 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Can't I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition
Jan 22, 2026We study Compositional Video Understanding (CVU), where models must recognize verbs and objects and compose them to generalize to unseen combinations. We find that existing Zero-Shot Compositional Action Recognition (ZS-CAR) models fail primarily due to an overlooked failure mode: object-driven verb shortcuts. Through systematic analysis, we show that this behavior arises from two intertwined factors: severe sparsity and skewness of compositional supervision, and the asymmetric learning difficulty between verbs and objects. As training progresses, the existing ZS-CAR model increasingly ignores visual evidence and overfits to co-occurrence statistics. Consequently, the existing model does not gain the benefit of compositional recognition in unseen verb-object compositions. To address this, we propose RCORE, a simple and effective framework that enforces temporally grounded verb learning. RCORE introduces (i) a composition-aware augmentation that diversifies verb-object combinations without corrupting motion cues, and (ii) a temporal order regularization loss that penalizes shortcut behaviors by explicitly modeling temporal structure. Across two benchmarks, Sth-com and our newly constructed EK100-com, RCORE significantly improves unseen composition accuracy, reduces reliance on co-occurrence bias, and achieves consistently positive compositional gaps. Our findings reveal object-driven shortcuts as a critical limiting factor in ZS-CAR and demonstrate that addressing them is essential for robust compositional video understanding.
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jul 10, 2025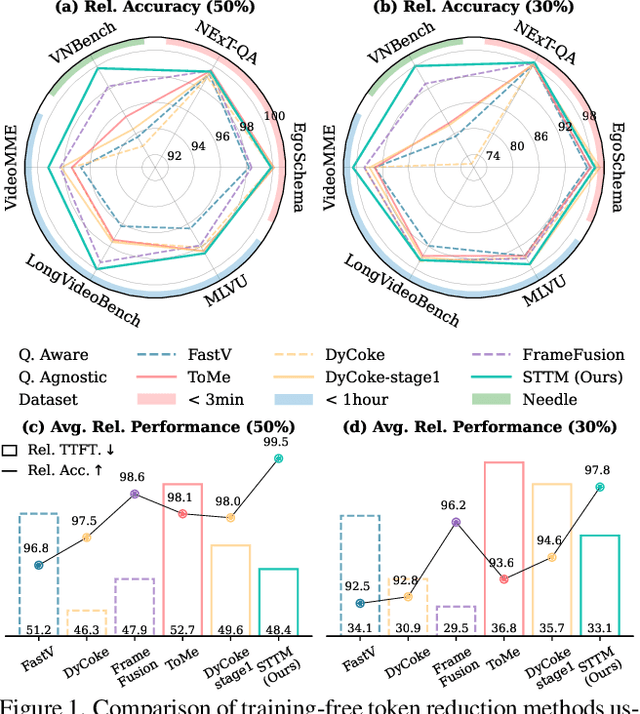

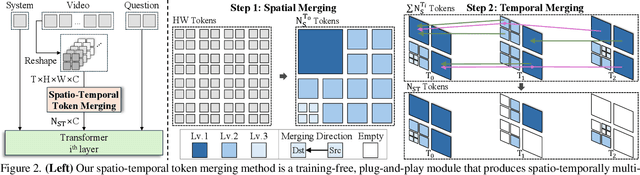

Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval
Apr 17, 2025In a retrieval system, simultaneously achieving search accuracy and efficiency is inherently challenging. This challenge is particularly pronounced in partially relevant video retrieval (PRVR), where incorporating more diverse context representations at varying temporal scales for each video enhances accuracy but increases computational and memory costs. To address this dichotomy, we propose a prototypical PRVR framework that encodes diverse contexts within a video into a fixed number of prototypes. We then introduce several strategies to enhance text association and video understanding within the prototypes, along with an orthogonal objective to ensure that the prototypes capture a diverse range of content. To keep the prototypes searchable via text queries while accurately encoding video contexts, we implement cross- and uni-modal reconstruction tasks. The cross-modal reconstruction task aligns the prototypes with textual features within a shared space, while the uni-modal reconstruction task preserves all video contexts during encoding. Additionally, we employ a video mixing technique to provide weak guidance to further align prototypes and associated textual representations. Extensive evaluations on TVR, ActivityNet-Captions, and QVHighlights validate the effectiveness of our approach without sacrificing efficiency.
Classification Matters: Improving Video Action Detection with Class-Specific Attention
Jul 29, 2024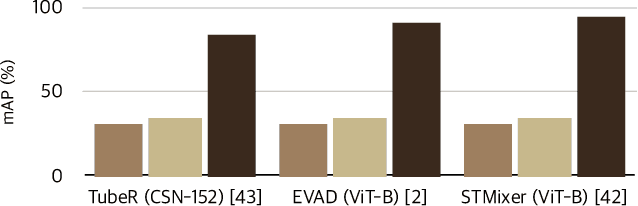
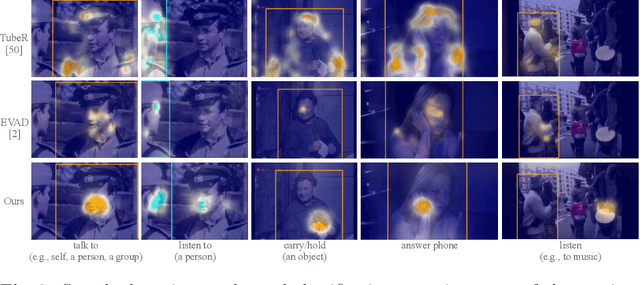
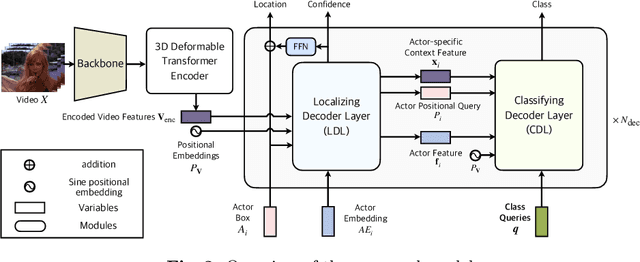
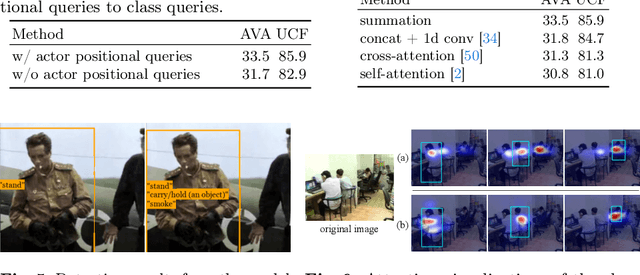
Video action detection (VAD) aims to detect actors and classify their actions in a video. We figure that VAD suffers more from classification rather than localization of actors. Hence, we analyze how prevailing methods form features for classification and find that they prioritize actor regions, yet often overlooking the essential contextual information necessary for accurate classification. Accordingly, we propose to reduce the bias toward actor and encourage paying attention to the context that is relevant to each action class. By assigning a class-dedicated query to each action class, our model can dynamically determine where to focus for effective classification. The proposed model demonstrates superior performance on three challenging benchmarks with significantly fewer parameters and less computation.