 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction-Guided Slot Curriculum: Addressing Object Over-Fragmentation in Video Object-Centric Learning
Mar 24, 2026Video Object-Centric Learning seeks to decompose raw videos into a small set of object slots, but existing slot-attention models often suffer from severe over-fragmentation. This is because the model is implicitly encouraged to occupy all slots to minimize the reconstruction objective, thereby representing a single object with multiple redundant slots. We tackle this limitation with a reconstruction-guided slot curriculum (SlotCurri). Training starts with only a few coarse slots and progressively allocates new slots where reconstruction error remains high, thus expanding capacity only where it is needed and preventing fragmentation from the outset. Yet, during slot expansion, meaningful sub-parts can emerge only if coarse-level semantics are already well separated; however, with a small initial slot budget and an MSE objective, semantic boundaries remain blurry. Therefore, we augment MSE with a structure-aware loss that preserves local contrast and edge information to encourage each slot to sharpen its semantic boundaries. Lastly, we propose a cyclic inference that rolls slots forward and then backward through the frame sequence, producing temporally consistent object representations even in the earliest frames. All combined, SlotCurri addresses object over-fragmentation by allocating representational capacity where reconstruction fails, further enhanced by structural cues and cyclic inference. Notable FG-ARI gains of +6.8 on YouTube-VIS and +8.3 on MOVi-C validate the effectiveness of SlotCurri. Our code is available at github.com/wjun0830/SlotCurri.
Looking Beyond the Window: Global-Local Aligned CLIP for Training-free Open-Vocabulary Semantic Segmentation
Mar 24, 2026A sliding-window inference strategy is commonly adopted in recent training-free open-vocabulary semantic segmentation methods to overcome limitation of the CLIP in processing high-resolution images. However, this approach introduces a new challenge: each window is processed independently, leading to semantic discrepancy across windows. To address this issue, we propose Global-Local Aligned CLIP~(GLA-CLIP), a framework that facilitates comprehensive information exchange across windows. Rather than limiting attention to tokens within individual windows, GLA-CLIP extends key-value tokens to incorporate contextual cues from all windows. Nevertheless, we observe a window bias: outer-window tokens are less likely to be attended, since query features are produced through interactions within the inner window patches, thereby lacking semantic grounding beyond their local context. To mitigate this, we introduce a proxy anchor, constructed by aggregating tokens highly similar to the given query from all windows, which provides a unified semantic reference for measuring similarity across both inner- and outer-window patches. Furthermore, we propose a dynamic normalization scheme that adjusts attention strength according to object scale by dynamically scaling and thresholding the attention map to cope with small-object scenarios. Moreover, GLA-CLIP can be equipped on existing methods and broad their receptive field. Extensive experiments validate the effectiveness of GLA-CLIP in enhancing training-free open-vocabulary semantic segmentation performance. Code is available at https://github.com/2btlFe/GLA-CLIP.
SeaCache: Spectral-Evolution-Aware Cache for Accelerating Diffusion Models
Feb 22, 2026Diffusion models are a strong backbone for visual generation, but their inherently sequential denoising process leads to slow inference. Previous methods accelerate sampling by caching and reusing intermediate outputs based on feature distances between adjacent timesteps. However, existing caching strategies typically rely on raw feature differences that entangle content and noise. This design overlooks spectral evolution, where low-frequency structure appears early and high-frequency detail is refined later. We introduce Spectral-Evolution-Aware Cache (SeaCache), a training-free cache schedule that bases reuse decisions on a spectrally aligned representation. Through theoretical and empirical analysis, we derive a Spectral-Evolution-Aware (SEA) filter that preserves content-relevant components while suppressing noise. Employing SEA-filtered input features to estimate redundancy leads to dynamic schedules that adapt to content while respecting the spectral priors underlying the diffusion model. Extensive experiments on diverse visual generative models and the baselines show that SeaCache achieves state-of-the-art latency-quality trade-offs.
