 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Beyond the Window: Global-Local Aligned CLIP for Training-free Open-Vocabulary Semantic Segmentation
Mar 24, 2026A sliding-window inference strategy is commonly adopted in recent training-free open-vocabulary semantic segmentation methods to overcome limitation of the CLIP in processing high-resolution images. However, this approach introduces a new challenge: each window is processed independently, leading to semantic discrepancy across windows. To address this issue, we propose Global-Local Aligned CLIP~(GLA-CLIP), a framework that facilitates comprehensive information exchange across windows. Rather than limiting attention to tokens within individual windows, GLA-CLIP extends key-value tokens to incorporate contextual cues from all windows. Nevertheless, we observe a window bias: outer-window tokens are less likely to be attended, since query features are produced through interactions within the inner window patches, thereby lacking semantic grounding beyond their local context. To mitigate this, we introduce a proxy anchor, constructed by aggregating tokens highly similar to the given query from all windows, which provides a unified semantic reference for measuring similarity across both inner- and outer-window patches. Furthermore, we propose a dynamic normalization scheme that adjusts attention strength according to object scale by dynamically scaling and thresholding the attention map to cope with small-object scenarios. Moreover, GLA-CLIP can be equipped on existing methods and broad their receptive field. Extensive experiments validate the effectiveness of GLA-CLIP in enhancing training-free open-vocabulary semantic segmentation performance. Code is available at https://github.com/2btlFe/GLA-CLIP.
Reconstruction-Guided Slot Curriculum: Addressing Object Over-Fragmentation in Video Object-Centric Learning
Mar 24, 2026Video Object-Centric Learning seeks to decompose raw videos into a small set of object slots, but existing slot-attention models often suffer from severe over-fragmentation. This is because the model is implicitly encouraged to occupy all slots to minimize the reconstruction objective, thereby representing a single object with multiple redundant slots. We tackle this limitation with a reconstruction-guided slot curriculum (SlotCurri). Training starts with only a few coarse slots and progressively allocates new slots where reconstruction error remains high, thus expanding capacity only where it is needed and preventing fragmentation from the outset. Yet, during slot expansion, meaningful sub-parts can emerge only if coarse-level semantics are already well separated; however, with a small initial slot budget and an MSE objective, semantic boundaries remain blurry. Therefore, we augment MSE with a structure-aware loss that preserves local contrast and edge information to encourage each slot to sharpen its semantic boundaries. Lastly, we propose a cyclic inference that rolls slots forward and then backward through the frame sequence, producing temporally consistent object representations even in the earliest frames. All combined, SlotCurri addresses object over-fragmentation by allocating representational capacity where reconstruction fails, further enhanced by structural cues and cyclic inference. Notable FG-ARI gains of +6.8 on YouTube-VIS and +8.3 on MOVi-C validate the effectiveness of SlotCurri. Our code is available at github.com/wjun0830/SlotCurri.
From Vicious to Virtuous Cycles: Synergistic Representation Learning for Unsupervised Video Object-Centric Learning
Feb 03, 2026Unsupervised object-centric learning models, particularly slot-based architectures, have shown great promise in decomposing complex scenes. However, their reliance on reconstruction-based training creates a fundamental conflict between the sharp, high-frequency attention maps of the encoder and the spatially consistent but blurry reconstruction maps of the decoder. We identify that this discrepancy gives rise to a vicious cycle: the noisy feature map from the encoder forces the decoder to average over possibilities and produce even blurrier outputs, while the gradient computed from blurry reconstruction maps lacks high-frequency details necessary to supervise encoder features. To break this cycle, we introduce Synergistic Representation Learning (SRL) that establishes a virtuous cycle where the encoder and decoder mutually refine one another. SRL leverages the encoder's sharpness to deblur the semantic boundary within the decoder output, while exploiting the decoder's spatial consistency to denoise the encoder's features. This mutual refinement process is stabilized by a warm-up phase with a slot regularization objective that initially allocates distinct entities per slot. By bridging the representational gap between the encoder and decoder, SRL achieves state-of-the-art results on video object-centric learning benchmarks. Codes are available at https://github.com/hynnsk/SRL.
