 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP-4DGS: Probabilistic 4D Gaussian Splatting from Monocular Video via Variational Gaussian Processes
Apr 03, 2026We present GP-4DGS, a novel framework that integrates Gaussian Processes (GPs) into 4D Gaussian Splatting (4DGS) for principled probabilistic modeling of dynamic scenes. While existing 4DGS methods focus on deterministic reconstruction, they are inherently limited in capturing motion ambiguity and lack mechanisms to assess prediction reliability. By leveraging the kernel-based probabilistic nature of GPs, our approach introduces three key capabilities: (i) uncertainty quantification for motion predictions, (ii) motion estimation for unobserved or sparsely sampled regions, and (iii) temporal extrapolation beyond observed training frames. To scale GPs to the large number of Gaussian primitives in 4DGS, we design spatio-temporal kernels that capture the correlation structure of deformation fields and adopt variational Gaussian Processes with inducing points for tractable inference. Our experiments show that GP-4DGS enhances reconstruction quality while providing reliable uncertainty estimates that effectively identify regions of high motion ambiguity. By addressing these challenges, our work takes a meaningful step toward bridging probabilistic modeling and neural graphics.
Pri4R: Learning World Dynamics for Vision-Language-Action Models with Privileged 4D Representation
Mar 02, 2026Humans learn not only how their bodies move, but also how the surrounding world responds to their actions. In contrast, while recent Vision-Language-Action (VLA) models exhibit impressive semantic understanding, they often fail to capture the spatiotemporal dynamics governing physical interaction. In this paper, we introduce Pri4R, a simple yet effective approach that endows VLA models with an implicit understanding of world dynamics by leveraging privileged 4D information during training. Specifically, Pri4R augments VLAs with a lightweight point track head that predicts 3D point tracks. By injecting VLA features into this head to jointly predict future 3D trajectories, the model learns to incorporate evolving scene geometry within its shared representation space, enabling more physically aware context for precise control. Due to its architectural simplicity, Pri4R is compatible with dominant VLA design patterns with minimal changes. During inference, we run the model using the original VLA architecture unchanged; Pri4R adds no extra inputs, outputs, or computational overhead. Across simulation and real-world evaluations, Pri4R significantly improves performance on challenging manipulation tasks, including a +10% gain on LIBERO-Long and a +40% gain on RoboCasa. We further show that 3D point track prediction is an effective supervision target for learning action-world dynamics, and validate our design choices through extensive ablations.
AGDC: Autoregressive Generation of Variable-Length Sequences with Joint Discrete and Continuous Spaces
Jan 09, 2026Transformer-based autoregressive models excel in data generation but are inherently constrained by their reliance on discretized tokens, which limits their ability to represent continuous values with high precision. We analyze the scalability limitations of existing discretization-based approaches for generating hybrid discrete-continuous sequences, particularly in high-precision domains such as semiconductor circuit designs, where precision loss can lead to functional failure. To address the challenge, we propose AGDC, a novel unified framework that jointly models discrete and continuous values for variable-length sequences. AGDC employs a hybrid approach that combines categorical prediction for discrete values with diffusion-based modeling for continuous values, incorporating two key technical components: an end-of-sequence (EOS) logit adjustment mechanism that uses an MLP to dynamically adjust EOS token logits based on sequence context, and a length regularization term integrated into the loss function. Additionally, we present ContLayNet, a large-scale benchmark comprising 334K high-precision semiconductor layout samples with specialized evaluation metrics that capture functional correctness where precision errors significantly impact performance. Experiments on semiconductor layouts (ContLayNet), graphic layouts, and SVGs demonstrate AGDC's superior performance in generating high-fidelity hybrid vector representations compared to discretization-based and fixed-schema baselines, achieving scalable high-precision generation across diverse domains.
Image Diffusion Preview with Consistency Solver
Dec 15, 2025The slow inference process of image diffusion models significantly degrades interactive user experiences. To address this, we introduce Diffusion Preview, a novel paradigm employing rapid, low-step sampling to generate preliminary outputs for user evaluation, deferring full-step refinement until the preview is deemed satisfactory. Existing acceleration methods, including training-free solvers and post-training distillation, struggle to deliver high-quality previews or ensure consistency between previews and final outputs. We propose ConsistencySolver derived from general linear multistep methods, a lightweight, trainable high-order solver optimized via Reinforcement Learning, that enhances preview quality and consistency. Experimental results demonstrate that ConsistencySolver significantly improves generation quality and consistency in low-step scenarios, making it ideal for efficient preview-and-refine workflows. Notably, it achieves FID scores on-par with Multistep DPM-Solver using 47% fewer steps, while outperforming distillation baselines. Furthermore, user studies indicate our approach reduces overall user interaction time by nearly 50% while maintaining generation quality. Code is available at https://github.com/G-U-N/consolver.
