 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline with Single-encoder for Referring Image Segmentation
Aug 28, 2024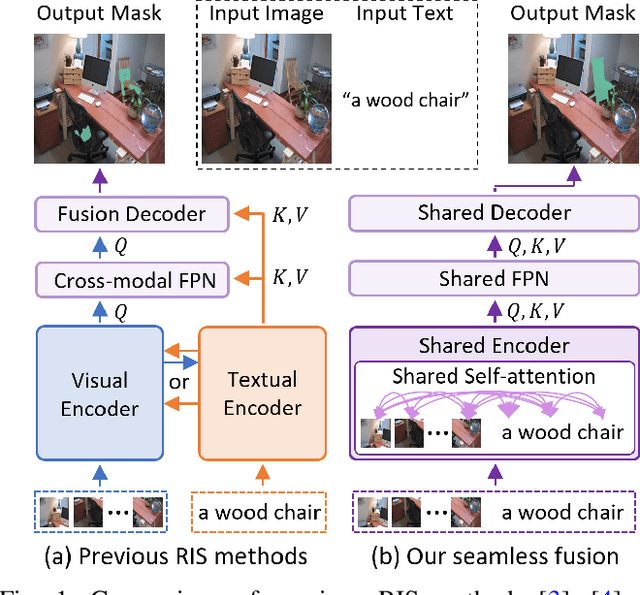
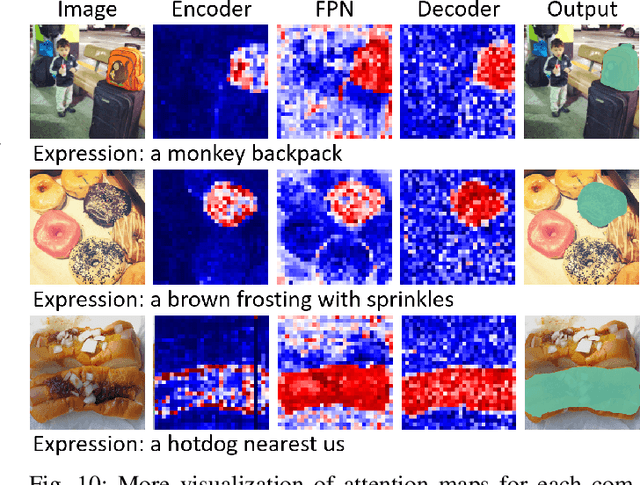


