 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
Diffusion-Based Conditional Image Editing through Optimized Inference with Guidance
Dec 20, 2024We present a simple but effective training-free approach for text-driven image-to-image translation based on a pretrained text-to-image diffusion model. Our goal is to generate an image that aligns with the target task while preserving the structure and background of a source image. To this end, we derive the representation guidance with a combination of two objectives: maximizing the similarity to the target prompt based on the CLIP score and minimizing the structural distance to the source latent variable. This guidance improves the fidelity of the generated target image to the given target prompt while maintaining the structure integrity of the source image. To incorporate the representation guidance component, we optimize the target latent variable of diffusion model's reverse process with the guidance. Experimental results demonstrate that our method achieves outstanding image-to-image translation performance on various tasks when combined with the pretrained Stable Diffusion model.
Diffusion-Based Image-to-Image Translation by Noise Correction via Prompt Interpolation
Sep 12, 2024We propose a simple but effective training-free approach tailored to diffusion-based image-to-image translation. Our approach revises the original noise prediction network of a pretrained diffusion model by introducing a noise correction term. We formulate the noise correction term as the difference between two noise predictions; one is computed from the denoising network with a progressive interpolation of the source and target prompt embeddings, while the other is the noise prediction with the source prompt embedding. The final noise prediction network is given by a linear combination of the standard denoising term and the noise correction term, where the former is designed to reconstruct must-be-preserved regions while the latter aims to effectively edit regions of interest relevant to the target prompt. Our approach can be easily incorporated into existing image-to-image translation methods based on diffusion models. Extensive experiments verify that the proposed technique achieves outstanding performance with low latency and consistently improves existing frameworks when combined with them.
What is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Catch-Up Mix: Catch-Up Class for Struggling Filters in CNN
Jan 24, 2024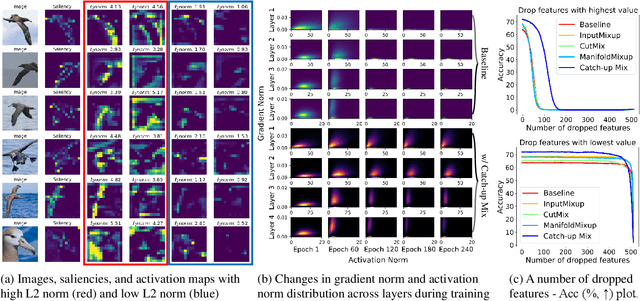
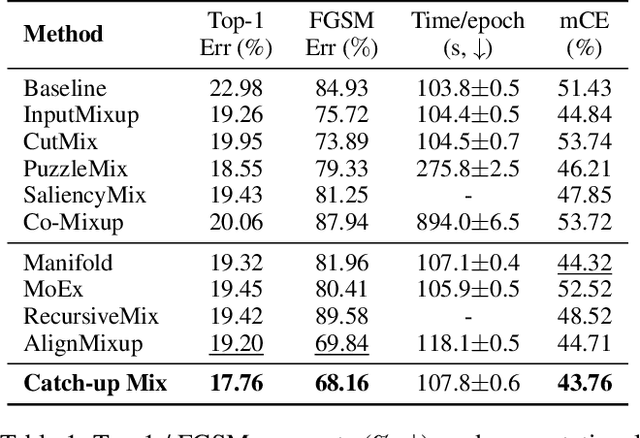
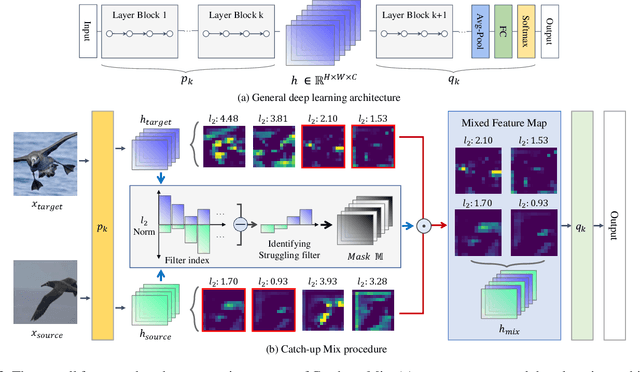
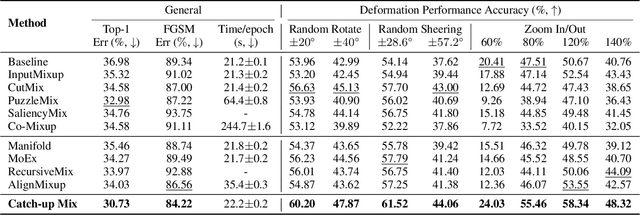
Deep learning has made significant advances in computer vision, particularly in image classification tasks. Despite their high accuracy on training data, deep learning models often face challenges related to complexity and overfitting. One notable concern is that the model often relies heavily on a limited subset of filters for making predictions. This dependency can result in compromised generalization and an increased vulnerability to minor variations. While regularization techniques like weight decay, dropout, and data augmentation are commonly used to address this issue, they may not directly tackle the reliance on specific filters. Our observations reveal that the heavy reliance problem gets severe when slow-learning filters are deprived of learning opportunities due to fast-learning filters. Drawing inspiration from image augmentation research that