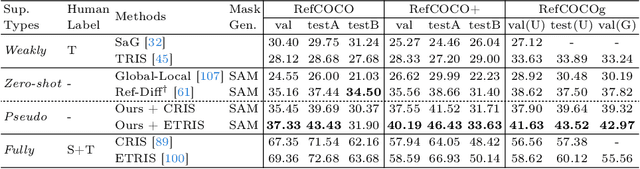
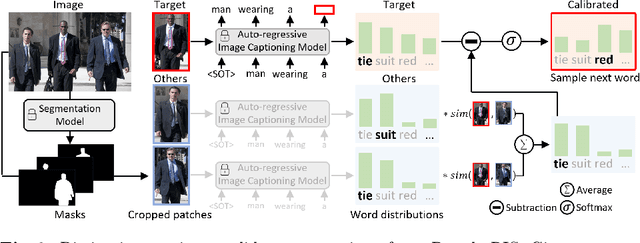
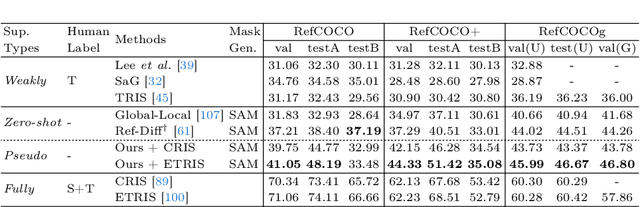
We propose a new framework that automatically generates high-quality segmentation masks with their referring expressions as pseudo supervisions for referring image segmentation (RIS). These pseudo supervisions allow the training of any supervised RIS methods without the cost of manual labeling. To achieve this, we incorporate existing segmentation and image captioning foundation models, leveraging their broad generalization capabilities. However, the naive incorporation of these models may generate non-distinctive expressions that do not distinctively refer to the target masks. To address this challenge, we propose two-fold strategies that generate distinctive captions: 1) 'distinctive caption sampling', a new decoding method for the captioning model, to generate multiple expression candidates with detailed words focusing on the target. 2) 'distinctiveness-based text filtering' to further validate the candidates and filter out those with a low level of distinctiveness. These two strategies ensure that the generated text supervisions can distinguish the target from other objects, making them appropriate for the RIS annotations. Our method significantly outperforms both weakly and zero-shot SoTA methods on the RIS benchmark datasets. It also surpasses fully supervised methods in unseen domains, proving its capability to tackle the open-world challenge within RIS. Furthermore, integrating our method with human annotations yields further improvements, highlighting its potential in semi-supervised learning applications.
Unsupervised Object Localization with Representer Point Selection
Sep 08, 2023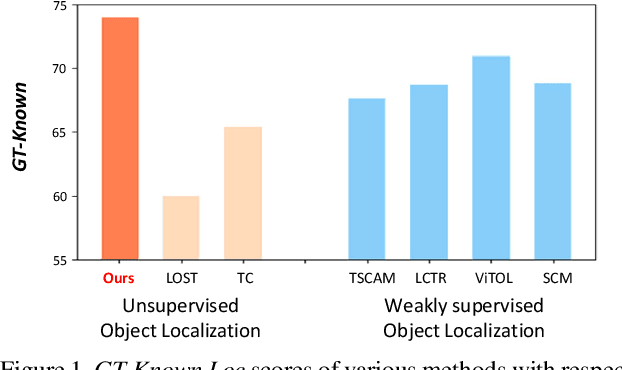
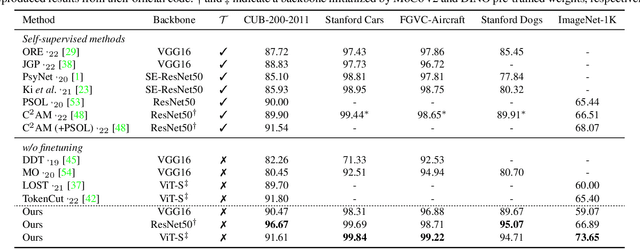
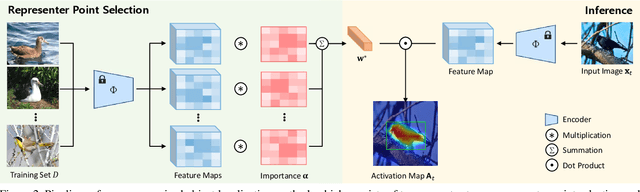
We propose a novel unsupervised object localization method that allows us to explain the predictions of the model by utilizing self-supervised pre-trained models without additional finetuning. Existing unsupervised and self-supervised object localization methods often utilize class-agnostic activation maps or self-similarity maps of a pre-trained model. Although these maps can offer valuable information for localization, their limited ability to explain how the model makes predictions remains challenging. In this paper, we propose a simple yet effective unsupervised object localization method based on representer point selection, where the predictions of the model can be represented as a linear combination of representer values of training points. By selecting representer points, which are the most important examples for the model predictions, our model can provide insights into how the model predicts the foreground object by providing relevant examples as well as their importance. Our method outperforms the state-of-the-art unsupervised and self-supervised object localization methods on various datasets with significant margins and even outperforms recent weakly supervised and few-shot methods.
