 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-Oasis: Rethinking Evaluation of Video Understanding
Mar 31, 2026The inherent complexity of video understanding makes it difficult to attribute whether performance gains stem from visual perception, linguistic reasoning, or knowledge priors. While many benchmarks have emerged to assess high-level reasoning, the essential criteria that constitute video understanding remain largely overlooked. Instead of introducing yet another benchmark, we take a step back to re-examine the current landscape of video understanding. In this work, we provide Video-Oasis, a sustainable diagnostic suite designed to systematically evaluate existing evaluations and distill spatio-temporal challenges for video understanding. Our analysis reveals two critical findings: (1) 54% of existing benchmark samples are solvable without visual input or temporal context, and (2) on the remaining samples, state-of-the-art models exhibit performance barely exceeding random guessing. To bridge this gap, we investigate which algorithmic design choices contribute to robust video understanding, providing practical guidelines for future research. We hope our work serves as a standard guideline for benchmark construction and the rigorous evaluation of architecture development. Code is available at https://github.com/sejong-rcv/Video-Oasis.
Why Can't I Open My Drawer? Mitigating Object-Driven Shortcuts in Zero-Shot Compositional Action Recognition
Jan 22, 2026We study Compositional Video Understanding (CVU), where models must recognize verbs and objects and compose them to generalize to unseen combinations. We find that existing Zero-Shot Compositional Action Recognition (ZS-CAR) models fail primarily due to an overlooked failure mode: object-driven verb shortcuts. Through systematic analysis, we show that this behavior arises from two intertwined factors: severe sparsity and skewness of compositional supervision, and the asymmetric learning difficulty between verbs and objects. As training progresses, the existing ZS-CAR model increasingly ignores visual evidence and overfits to co-occurrence statistics. Consequently, the existing model does not gain the benefit of compositional recognition in unseen verb-object compositions. To address this, we propose RCORE, a simple and effective framework that enforces temporally grounded verb learning. RCORE introduces (i) a composition-aware augmentation that diversifies verb-object combinations without corrupting motion cues, and (ii) a temporal order regularization loss that penalizes shortcut behaviors by explicitly modeling temporal structure. Across two benchmarks, Sth-com and our newly constructed EK100-com, RCORE significantly improves unseen composition accuracy, reduces reliance on co-occurrence bias, and achieves consistently positive compositional gaps. Our findings reveal object-driven shortcuts as a critical limiting factor in ZS-CAR and demonstrate that addressing them is essential for robust compositional video understanding.
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jul 10, 2025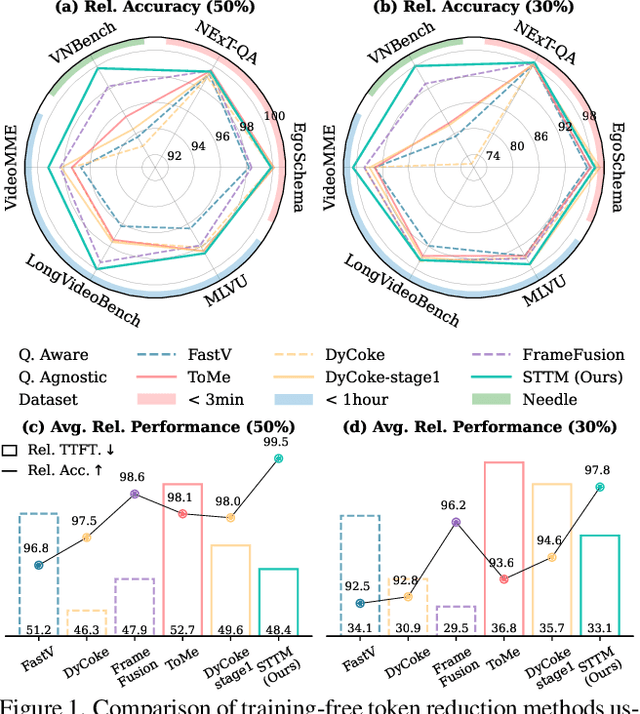

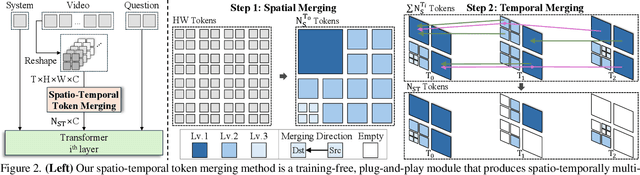

Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
Prototypes are Balanced Units for Efficient and Effective Partially Relevant Video Retrieval