combats over-reliance on specific image regions by removing and replacing parts of images, our idea is to mitigate the problem of over-reliance on strong filters by substituting highly activated features. To this end, we present a novel method called Catch-up Mix, which provides learning opportunities to a wide range of filters during training, focusing on filters that may lag behind. By mixing activation maps with relatively lower norms, Catch-up Mix promotes the development of more diverse representations and reduces reliance on a small subset of filters. Experimental results demonstrate the superiority of our method in various vision classification datasets, providing enhanced robustness.
GuidedMixup: An Efficient Mixup Strategy Guided by Saliency Maps
Jun 29, 2023



Data augmentation is now an essential part of the image training process, as it effectively prevents overfitting and makes the model more robust against noisy datasets. Recent mixing augmentation strategies have advanced to generate the mixup mask that can enrich the saliency information, which is a supervisory signal. However, these methods incur a significant computational burden to optimize the mixup mask. From this motivation, we propose a novel saliency-aware mixup method, GuidedMixup, which aims to retain the salient regions in mixup images with low computational overhead. We develop an efficient pairing algorithm that pursues to minimize the conflict of salient regions of paired images and achieve rich saliency in mixup images. Moreover, GuidedMixup controls the mixup ratio for each pixel to better preserve the salient region by interpolating two paired images smoothly. The experiments on several datasets demonstrate that GuidedMixup provides a good trade-off between augmentation overhead and generalization performance on classification datasets. In addition, our method shows good performance in experiments with corrupted or reduced datasets.
* Published at AAAI2023 (Oral)
Conditional Score Guidance for Text-Driven Image-to-Image Translation
May 29, 2023
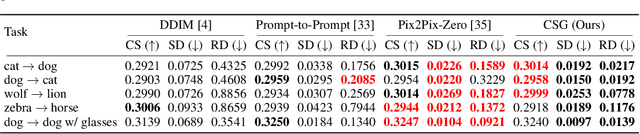
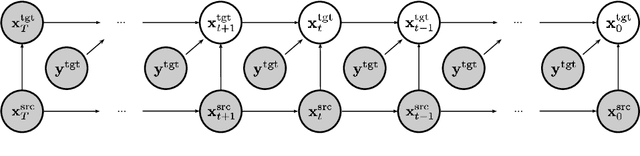
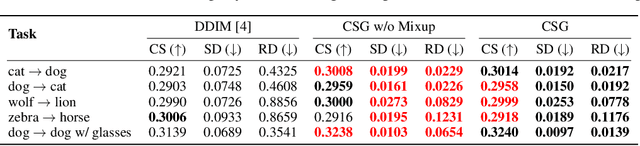
We present a novel algorithm for text-driven image-to-image translation based on a pretrained text-to-image diffusion model. Our method aims to generate a target image by selectively editing the regions of interest in a source image, defined by a modifying text, while preserving the remaining parts. In contrast to existing techniques that solely rely on a target prompt, we introduce a new score function, which considers both a source prompt and a source image, tailored to address specific translation tasks. To this end, we derive the conditional score function in a principled manner, decomposing it into a standard score and a guiding term for target image generation. For the gradient computation, we adopt a Gaussian distribution of the posterior distribution, estimating its mean and variance without requiring additional training. In addition, to enhance the conditional score guidance, we incorporate a simple yet effective mixup method. This method combines two cross-attention maps derived from the source and target latents, promoting the generation of the target image by a desirable fusion of the original parts in the source image and the edited regions aligned with the target prompt. Through comprehensive experiments, we demonstrate that our approach achieves outstanding image-to-image translation performance on various tasks.