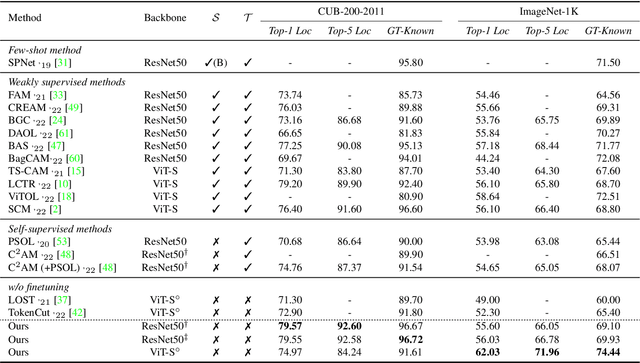
Zero-shot Referring Image Segmentation with Global-Local Context Features
Apr 03, 2023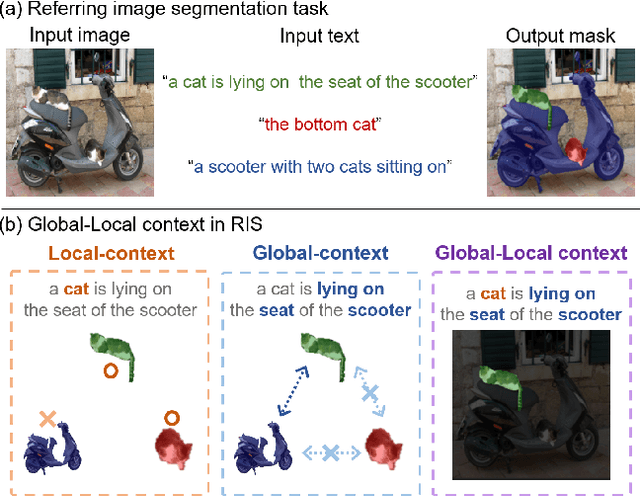
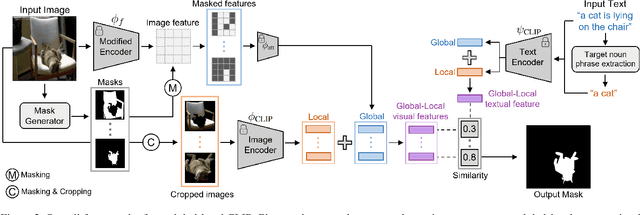
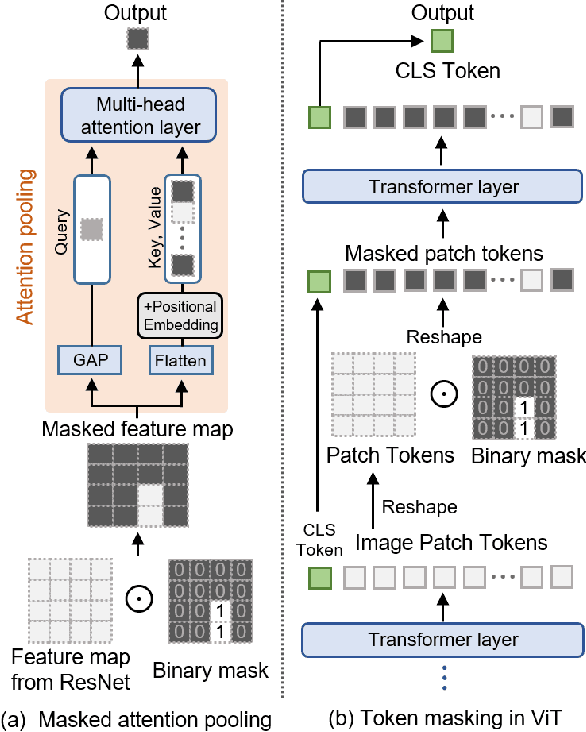
Referring image segmentation (RIS) aims to find a segmentation mask given a referring expression grounded to a region of the input image. Collecting labelled datasets for this task, however, is notoriously costly and labor-intensive. To overcome this issue, we propose a simple yet effective zero-shot referring image segmentation method by leveraging the pre-trained cross-modal knowledge from CLIP. In order to obtain segmentation masks grounded to the input text, we propose a mask-guided visual encoder that captures global and local contextual information of an input image. By utilizing instance masks obtained from off-the-shelf mask proposal techniques, our method is able to segment fine-detailed Istance-level groundings. We also introduce a global-local text encoder where the global feature captures complex sentence-level semantics of the entire input expression while the local feature focuses on the target noun phrase extracted by a dependency parser. In our experiments, the proposed method outperforms several zero-shot baselines of the task and even the weakly supervised referring expression segmentation method with substantial margins. Our code is available at https://github.com/Seonghoon-Yu/Zero-shot-RIS.