From Vicious to Virtuous Cycles: Synergistic Representation Learning for Unsupervised Video Object-Centric Learning
Feb 03, 2026Unsupervised object-centric learning models, particularly slot-based architectures, have shown great promise in decomposing complex scenes. However, their reliance on reconstruction-based training creates a fundamental conflict between the sharp, high-frequency attention maps of the encoder and the spatially consistent but blurry reconstruction maps of the decoder. We identify that this discrepancy gives rise to a vicious cycle: the noisy feature map from the encoder forces the decoder to average over possibilities and produce even blurrier outputs, while the gradient computed from blurry reconstruction maps lacks high-frequency details necessary to supervise encoder features. To break this cycle, we introduce Synergistic Representation Learning (SRL) that establishes a virtuous cycle where the encoder and decoder mutually refine one another. SRL leverages the encoder's sharpness to deblur the semantic boundary within the decoder output, while exploiting the decoder's spatial consistency to denoise the encoder's features. This mutual refinement process is stabilized by a warm-up phase with a slot regularization objective that initially allocates distinct entities per slot. By bridging the representational gap between the encoder and decoder, SRL achieves state-of-the-art results on video object-centric learning benchmarks. Codes are available at https://github.com/hynnsk/SRL.
Auxiliary Descriptive Knowledge for Few-Shot Adaptation of Vision-Language Model
Dec 19, 2025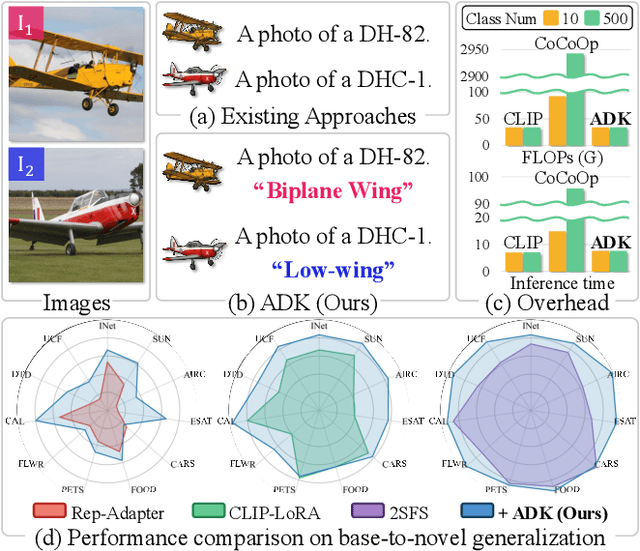
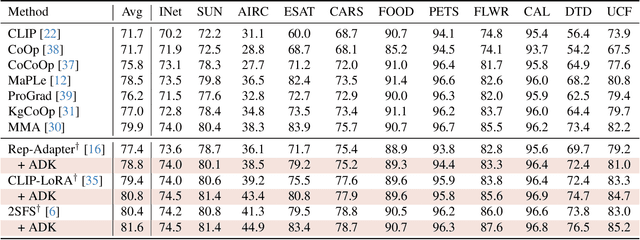
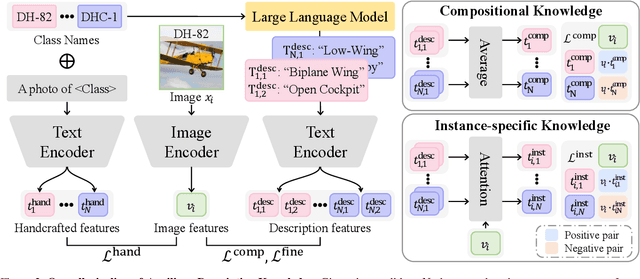
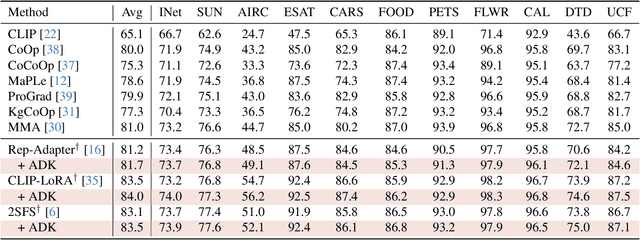
Despite the impressive zero-shot capabilities of Vision-Language Models (VLMs), they often struggle in downstream tasks with distribution shifts from the pre-training data. Few-Shot Adaptation (FSA-VLM) has emerged as a key solution, typically using Parameter-Efficient Fine-Tuning (PEFT) to adapt models with minimal data. However, these PEFT methods are constrained by their reliance on fixed, handcrafted prompts, which are often insufficient to understand the semantics of classes. While some studies have proposed leveraging image-induced prompts to provide additional clues for classification, they introduce prohibitive computational overhead at inference. Therefore, we introduce Auxiliary Descriptive Knowledge (ADK), a novel framework that efficiently enriches text representations without compromising efficiency. ADK first leverages a Large Language Model to generate a rich set of descriptive prompts for each class offline. These pre-computed features are then deployed in two ways: (1) as Compositional Knowledge, an averaged representation that provides rich semantics, especially beneficial when class names are ambiguous or unfamiliar to the VLM; and (2) as Instance-Specific Knowledge, where a lightweight, non-parametric attention mechanism dynamically selects the most relevant descriptions for a given image. This approach provides two additional types of knowledge alongside the handcrafted prompt, thereby facilitating category distinction across various domains. Also, ADK acts as a parameter-free, plug-and-play component that enhances existing PEFT methods. Extensive experiments demonstrate that ADK consistently boosts the performance of multiple PEFT baselines, setting a new state-of-the-art across various scenarios.