Auxiliary Descriptive Knowledge for Few-Shot Adaptation of Vision-Language Model
Dec 19, 2025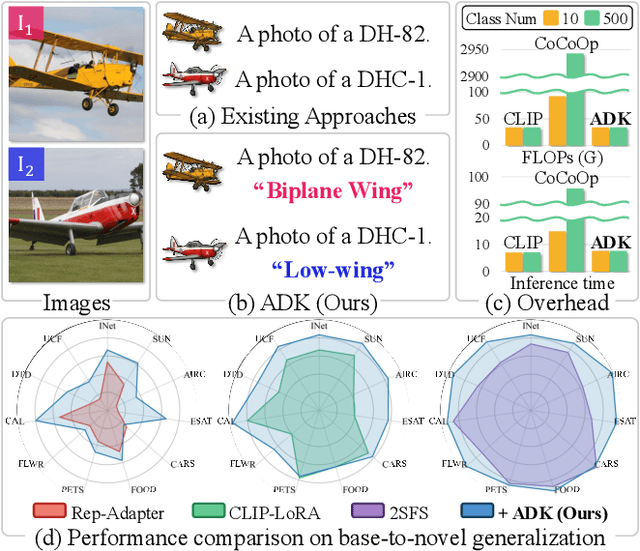
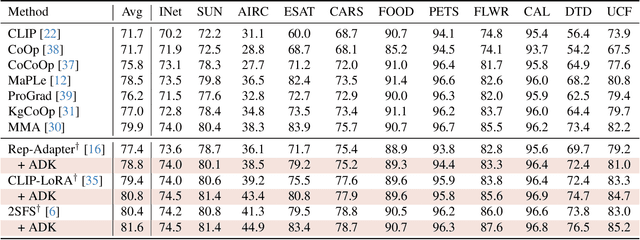
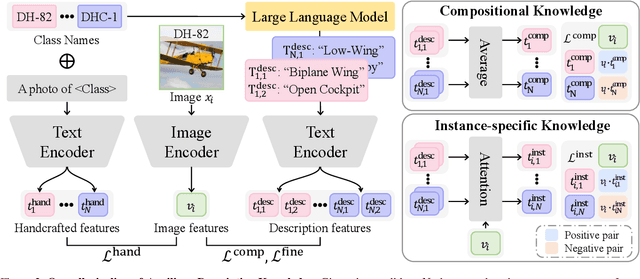
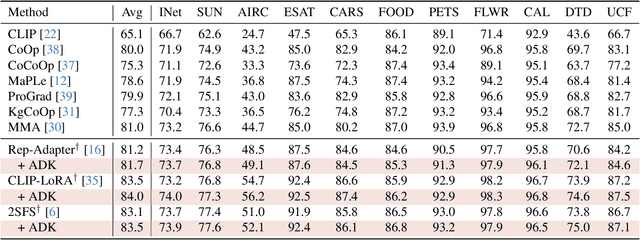
Despite the impressive zero-shot capabilities of Vision-Language Models (VLMs), they often struggle in downstream tasks with distribution shifts from the pre-training data. Few-Shot Adaptation (FSA-VLM) has emerged as a key solution, typically using Parameter-Efficient Fine-Tuning (PEFT) to adapt models with minimal data. However, these PEFT methods are constrained by their reliance on fixed, handcrafted prompts, which are often insufficient to understand the semantics of classes. While some studies have proposed leveraging image-induced prompts to provide additional clues for classification, they introduce prohibitive computational overhead at inference. Therefore, we introduce Auxiliary Descriptive Knowledge (ADK), a novel framework that efficiently enriches text representations without compromising efficiency. ADK first leverages a Large Language Model to generate a rich set of descriptive prompts for each class offline. These pre-computed features are then deployed in two ways: (1) as Compositional Knowledge, an averaged representation that provides rich semantics, especially beneficial when class names are ambiguous or unfamiliar to the VLM; and (2) as Instance-Specific Knowledge, where a lightweight, non-parametric attention mechanism dynamically selects the most relevant descriptions for a given image. This approach provides two additional types of knowledge alongside the handcrafted prompt, thereby facilitating category distinction across various domains. Also, ADK acts as a parameter-free, plug-and-play component that enhances existing PEFT methods. Extensive experiments demonstrate that ADK consistently boosts the performance of multiple PEFT baselines, setting a new state-of-the-art across various scenarios.
