 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond the Window: Global-Local Aligned CLIP for Training-free Open-Vocabulary Semantic Segmentation
Mar 24, 2026A sliding-window inference strategy is commonly adopted in recent training-free open-vocabulary semantic segmentation methods to overcome limitation of the CLIP in processing high-resolution images. However, this approach introduces a new challenge: each window is processed independently, leading to semantic discrepancy across windows. To address this issue, we propose Global-Local Aligned CLIP~(GLA-CLIP), a framework that facilitates comprehensive information exchange across windows. Rather than limiting attention to tokens within individual windows, GLA-CLIP extends key-value tokens to incorporate contextual cues from all windows. Nevertheless, we observe a window bias: outer-window tokens are less likely to be attended, since query features are produced through interactions within the inner window patches, thereby lacking semantic grounding beyond their local context. To mitigate this, we introduce a proxy anchor, constructed by aggregating tokens highly similar to the given query from all windows, which provides a unified semantic reference for measuring similarity across both inner- and outer-window patches. Furthermore, we propose a dynamic normalization scheme that adjusts attention strength according to object scale by dynamically scaling and thresholding the attention map to cope with small-object scenarios. Moreover, GLA-CLIP can be equipped on existing methods and broad their receptive field. Extensive experiments validate the effectiveness of GLA-CLIP in enhancing training-free open-vocabulary semantic segmentation performance. Code is available at https://github.com/2btlFe/GLA-CLIP.
SeaCache: Spectral-Evolution-Aware Cache for Accelerating Diffusion Models
Feb 22, 2026Diffusion models are a strong backbone for visual generation, but their inherently sequential denoising process leads to slow inference. Previous methods accelerate sampling by caching and reusing intermediate outputs based on feature distances between adjacent timesteps. However, existing caching strategies typically rely on raw feature differences that entangle content and noise. This design overlooks spectral evolution, where low-frequency structure appears early and high-frequency detail is refined later. We introduce Spectral-Evolution-Aware Cache (SeaCache), a training-free cache schedule that bases reuse decisions on a spectrally aligned representation. Through theoretical and empirical analysis, we derive a Spectral-Evolution-Aware (SEA) filter that preserves content-relevant components while suppressing noise. Employing SEA-filtered input features to estimate redundancy leads to dynamic schedules that adapt to content while respecting the spectral priors underlying the diffusion model. Extensive experiments on diverse visual generative models and the baselines show that SeaCache achieves state-of-the-art latency-quality trade-offs.
Rethinking LayerNorm in Image Restoration Transformers
Apr 09, 2025This work investigates abnormal feature behaviors observed in image restoration (IR) Transformers. Specifically, we identify two critical issues: feature entropy becoming excessively small and feature magnitudes diverging up to a million-fold scale. We pinpoint the root cause to the per-token normalization aspect of conventional LayerNorm, which disrupts essential spatial correlations and internal feature statistics. To address this, we propose a simple normalization strategy tailored for IR Transformers. Our approach applies normalization across the entire spatio-channel dimension, effectively preserving spatial correlations. Additionally, we introduce an input-adaptive rescaling method that aligns feature statistics to the unique statistical requirements of each input. Experimental results verify that this combined strategy effectively resolves feature divergence, significantly enhancing both the stability and performance of IR Transformers across various IR tasks.
Fine-Tuning Visual Autoregressive Models for Subject-Driven Generation
Apr 03, 2025Recent advances in text-to-image generative models have enabled numerous practical applications, including subject-driven generation, which fine-tunes pretrained models to capture subject semantics from only a few examples. While diffusion-based models produce high-quality images, their extensive denoising steps result in significant computational overhead, limiting real-world applicability. Visual autoregressive~(VAR) models, which predict next-scale tokens rather than spatially adjacent ones, offer significantly faster inference suitable for practical deployment. In this paper, we propose the first VAR-based approach for subject-driven generation. However, na\"{\i}ve fine-tuning VAR leads to computational overhead, language drift, and reduced diversity. To address these challenges, we introduce selective layer tuning to reduce complexity and prior distillation to mitigate language drift. Additionally, we found that the early stages have a greater influence on the generation of subject than the latter stages, which merely synthesize local details. Based on this finding, we propose scale-wise weighted tuning, which prioritizes coarser resolutions for promoting the model to focus on the subject-relevant information instead of local details. Extensive experiments validate that our method significantly outperforms diffusion-based baselines across various metrics and demonstrates its practical usage.