Apr 17, 2025In a retrieval system, simultaneously achieving search accuracy and efficiency is inherently challenging. This challenge is particularly pronounced in partially relevant video retrieval (PRVR), where incorporating more diverse context representations at varying temporal scales for each video enhances accuracy but increases computational and memory costs. To address this dichotomy, we propose a prototypical PRVR framework that encodes diverse contexts within a video into a fixed number of prototypes. We then introduce several strategies to enhance text association and video understanding within the prototypes, along with an orthogonal objective to ensure that the prototypes capture a diverse range of content. To keep the prototypes searchable via text queries while accurately encoding video contexts, we implement cross- and uni-modal reconstruction tasks. The cross-modal reconstruction task aligns the prototypes with textual features within a shared space, while the uni-modal reconstruction task preserves all video contexts during encoding. Additionally, we employ a video mixing technique to provide weak guidance to further align prototypes and associated textual representations. Extensive evaluations on TVR, ActivityNet-Captions, and QVHighlights validate the effectiveness of our approach without sacrificing efficiency.
CoMoGaussian: Continuous Motion-Aware Gaussian Splatting from Motion-Blurred Images
Mar 07, 20253D Gaussian Splatting (3DGS) has gained significant attention for their high-quality novel view rendering, motivating research to address real-world challenges. A critical issue is the camera motion blur caused by movement during exposure, which hinders accurate 3D scene reconstruction. In this study, we propose CoMoGaussian, a Continuous Motion-Aware Gaussian Splatting that reconstructs precise 3D scenes from motion-blurred images while maintaining real-time rendering speed. Considering the complex motion patterns inherent in real-world camera movements, we predict continuous camera trajectories using neural ordinary differential equations (ODEs). To ensure accurate modeling, we employ rigid body transformations, preserving the shape and size of the object but rely on the discrete integration of sampled frames. To better approximate the continuous nature of motion blur, we introduce a continuous motion refinement (CMR) transformation that refines rigid transformations by incorporating additional learnable parameters. By revisiting fundamental camera theory and leveraging advanced neural ODE techniques, we achieve precise modeling of continuous camera trajectories, leading to improved reconstruction accuracy. Extensive experiments demonstrate state-of-the-art performance both quantitatively and qualitatively on benchmark datasets, which include a wide range of motion blur scenarios, from moderate to extreme blur.
CoCoGaussian: Leveraging Circle of Confusion for Gaussian Splatting from Defocused Images
Dec 20, 2024



3D Gaussian Splatting (3DGS) has attracted significant attention for its high-quality novel view rendering, inspiring research to address real-world challenges. While conventional methods depend on sharp images for accurate scene reconstruction, real-world scenarios are often affected by defocus blur due to finite depth of field, making it essential to account for realistic 3D scene representation. In this study, we propose CoCoGaussian, a Circle of Confusion-aware Gaussian Splatting that enables precise 3D scene representation using only defocused images. CoCoGaussian addresses the challenge of defocus blur by modeling the Circle of Confusion (CoC) through a physically grounded approach based on the principles of photographic defocus. Exploiting 3D Gaussians, we compute the CoC diameter from depth and learnable aperture information, generating multiple Gaussians to precisely capture the CoC shape. Furthermore, we introduce a learnable scaling factor to enhance robustness and provide more flexibility in handling unreliable depth in scenes with reflective or refractive surfaces. Experiments on both synthetic and real-world datasets demonstrate that CoCoGaussian achieves state-of-the-art performance across multiple benchmarks.