Information-Theoretic GAN Compression with Variational Energy-based Model
Mar 28, 2023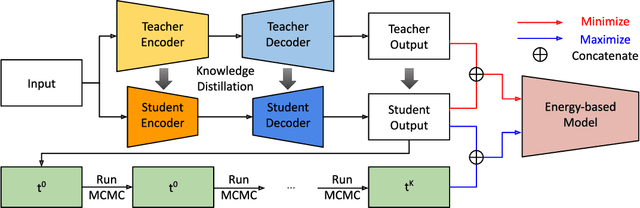
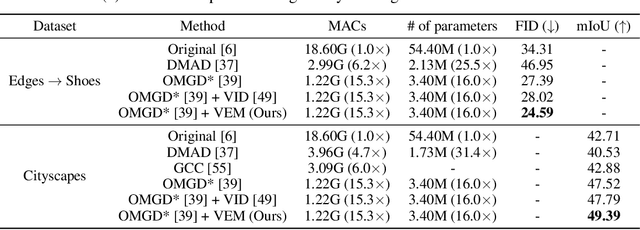

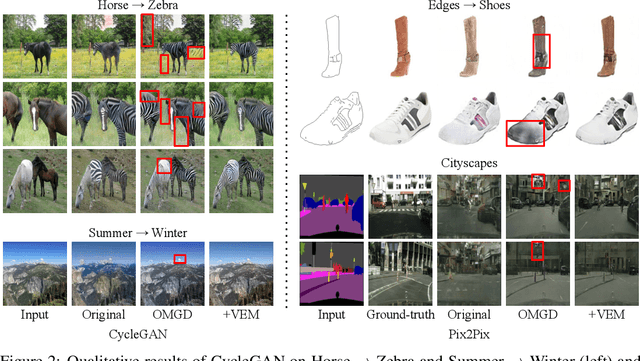
We propose an information-theoretic knowledge distillation approach for the compression of generative adversarial networks, which aims to maximize the mutual information between teacher and student networks via a variational optimization based on an energy-based model. Because the direct computation of the mutual information in continuous domains is intractable, our approach alternatively optimizes the student network by maximizing the variational lower bound of the mutual information. To achieve a tight lower bound, we introduce an energy-based model relying on a deep neural network to represent a flexible variational distribution that deals with high-dimensional images and consider spatial dependencies between pixels, effectively. Since the proposed method is a generic optimization algorithm, it can be conveniently incorporated into arbitrary generative adversarial networks and even dense prediction networks, e.g., image enhancement models. We demonstrate that the proposed algorithm achieves outstanding performance in model compression of generative adversarial networks consistently when combined with several existing models.
Variational Distribution Learning for Unsupervised Text-to-Image Generation
Mar 28, 2023



We propose a text-to-image generation algorithm based on deep neural networks when text captions for images are unavailable during training. In this work, instead of simply generating pseudo-ground-truth sentences of training images using existing image captioning methods, we employ a pretrained CLIP model, which is capable of properly aligning embeddings of images and corresponding texts in a joint space and, consequently, works well on zero-shot recognition tasks. We optimize a text-to-image generation model by maximizing the data log-likelihood conditioned on pairs of image-text CLIP embeddings. To better align data in the two domains, we employ a principled way based on a variational inference, which efficiently estimates an approximate posterior of the hidden text embedding given an image and its CLIP feature. Experimental results validate that the proposed framework outperforms existing approaches by large margins under unsupervised and semi-supervised text-to-image generation settings.