Auto-Encoded Supervision for Perceptual Image Super-Resolution
Nov 28, 2024



This work tackles the fidelity objective in the perceptual super-resolution~(SR). Specifically, we address the shortcomings of pixel-level $L_\text{p}$ loss ($\mathcal{L}_\text{pix}$) in the GAN-based SR framework. Since $L_\text{pix}$ is known to have a trade-off relationship against perceptual quality, prior methods often multiply a small scale factor or utilize low-pass filters. However, this work shows that these circumventions fail to address the fundamental factor that induces blurring. Accordingly, we focus on two points: 1) precisely discriminating the subcomponent of $L_\text{pix}$ that contributes to blurring, and 2) only guiding based on the factor that is free from this trade-off relationship. We show that they can be achieved in a surprisingly simple manner, with an Auto-Encoder (AE) pretrained with $L_\text{pix}$. Accordingly, we propose the Auto-Encoded Supervision for Optimal Penalization loss ($L_\text{AESOP}$), a novel loss function that measures distance in the AE space, instead of the raw pixel space. Note that the AE space indicates the space after the decoder, not the bottleneck. By simply substituting $L_\text{pix}$ with $L_\text{AESOP}$, we can provide effective reconstruction guidance without compromising perceptual quality. Designed for simplicity, our method enables easy integration into existing SR frameworks. Experimental results verify that AESOP can lead to favorable results in the perceptual SR task.
Adversarial Generation of Hierarchical Gaussians for 3D Generative Model
Jun 05, 2024Most advances in 3D Generative Adversarial Networks (3D GANs) largely depend on ray casting-based volume rendering, which incurs demanding rendering costs. One promising alternative is rasterization-based 3D Gaussian Splatting (3D-GS), providing a much faster rendering speed and explicit 3D representation. In this paper, we exploit Gaussian as a 3D representation for 3D GANs by leveraging its efficient and explicit characteristics. However, in an adversarial framework, we observe that a na\"ive generator architecture suffers from training instability and lacks the capability to adjust the scale of Gaussians. This leads to model divergence and visual artifacts due to the absence of proper guidance for initialized positions of Gaussians and densification to manage their scales adaptively. To address these issues, we introduce a generator architecture with a hierarchical multi-scale Gaussian representation that effectively regularizes the position and scale of generated Gaussians. Specifically, we design a hierarchy of Gaussians where finer-level Gaussians are parameterized by their coarser-level counterparts; the position of finer-level Gaussians would be located near their coarser-level counterparts, and the scale would monotonically decrease as the level becomes finer, modeling both coarse and fine details of the 3D scene. Experimental results demonstrate that ours achieves a significantly faster rendering speed (x100) compared to state-of-the-art 3D consistent GANs with comparable 3D generation capability. Project page: https://hse1032.github.io/gsgan.