Selective Contrastive Learning for Weakly Supervised Affordance Grounding
Aug 11, 2025Facilitating an entity's interaction with objects requires accurately identifying parts that afford specific actions. Weakly supervised affordance grounding (WSAG) seeks to imitate human learning from third-person demonstrations, where humans intuitively grasp functional parts without needing pixel-level annotations. To achieve this, grounding is typically learned using a shared classifier across images from different perspectives, along with distillation strategies incorporating part discovery process. However, since affordance-relevant parts are not always easily distinguishable, models primarily rely on classification, often focusing on common class-specific patterns that are unrelated to affordance. To address this limitation, we move beyond isolated part-level learning by introducing selective prototypical and pixel contrastive objectives that adaptively learn affordance-relevant cues at both the part and object levels, depending on the granularity of the available information. Initially, we find the action-associated objects in both egocentric (object-focused) and exocentric (third-person example) images by leveraging CLIP. Then, by cross-referencing the discovered objects of complementary views, we excavate the precise part-level affordance clues in each perspective. By consistently learning to distinguish affordance-relevant regions from affordance-irrelevant background context, our approach effectively shifts activation from irrelevant areas toward meaningful affordance cues. Experimental results demonstrate the effectiveness of our method. Codes are available at github.com/hynnsk/SelectiveCL.
Temporal Alignment-Free Video Matching for Few-shot Action Recognition
Apr 08, 2025



Few-Shot Action Recognition (FSAR) aims to train a model with only a few labeled video instances. A key challenge in FSAR is handling divergent narrative trajectories for precise video matching. While the frame- and tuple-level alignment approaches have been promising, their methods heavily rely on pre-defined and length-dependent alignment units (e.g., frames or tuples), which limits flexibility for actions of varying lengths and speeds. In this work, we introduce a novel TEmporal Alignment-free Matching (TEAM) approach, which eliminates the need for temporal units in action representation and brute-force alignment during matching. Specifically, TEAM represents each video with a fixed set of pattern tokens that capture globally discriminative clues within the video instance regardless of action length or speed, ensuring its flexibility. Furthermore, TEAM is inherently efficient, using token-wise comparisons to measure similarity between videos, unlike existing methods that rely on pairwise comparisons for temporal alignment. Additionally, we propose an adaptation process that identifies and removes common information across classes, establishing clear boundaries even between novel categories. Extensive experiments demonstrate the effectiveness of TEAM. Codes are available at github.com/leesb7426/TEAM.