Referring image segmentation (RIS) requires dense vision-language interactions between visual pixels and textual words to segment objects based on a given description. However, commonly adapted dual-encoders in RIS, e.g., Swin transformer and BERT (uni-modal encoders) or CLIP (a multi-modal dual-encoder), lack dense multi-modal interactions during pre-training, leading to a gap with a pixel-level RIS task. To bridge this gap, existing RIS methods often rely on multi-modal fusion modules that interact two encoders, but this approach leads to high computational costs. In this paper, we present a novel RIS method with a single-encoder, i.e., BEiT-3, maximizing the potential of shared self-attention across all framework components. This enables seamless interactions of two modalities from input to final prediction, producing granularly aligned multi-modal features. Furthermore, we propose lightweight yet effective decoder modules, a Shared FPN and a Shared Mask Decoder, which contribute to the high efficiency of our model. Our simple baseline with a single encoder achieves outstanding performances on the RIS benchmark datasets while maintaining computational efficiency, compared to the most recent SoTA methods based on dual-encoders.
Online Hybrid Lightweight Representations Learning: Its Application to Visual Tracking
May 23, 2022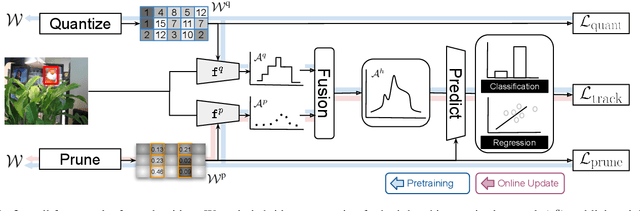
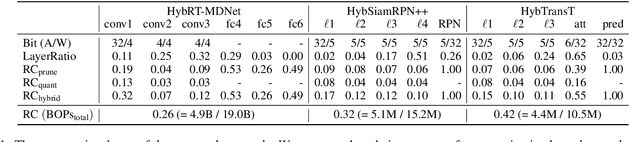
This paper presents a novel hybrid representation learning framework for streaming data, where an image frame in a video is modeled by an ensemble of two distinct deep neural networks; one is a low-bit quantized network and the other is a lightweight full-precision network. The former learns coarse primary information with low cost while the latter conveys residual information for high fidelity to original representations. The proposed parallel architecture is effective to maintain complementary information since fixed-point arithmetic can be utilized in the quantized network and the lightweight model provides precise representations given by a compact channel-pruned network. We incorporate the hybrid representation technique into an online visual tracking task, where deep neural networks need to handle temporal variations of target appearances in real-time. Compared to the state-of-the-art real-time trackers based on conventional deep neural networks, our tracking algorithm demonstrates competitive accuracy on the standard benchmarks with a small fraction of computational cost and memory footprint.
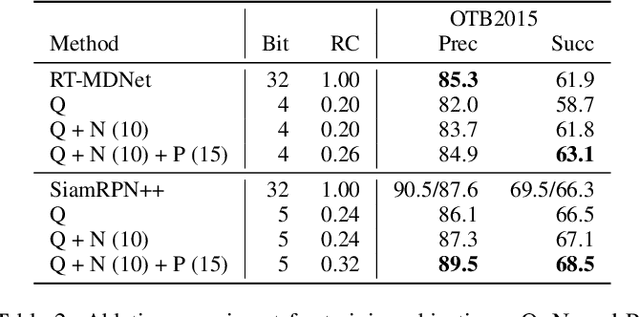
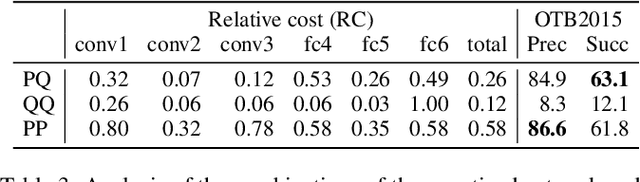
Real-Time Object Tracking via Meta-Learning: Efficient Model Adaptation and One-Shot Channel Pruning
Dec 04, 2019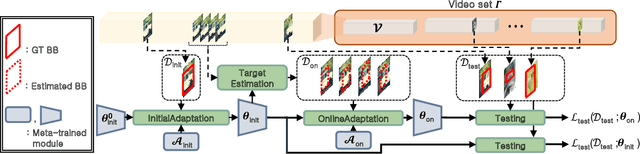

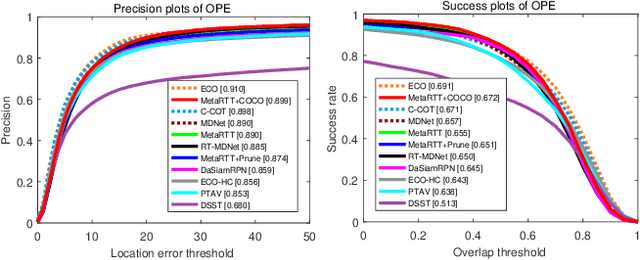
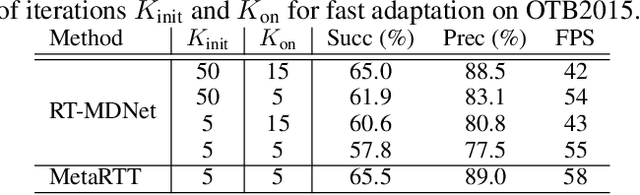
We propose a novel meta-learning framework for real-time object tracking with efficient model adaptation and channel pruning. Given an object tracker, our framework learns to fine-tune its model parameters in only a few iterations of gradient-descent during tracking while pruning its network channels using the target ground-truth at the first frame. Such a learning problem is formulated as a meta-learning task, where a meta-tracker is trained by updating its meta-parameters for initial weights, learning rates, and pruning masks through carefully designed tracking simulations. The integrated meta-tracker greatly improves tracking performance by accelerating the convergence of online learning and reducing the cost of feature computation. Experimental evaluation on the standard datasets demonstrates its outstanding accuracy and speed compared to the state-of-the-art methods.
Real-Time MDNet
Aug 27, 2018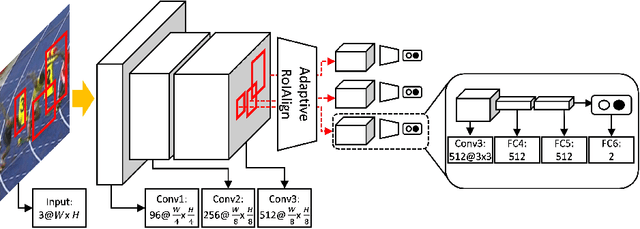