A Simple Baseline with Single-encoder for Referring Image Segmentation
Aug 28, 2024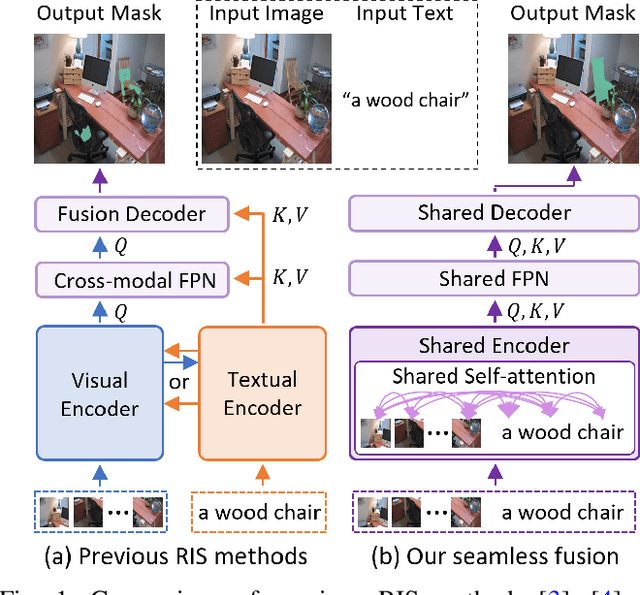
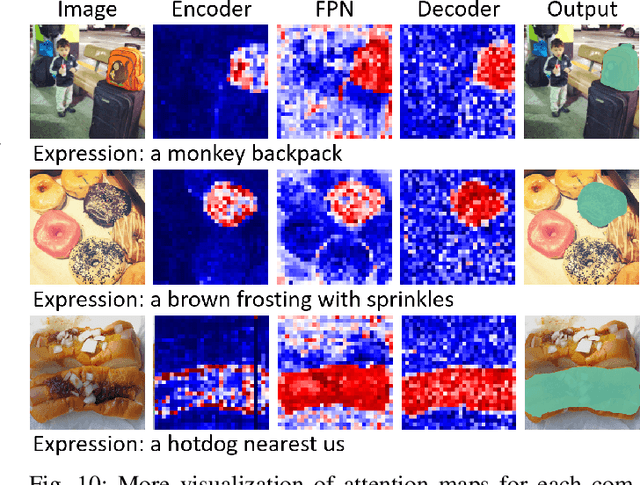


Referring image segmentation (RIS) requires dense vision-language interactions between visual pixels and textual words to segment objects based on a given description. However, commonly adapted dual-encoders in RIS, e.g., Swin transformer and BERT (uni-modal encoders) or CLIP (a multi-modal dual-encoder), lack dense multi-modal interactions during pre-training, leading to a gap with a pixel-level RIS task. To bridge this gap, existing RIS methods often rely on multi-modal fusion modules that interact two encoders, but this approach leads to high computational costs. In this paper, we present a novel RIS method with a single-encoder, i.e., BEiT-3, maximizing the potential of shared self-attention across all framework components. This enables seamless interactions of two modalities from input to final prediction, producing granularly aligned multi-modal features. Furthermore, we propose lightweight yet effective decoder modules, a Shared FPN and a Shared Mask Decoder, which contribute to the high efficiency of our model. Our simple baseline with a single encoder achieves outstanding performances on the RIS benchmark datasets while maintaining computational efficiency, compared to the most recent SoTA methods based on dual-encoders.
Classification Matters: Improving Video Action Detection with Class-Specific Attention
Jul 29, 2024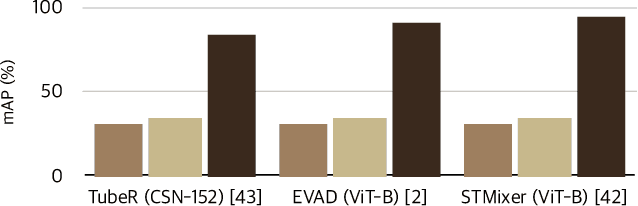
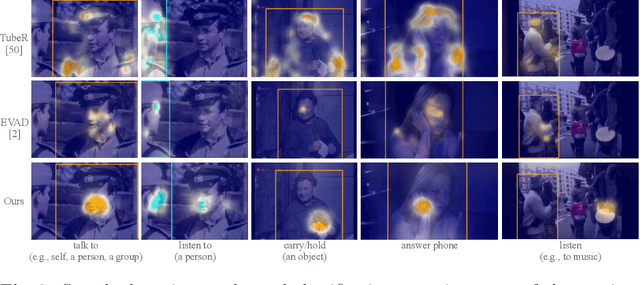
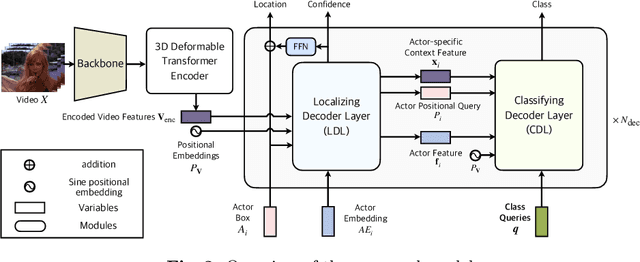
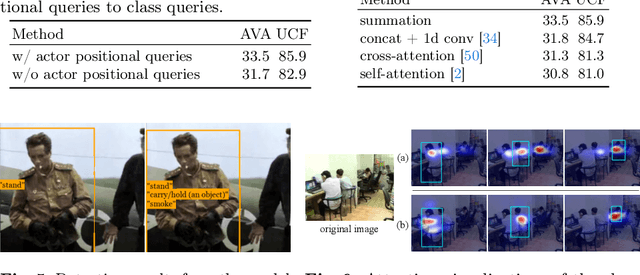
Video action detection (VAD) aims to detect actors and classify their actions in a video. We figure that VAD suffers more from classification rather than localization of actors. Hence, we analyze how prevailing methods form features for classification and find that they prioritize actor regions, yet often overlooking the essential contextual information necessary for accurate classification. Accordingly, we propose to reduce the bias toward actor and encourage paying attention to the context that is relevant to each action class. By assigning a class-dedicated query to each action class, our model can dynamically determine where to focus for effective classification. The proposed model demonstrates superior performance on three challenging benchmarks with significantly fewer parameters and less computation.