Foreground-Covering Prototype Generation and Matching for SAM-Aided Few-Shot Segmentation
Jan 01, 2025


We propose Foreground-Covering Prototype Generation and Matching to resolve Few-Shot Segmentation (FSS), which aims to segment target regions in unlabeled query images based on labeled support images. Unlike previous research, which typically estimates target regions in the query using support prototypes and query pixels, we utilize the relationship between support and query prototypes. To achieve this, we utilize two complementary features: SAM Image Encoder features for pixel aggregation and ResNet features for class consistency. Specifically, we construct support and query prototypes with SAM features and distinguish query prototypes of target regions based on ResNet features. For the query prototype construction, we begin by roughly guiding foreground regions within SAM features using the conventional pseudo-mask, then employ iterative cross-attention to aggregate foreground features into learnable tokens. Here, we discover that the cross-attention weights can effectively alternate the conventional pseudo-mask. Therefore, we use the attention-based pseudo-mask to guide ResNet features to focus on the foreground, then infuse the guided ResNet feature into the learnable tokens to generate class-consistent query prototypes. The generation of the support prototype is conducted symmetrically to that of the query one, with the pseudo-mask replaced by the ground-truth mask. Finally, we compare these query prototypes with support ones to generate prompts, which subsequently produce object masks through the SAM Mask Decoder. Our state-of-the-art performances on various datasets validate the effectiveness of the proposed method for FSS. Our official code is available at https://github.com/SuhoPark0706/FCP
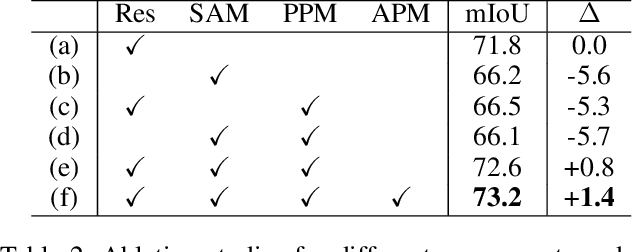
Progressive Proxy Anchor Propagation for Unsupervised Semantic Segmentation
Jul 17, 2024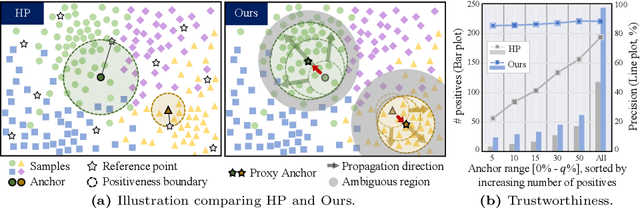
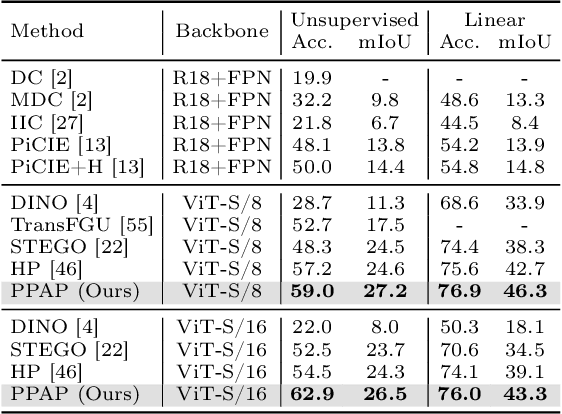
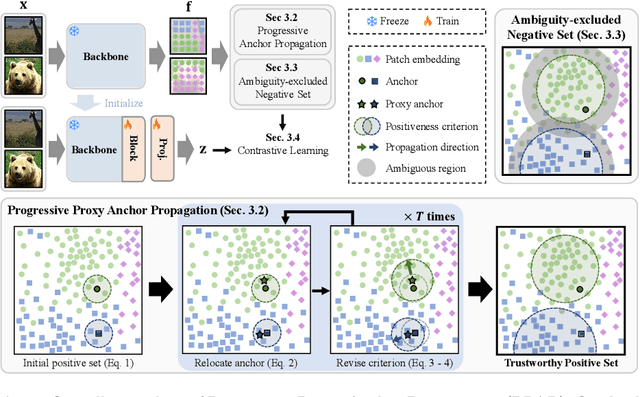
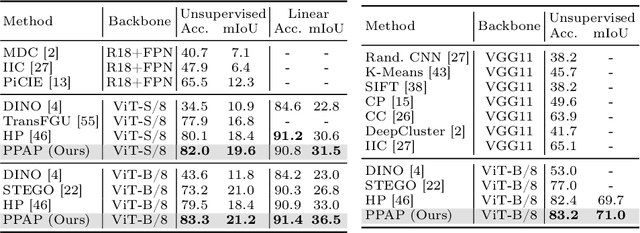
The labor-intensive labeling for semantic segmentation has spurred the emergence of Unsupervised Semantic Segmentation. Recent studies utilize patch-wise contrastive learning based on features from image-level self-supervised pretrained models. However, relying solely on similarity-based supervision from image-level pretrained models often leads to unreliable guidance due to insufficient patch-level semantic representations. To address this, we propose a Progressive Proxy Anchor Propagation (PPAP) strategy. This method gradually identifies more trustworthy positives for each anchor by relocating its proxy to regions densely populated with semantically similar samples. Specifically, we initially establish a tight boundary to gather a few reliable positive samples around each anchor. Then, considering the distribution of positive samples, we relocate the proxy anchor towards areas with a higher concentration of positives and adjust the positiveness boundary based on the propagation degree of the proxy anchor. Moreover, to account for ambiguous regions where positive and negative samples may coexist near the positiveness boundary, we introduce an instance-wise ambiguous zone. Samples within these zones are excluded from the negative set, further enhancing the reliability of the negative set. Our state-of-the-art performances on various datasets validate the effectiveness of the proposed method for Unsupervised Semantic Segmentation.
