 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeaCache: Spectral-Evolution-Aware Cache for Accelerating Diffusion Models
Feb 22, 2026Diffusion models are a strong backbone for visual generation, but their inherently sequential denoising process leads to slow inference. Previous methods accelerate sampling by caching and reusing intermediate outputs based on feature distances between adjacent timesteps. However, existing caching strategies typically rely on raw feature differences that entangle content and noise. This design overlooks spectral evolution, where low-frequency structure appears early and high-frequency detail is refined later. We introduce Spectral-Evolution-Aware Cache (SeaCache), a training-free cache schedule that bases reuse decisions on a spectrally aligned representation. Through theoretical and empirical analysis, we derive a Spectral-Evolution-Aware (SEA) filter that preserves content-relevant components while suppressing noise. Employing SEA-filtered input features to estimate redundancy leads to dynamic schedules that adapt to content while respecting the spectral priors underlying the diffusion model. Extensive experiments on diverse visual generative models and the baselines show that SeaCache achieves state-of-the-art latency-quality trade-offs.
A Simple Baseline with Single-encoder for Referring Image Segmentation
Aug 28, 2024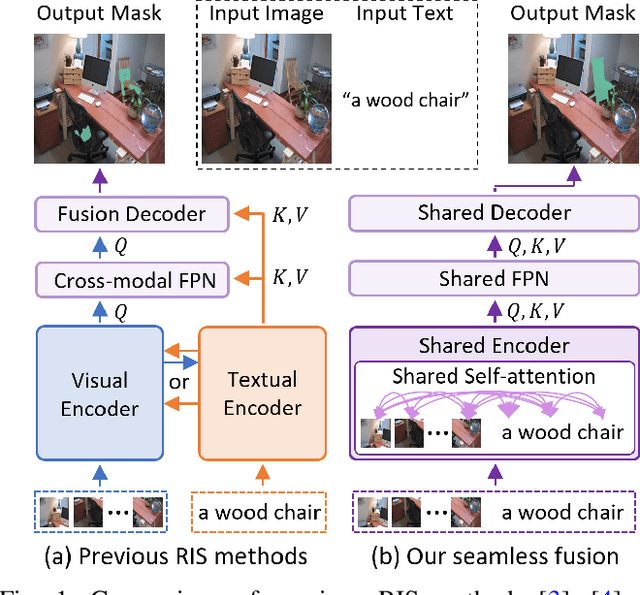
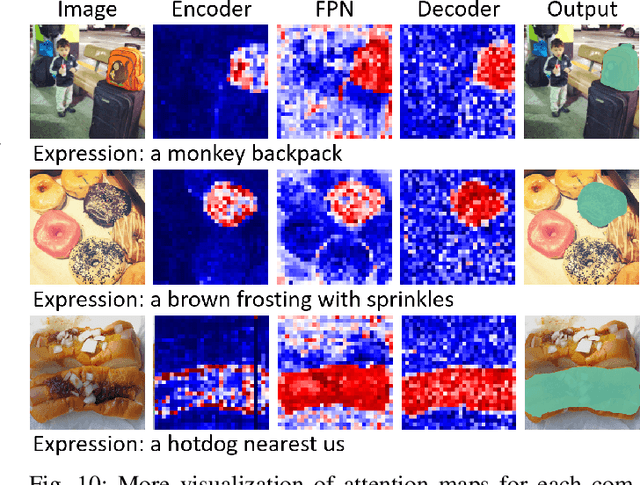


Referring image segmentation (RIS) requires dense vision-language interactions between visual pixels and textual words to segment objects based on a given description. However, commonly adapted dual-encoders in RIS, e.g., Swin transformer and BERT (uni-modal encoders) or CLIP (a multi-modal dual-encoder), lack dense multi-modal interactions during pre-training, leading to a gap with a pixel-level RIS task. To bridge this gap, existing RIS methods often rely on multi-modal fusion modules that interact two encoders, but this approach leads to high computational costs. In this paper, we present a novel RIS method with a single-encoder, i.e., BEiT-3, maximizing the potential of shared self-attention across all framework components. This enables seamless interactions of two modalities from input to final prediction, producing granularly aligned multi-modal features. Furthermore, we propose lightweight yet effective decoder modules, a Shared FPN and a Shared Mask Decoder, which contribute to the high efficiency of our model. Our simple baseline with a single encoder achieves outstanding performances on the RIS benchmark datasets while maintaining computational efficiency, compared to the most recent SoTA methods based on dual-encoders.