Mitigating Semantic Collapse in Partially Relevant Video Retrieval
Oct 31, 2025
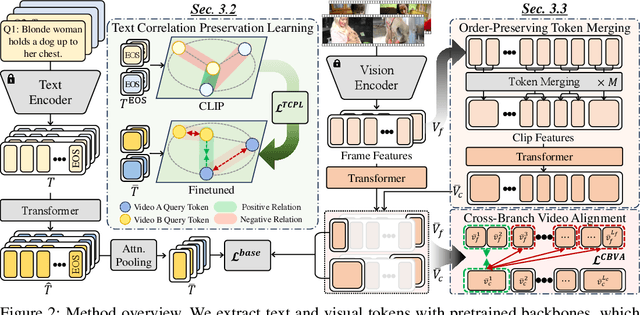
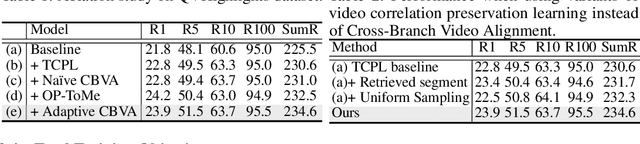
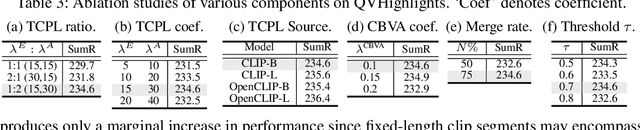
Partially Relevant Video Retrieval (PRVR) seeks videos where only part of the content matches a text query. Existing methods treat every annotated text-video pair as a positive and all others as negatives, ignoring the rich semantic variation both within a single video and across different videos. Consequently, embeddings of both queries and their corresponding video-clip segments for distinct events within the same video collapse together, while embeddings of semantically similar queries and segments from different videos are driven apart. This limits retrieval performance when videos contain multiple, diverse events. This paper addresses the aforementioned problems, termed as semantic collapse, in both the text and video embedding spaces. We first introduce Text Correlation Preservation Learning, which preserves the semantic relationships encoded by the foundation model across text queries. To address collapse in video embeddings, we propose Cross-Branch Video Alignment (CBVA), a contrastive alignment method that disentangles hierarchical video representations across temporal scales. Subsequently, we introduce order-preserving token merging and adaptive CBVA to enhance alignment by producing video segments that are internally coherent yet mutually distinctive. Extensive experiments on PRVR benchmarks demonstrate that our framework effectively prevents semantic collapse and substantially improves retrieval accuracy.