Task-Disruptive Background Suppression for Few-Shot Segmentation
Dec 26, 2023Few-shot segmentation aims to accurately segment novel target objects within query images using only a limited number of annotated support images. The recent works exploit support background as well as its foreground to precisely compute the dense correlations between query and support. However, they overlook the characteristics of the background that generally contains various types of objects. In this paper, we highlight this characteristic of background which can bring problematic cases as follows: (1) when the query and support backgrounds are dissimilar and (2) when objects in the support background are similar to the target object in the query. Without any consideration of the above cases, adopting the entire support background leads to a misprediction of the query foreground as background. To address this issue, we propose Task-disruptive Background Suppression (TBS), a module to suppress those disruptive support background features based on two spatial-wise scores: query-relevant and target-relevant scores. The former aims to mitigate the impact of unshared features solely existing in the support background, while the latter aims to reduce the influence of target-similar support background features. Based on these two scores, we define a query background relevant score that captures the similarity between the backgrounds of the query and the support, and utilize it to scale support background features to adaptively restrict the impact of disruptive support backgrounds. Our proposed method achieves state-of-the-art performance on PASCAL-5 and COCO-20 datasets on 1-shot segmentation. Our official code is available at github.com/SuhoPark0706/TBSNet.
Task-Oriented Channel Attention for Fine-Grained Few-Shot Classification
Jul 28, 2023The difficulty of the fine-grained image classification mainly comes from a shared overall appearance across classes. Thus, recognizing discriminative details, such as eyes and beaks for birds, is a key in the task. However, this is particularly challenging when training data is limited. To address this, we propose Task Discrepancy Maximization (TDM), a task-oriented channel attention method tailored for fine-grained few-shot classification with two novel modules Support Attention Module (SAM) and Query Attention Module (QAM). SAM highlights channels encoding class-wise discriminative features, while QAM assigns higher weights to object-relevant channels of the query. Based on these submodules, TDM produces task-adaptive features by focusing on channels encoding class-discriminative details and possessed by the query at the same time, for accurate class-sensitive similarity measure between support and query instances. While TDM influences high-level feature maps by task-adaptive calibration of channel-wise importance, we further introduce Instance Attention Module (IAM) operating in intermediate layers of feature extractors to instance-wisely highlight object-relevant channels, by extending QAM. The merits of TDM and IAM and their complementary benefits are experimentally validated in fine-grained few-shot classification tasks. Moreover, IAM is also shown to be effective in coarse-grained and cross-domain few-shot classifications.