 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarioQA: Answering Questions by Watching Gameplay Videos
Paper and Code
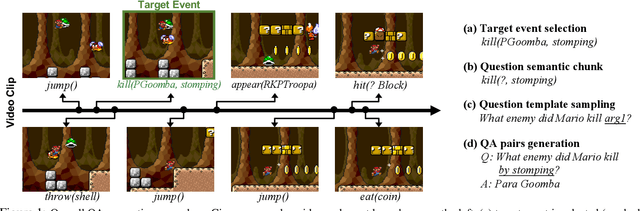


We present a framework to analyze various aspects of models for video question answering (VideoQA) using customizable synthetic datasets, which are constructed automatically from gameplay videos. Our work is motivated by the fact that existing models are often tested only on datasets that require excessively high-level reasoning or mostly contain instances accessible through single frame inferences. Hence, it is difficult to measure capacity and flexibility of trained models, and existing techniques often rely on ad-hoc implementations of deep neural networks without clear insight into datasets and models. We are particularly interested in understanding temporal relationships between video events to solve VideoQA problems; this is because reasoning temporal dependency is one of the most distinct components in videos from images. To address this objective, we automatically generate a customized synthetic VideoQA dataset using {\em Super Mario Bros.} gameplay videos so that it contains events with different levels of reasoning complexity. Using the dataset, we show that properly constructed datasets with events in various complexity levels are critical to learn effective models and improve overall performance.