White Aggregation and Restoration for Few-shot 3D Point Cloud Semantic Segmentation
Sep 17, 2025Few-Shot 3D Point Cloud Segmentation (FS-PCS) aims to predict per-point labels for an unlabeled point cloud, given only a few labeled examples. To extract discriminative representations from the limited support set, existing methods have constructed prototypes using conventional algorithms such as farthest point sampling. However, we point out that its initial randomness significantly affects FS-PCS performance and that the prototype generation process remains underexplored despite its prevalence. This motivates us to investigate an advanced prototype generation method based on attention mechanism. Despite its potential, we found that vanilla module suffers from the distributional gap between learnable prototypical tokens and support features. To overcome this, we propose White Aggregation and Restoration Module (WARM), which resolves the misalignment by sandwiching cross-attention between whitening and coloring transformations. Specifically, whitening aligns the support features to prototypical tokens before attention process, and subsequently coloring restores the original distribution to the attended tokens. This simple yet effective design enables robust attention, thereby generating representative prototypes by capturing the semantic relationships among support features. Our method achieves state-of-the-art performance with a significant margin on multiple FS-PCS benchmarks, demonstrating its effectiveness through extensive experiments.
Translation of Text Embedding via Delta Vector to Suppress Strongly Entangled Content in Text-to-Image Diffusion Models
Aug 14, 2025Text-to-Image (T2I) diffusion models have made significant progress in generating diverse high-quality images from textual prompts. However, these models still face challenges in suppressing content that is strongly entangled with specific words. For example, when generating an image of ``Charlie Chaplin", a ``mustache" consistently appears even if explicitly instructed not to include it, as the concept of ``mustache" is strongly entangled with ``Charlie Chaplin". To address this issue, we propose a novel approach to directly suppress such entangled content within the text embedding space of diffusion models. Our method introduces a delta vector that modifies the text embedding to weaken the influence of undesired content in the generated image, and we further demonstrate that this delta vector can be easily obtained through a zero-shot approach. Furthermore, we propose a Selective Suppression with Delta Vector (SSDV) method to adapt delta vector into the cross-attention mechanism, enabling more effective suppression of unwanted content in regions where it would otherwise be generated. Additionally, we enabled more precise suppression in personalized T2I models by optimizing delta vector, which previous baselines were unable to achieve. Extensive experimental results demonstrate that our approach significantly outperforms existing methods, both in terms of quantitative and qualitative metrics.
Selective Contrastive Learning for Weakly Supervised Affordance Grounding
Aug 11, 2025Facilitating an entity's interaction with objects requires accurately identifying parts that afford specific actions. Weakly supervised affordance grounding (WSAG) seeks to imitate human learning from third-person demonstrations, where humans intuitively grasp functional parts without needing pixel-level annotations. To achieve this, grounding is typically learned using a shared classifier across images from different perspectives, along with distillation strategies incorporating part discovery process. However, since affordance-relevant parts are not always easily distinguishable, models primarily rely on classification, often focusing on common class-specific patterns that are unrelated to affordance. To address this limitation, we move beyond isolated part-level learning by introducing selective prototypical and pixel contrastive objectives that adaptively learn affordance-relevant cues at both the part and object levels, depending on the granularity of the available information. Initially, we find the action-associated objects in both egocentric (object-focused) and exocentric (third-person example) images by leveraging CLIP. Then, by cross-referencing the discovered objects of complementary views, we excavate the precise part-level affordance clues in each perspective. By consistently learning to distinguish affordance-relevant regions from affordance-irrelevant background context, our approach effectively shifts activation from irrelevant areas toward meaningful affordance cues. Experimental results demonstrate the effectiveness of our method. Codes are available at github.com/hynnsk/SelectiveCL.
Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval
Apr 17, 2025In a retrieval system, simultaneously achieving search accuracy and efficiency is inherently challenging. This challenge is particularly pronounced in partially relevant video retrieval (PRVR), where incorporating more diverse context representations at varying temporal scales for each video enhances accuracy but increases computational and memory costs. To address this dichotomy, we propose a prototypical PRVR framework that encodes diverse contexts within a video into a fixed number of prototypes. We then introduce several strategies to enhance text association and video understanding within the prototypes, along with an orthogonal objective to ensure that the prototypes capture a diverse range of content. To keep the prototypes searchable via text queries while accurately encoding video contexts, we implement cross- and uni-modal reconstruction tasks. The cross-modal reconstruction task aligns the prototypes with textual features within a shared space, while the uni-modal reconstruction task preserves all video contexts during encoding. Additionally, we employ a video mixing technique to provide weak guidance to further align prototypes and associated textual representations. Extensive evaluations on TVR, ActivityNet-Captions, and QVHighlights validate the effectiveness of our approach without sacrificing efficiency.