Class-Incremental Learning by Knowledge Distillation with Adaptive Feature Consolidation
Apr 02, 2022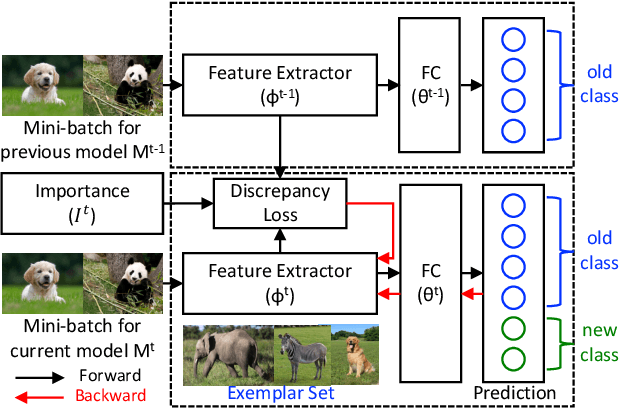
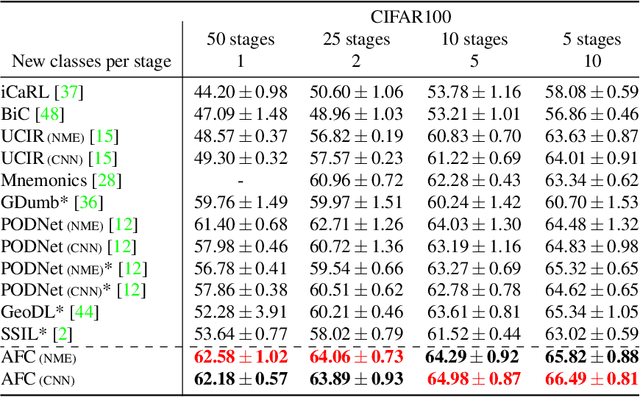
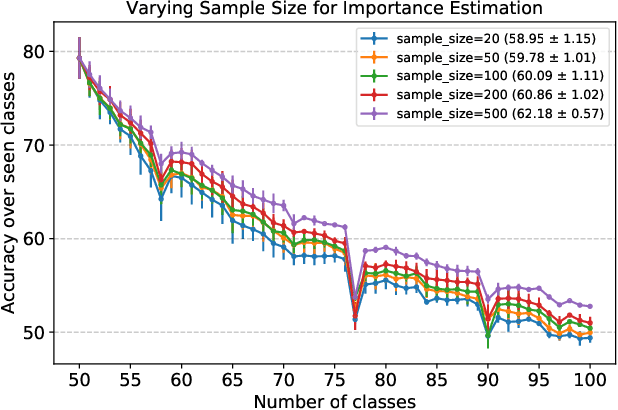
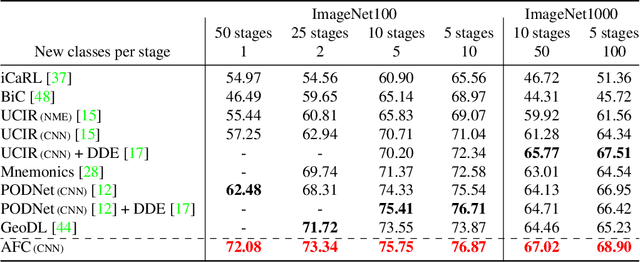
We present a novel class incremental learning approach based on deep neural networks, which continually learns new tasks with limited memory for storing examples in the previous tasks. Our algorithm is based on knowledge distillation and provides a principled way to maintain the representations of old models while adjusting to new tasks effectively. The proposed method estimates the relationship between the representation changes and the resulting loss increases incurred by model updates. It minimizes the upper bound of the loss increases using the representations, which exploits the estimated importance of each feature map within a backbone model. Based on the importance, the model restricts updates of important features for robustness while allowing changes in less critical features for flexibility. This optimization strategy effectively alleviates the notorious catastrophic forgetting problem despite the limited accessibility of data in the previous tasks. The experimental results show significant accuracy improvement of the proposed algorithm over the existing methods on the standard datasets. Code is available.