Masked Autoencoder for Unsupervised Video Summarization
Jun 02, 2023



Summarizing a video requires a diverse understanding of the video, ranging from recognizing scenes to evaluating how much each frame is essential enough to be selected as a summary. Self-supervised learning (SSL) is acknowledged for its robustness and flexibility to multiple downstream tasks, but the video SSL has not shown its value for dense understanding tasks like video summarization. We claim an unsupervised autoencoder with sufficient self-supervised learning does not need any extra downstream architecture design or fine-tuning weights to be utilized as a video summarization model. The proposed method to evaluate the importance score of each frame takes advantage of the reconstruction score of the autoencoder's decoder. We evaluate the method in major unsupervised video summarization benchmarks to show its effectiveness under various experimental settings.
Decomposed Cross-modal Distillation for RGB-based Temporal Action Detection
Mar 30, 2023
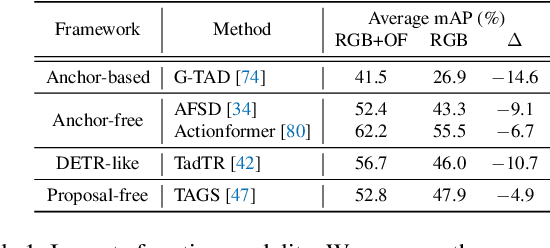

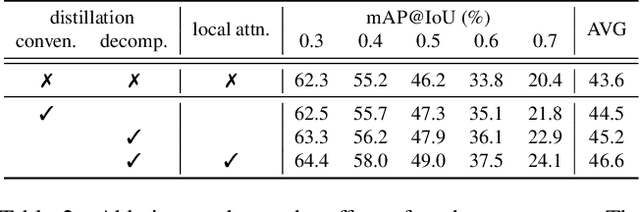
Temporal action detection aims to predict the time intervals and the classes of action instances in the video. Despite the promising performance, existing two-stream models exhibit slow inference speed due to their reliance on computationally expensive optical flow. In this paper, we introduce a decomposed cross-modal distillation framework to build a strong RGB-based detector by transferring knowledge of the motion modality. Specifically, instead of direct distillation, we propose to separately learn RGB and motion representations, which are in turn combined to perform action localization. The dual-branch design and the asymmetric training objectives enable effective motion knowledge transfer while preserving RGB information intact. In addition, we introduce a local attentive fusion to better exploit the multimodal complementarity. It is designed to preserve the local discriminability of the features that is important for action localization. Extensive experiments on the benchmarks verify the effectiveness of the proposed method in enhancing RGB-based action detectors. Notably, our framework is agnostic to backbones and detection heads, bringing consistent gains across different model combinations.