Diversity-aware Channel Pruning for StyleGAN Compression
Mar 20, 2024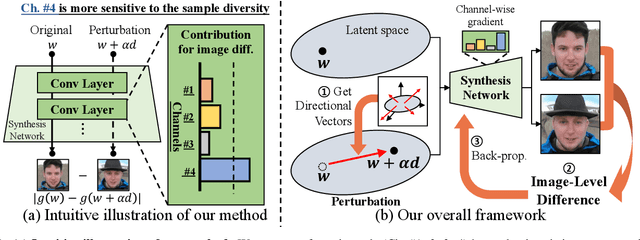
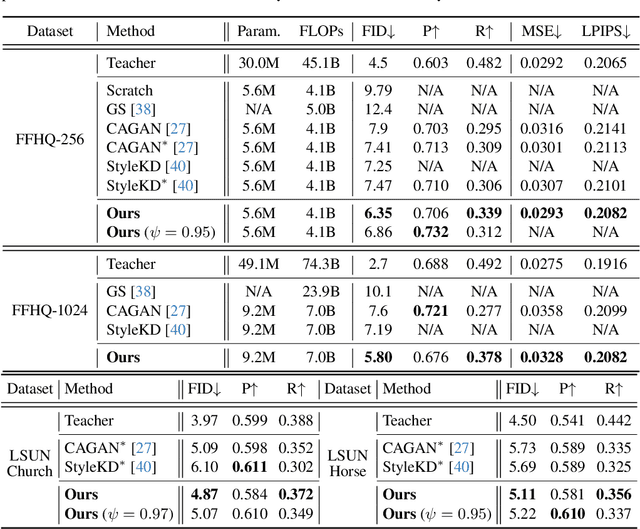
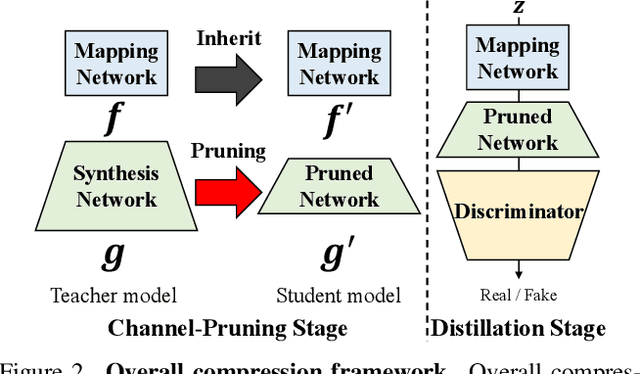
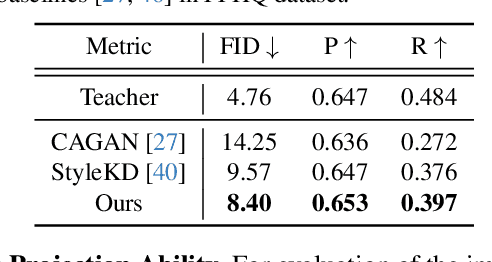
StyleGAN has shown remarkable performance in unconditional image generation. However, its high computational cost poses a significant challenge for practical applications. Although recent efforts have been made to compress StyleGAN while preserving its performance, existing compressed models still lag behind the original model, particularly in terms of sample diversity. To overcome this, we propose a novel channel pruning method that leverages varying sensitivities of channels to latent vectors, which is a key factor in sample diversity. Specifically, by assessing channel importance based on their sensitivities to latent vector perturbations, our method enhances the diversity of samples in the compressed model. Since our method solely focuses on the channel pruning stage, it has complementary benefits with prior training schemes without additional training cost. Extensive experiments demonstrate that our method significantly enhances sample diversity across various datasets. Moreover, in terms of FID scores, our method not only surpasses state-of-the-art by a large margin but also achieves comparable scores with only half training iterations.
Task-Disruptive Background Suppression for Few-Shot Segmentation
Dec 26, 2023Few-shot segmentation aims to accurately segment novel target objects within query images using only a limited number of annotated support images. The recent works exploit support background as well as its foreground to precisely compute the dense correlations between query and support. However, they overlook the characteristics of the background that generally contains various types of objects. In this paper, we highlight this characteristic of background which can bring problematic cases as follows: (1) when the query and support backgrounds are dissimilar and (2) when objects in the support background are similar to the target object in the query. Without any consideration of the above cases, adopting the entire support background leads to a misprediction of the query foreground as background. To address this issue, we propose Task-disruptive Background Suppression (TBS), a module to suppress those disruptive support background features based on two spatial-wise scores: query-relevant and target-relevant scores. The former aims to mitigate the impact of unshared features solely existing in the support background, while the latter aims to reduce the influence of target-similar support background features. Based on these two scores, we define a query background relevant score that captures the similarity between the backgrounds of the query and the support, and utilize it to scale support background features to adaptively restrict the impact of disruptive support backgrounds. Our proposed method achieves state-of-the-art performance on PASCAL-5 and COCO-20 datasets on 1-shot segmentation. Our official code is available at github.com/SuhoPark0706/TBSNet.
Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer
Dec 11, 2023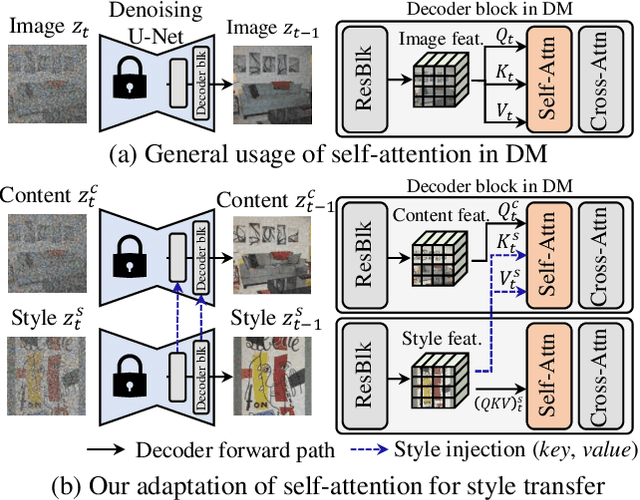

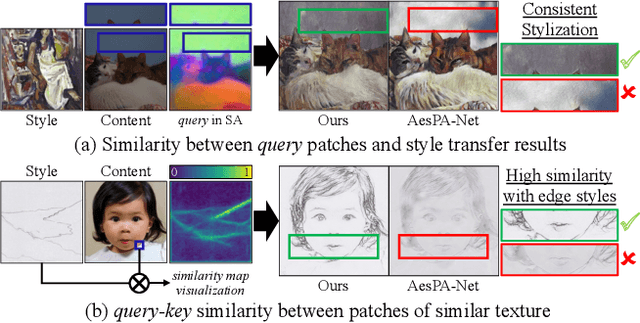
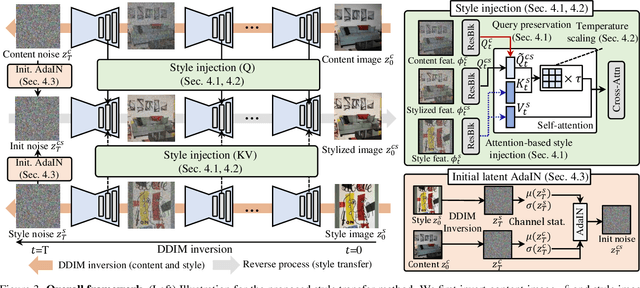
Despite the impressive generative capabilities of diffusion models, existing diffusion model-based style transfer methods require inference-stage optimization (e.g. fine-tuning or textual inversion of style) which is time-consuming, or fails to leverage the generative ability of large-scale diffusion models. To address these issues, we introduce a novel artistic style transfer method based on a pre-trained large-scale diffusion model without any optimization. Specifically, we manipulate the features of self-attention layers as the way the cross-attention mechanism works; in the generation process, substituting the key and value of content with those of style image. This approach provides several desirable characteristics for style transfer including 1) preservation of content by transferring similar styles into similar image patches and 2) transfer of style based on similarity of local texture (e.g. edge) between content and style images. Furthermore, we introduce query preservation and attention temperature scaling to mitigate the issue of disruption of original content, and initial latent Adaptive Instance Normalization (AdaIN) to deal with the disharmonious color (failure to transfer the colors of style). Our experimental results demonstrate that our proposed method surpasses state-of-the-art methods in both conventional and diffusion-based style transfer baselines.
Correlation-guided Query-Dependency Calibration in Video Representation Learning for Temporal Grounding
Nov 18, 2023



Recent endeavors in video temporal grounding enforce strong cross-modal interactions through attention mechanisms to overcome the modality gap between video and text query. However, previous works treat all video clips equally regardless of their semantic relevance with the text query in attention modules. In this paper, our goal is to provide clues for query-associated video clips within the crossmodal encoding process. With our Correlation-Guided Detection Transformer~(CG-DETR), we explore the appropriate clip-wise degree of cross-modal interactions and how to exploit such degrees for prediction. First, we design an adaptive cross-attention layer with dummy tokens. Dummy tokens conditioned by text query take a portion of the attention weights, preventing irrelevant video clips from being represented by the text query. Yet, not all word tokens equally inherit the text query's correlation to video clips. Thus, we further guide the cross-attention map by inferring the fine-grained correlation between video clips and words. We enable this by learning a joint embedding space for high-level concepts, i.e., moment and sentence level, and inferring the clip-word correlation. Lastly, we use a moment-adaptive saliency detector to exploit each video clip's degrees of text engagement. We validate the superiority of CG-DETR with the state-of-the-art results on various benchmarks for both moment retrieval and highlight detection. Codes are available at https://github.com/wjun0830/CGDETR.