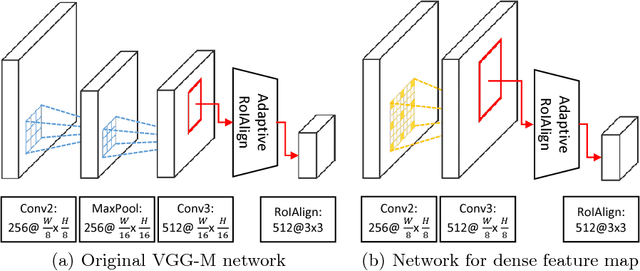

We present a fast and accurate visual tracking algorithm based on the multi-domain convolutional neural network (MDNet). The proposed approach accelerates feature extraction procedure and learns more discriminative models for instance classification; it enhances representation quality of target and background by maintaining a high resolution feature map with a large receptive field per activation. We also introduce a novel loss term to differentiate foreground instances across multiple domains and learn a more discriminative embedding of target objects with similar semantics. The proposed techniques are integrated into the pipeline of a well known CNN-based visual tracking algorithm, MDNet. We accomplish approximately 25 times speed-up with almost identical accuracy compared to MDNet. Our algorithm is evaluated in multiple popular tracking benchmark datasets including OTB2015, UAV123, and TempleColor, and outperforms the state-of-the-art real-time tracking methods consistently even without dataset-specific parameter tuning.
MarioQA: Answering Questions by Watching Gameplay Videos
Aug 13, 2017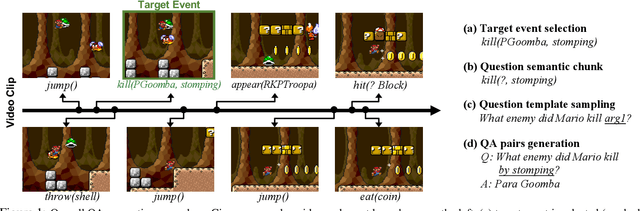


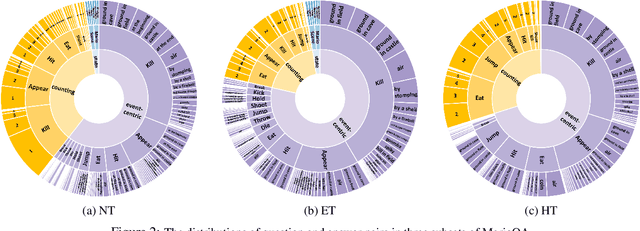
We present a framework to analyze various aspects of models for video question answering (VideoQA) using customizable synthetic datasets, which are constructed automatically from gameplay videos. Our work is motivated by the fact that existing models are often tested only on datasets that require excessively high-level reasoning or mostly contain instances accessible through single frame inferences. Hence, it is difficult to measure capacity and flexibility of trained models, and existing techniques often rely on ad-hoc implementations of deep neural networks without clear insight into datasets and models. We are particularly interested in understanding temporal relationships between video events to solve VideoQA problems; this is because reasoning temporal dependency is one of the most distinct components in videos from images. To address this objective, we automatically generate a customized synthetic VideoQA dataset using {\em Super Mario Bros.} gameplay videos so that it contains events with different levels of reasoning complexity. Using the dataset, we show that properly constructed datasets with events in various complexity levels are critical to learn effective models and improve overall performance.