Weakly Supervised Instance Segmentation by Deep Community Learning
Mar 06, 2020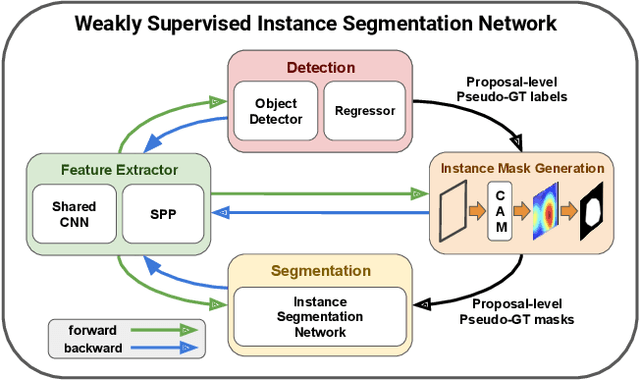
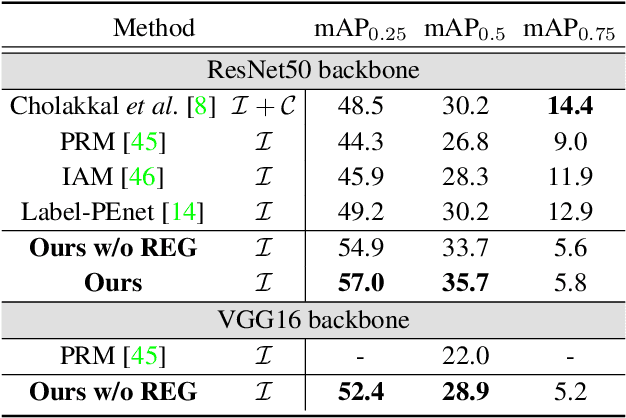
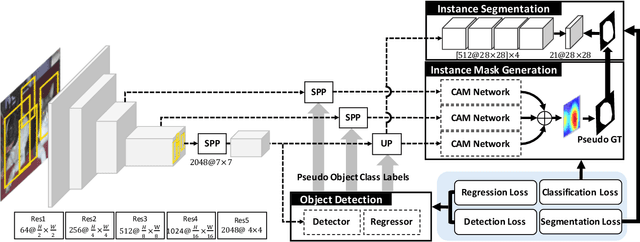
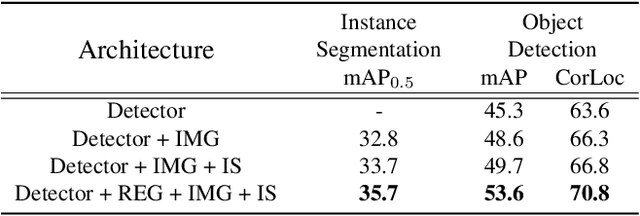
We present a weakly supervised instance segmentation algorithm based on deep community learning with multiple tasks. This task is formulated as a combination of weakly supervised object detection and semantic segmentation, where individual objects of the same class are identified and segmented separately. We address this problem by designing a unified deep neural network architecture, which has a positive feedback loop of object detection with bounding box regression, instance mask generation, instance segmentation, and feature extraction. Each component of the network makes active interactions with others to improve accuracy, and the end-to-end trainability of our model makes our results more robust and reproducible. The proposed algorithm achieves state-of-the-art performance in the weakly supervised setting without any additional training such as Fast R-CNN and Mask R-CNN on the standard benchmark dataset.
Real-Time MDNet
Aug 27, 2018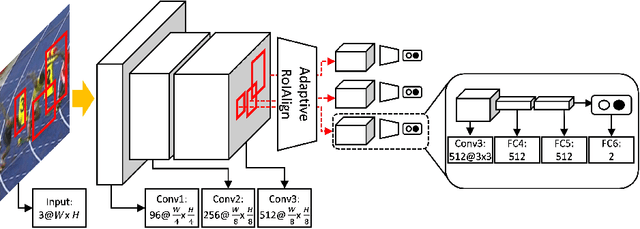

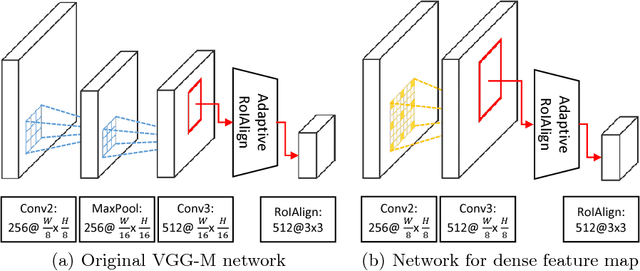

We present a fast and accurate visual tracking algorithm based on the multi-domain convolutional neural network (MDNet). The proposed approach accelerates feature extraction procedure and learns more discriminative models for instance classification; it enhances representation quality of target and background by maintaining a high resolution feature map with a large receptive field per activation. We also introduce a novel loss term to differentiate foreground instances across multiple domains and learn a more discriminative embedding of target objects with similar semantics. The proposed techniques are integrated into the pipeline of a well known CNN-based visual tracking algorithm, MDNet. We accomplish approximately 25 times speed-up with almost identical accuracy compared to MDNet. Our algorithm is evaluated in multiple popular tracking benchmark datasets including OTB2015, UAV123, and TempleColor, and outperforms the state-of-the-art real-time tracking methods consistently even without dataset-specific parameter tuning.