TextGuider: Training-Free Guidance for Text Rendering via Attention Alignment
Dec 13, 2025
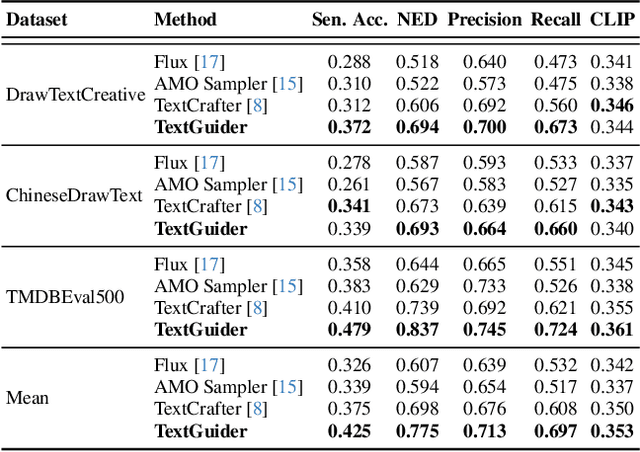
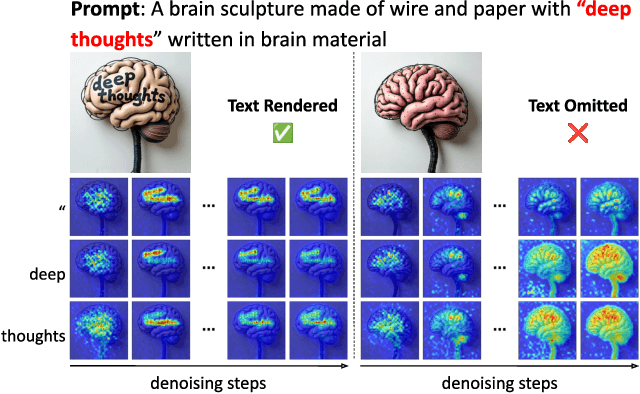
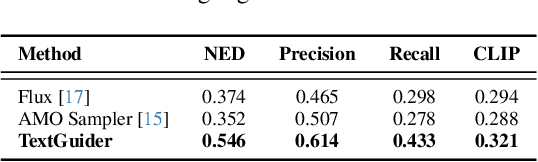
Despite recent advances, diffusion-based text-to-image models still struggle with accurate text rendering. Several studies have proposed fine-tuning or training-free refinement methods for accurate text rendering. However, the critical issue of text omission, where the desired text is partially or entirely missing, remains largely overlooked. In this work, we propose TextGuider, a novel training-free method that encourages accurate and complete text appearance by aligning textual content tokens and text regions in the image. Specifically, we analyze attention patterns in Multi-Modal Diffusion Transformer(MM-DiT) models, particularly for text-related tokens intended to be rendered in the image. Leveraging this observation, we apply latent guidance during the early stage of denoising steps based on two loss functions that we introduce. Our method achieves state-of-the-art performance in test-time text rendering, with significant gains in recall and strong results in OCR accuracy and CLIP score.
Emergence of Text Readability in Vision Language Models
Jun 24, 2025We investigate how the ability to recognize textual content within images emerges during the training of Vision-Language Models (VLMs). Our analysis reveals a critical phenomenon: the ability to read textual information in a given image \textbf{(text readability)} emerges abruptly after substantial training iterations, in contrast to semantic content understanding which develops gradually from the early stages of training. This delayed emergence may reflect how contrastive learning tends to initially prioritize general semantic understanding, with text-specific symbolic processing developing later. Interestingly, the ability to match images with rendered text develops even slower, indicating a deeper need for semantic integration. These findings highlight the need for tailored training strategies to accelerate robust text comprehension in VLMs, laying the groundwork for future research on optimizing multimodal learning.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
Enhanced Diffusion Sampling via Extrapolation with Multiple ODE Solutions
Apr 02, 2025Diffusion probabilistic models (DPMs), while effective in generating high-quality samples, often suffer from high computational costs due to their iterative sampling process. To address this, we propose an enhanced ODE-based sampling method for DPMs inspired by Richardson extrapolation, which reduces numerical error and improves convergence rates. Our method, RX-DPM, leverages multiple ODE solutions at intermediate time steps to extrapolate the denoised prediction in DPMs. This significantly enhances the accuracy of estimations for the final sample while maintaining the number of function evaluations (NFEs). Unlike standard Richardson extrapolation, which assumes uniform discretization of the time grid, we develop a more general formulation tailored to arbitrary time step scheduling, guided by local truncation error derived from a baseline sampling method. The simplicity of our approach facilitates accurate estimation of numerical solutions without significant computational overhead, and allows for seamless and convenient integration into various DPMs and solvers. Additionally, RX-DPM provides explicit error estimates, effectively demonstrating the faster convergence as the leading error term's order increases. Through a series of experiments, we show that the proposed method improves the quality of generated samples without requiring additional sampling iterations.
Fine-Grained Video Captioning through Scene Graph Consolidation
Feb 23, 2025Recent advances in visual language models (VLMs) have significantly improved image captioning, but extending these gains to video understanding remains challenging due to the scarcity of fine-grained video captioning datasets. To bridge this gap, we propose a novel zero-shot video captioning approach that combines frame-level scene graphs from a video to obtain intermediate representations for caption generation. Our method first generates frame-level captions using an image VLM, converts them into scene graphs, and consolidates these graphs to produce comprehensive video-level descriptions. To achieve this, we leverage a lightweight graph-to-text model trained solely on text corpora, eliminating the need for video captioning annotations. Experiments on the MSR-VTT and ActivityNet Captions datasets show that our approach outperforms zero-shot video captioning baselines, demonstrating that aggregating frame-level scene graphs yields rich video understanding without requiring large-scale paired data or high inference cost.