 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Score Guidance for Text-Driven Image-to-Image Translation
Paper and Code

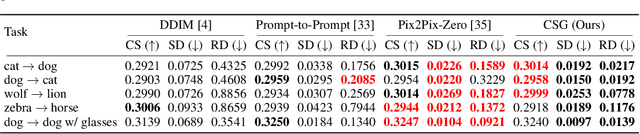
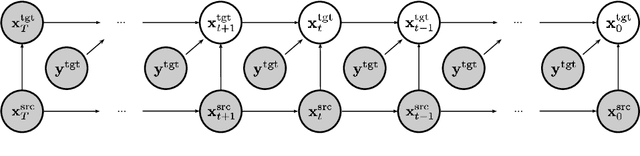
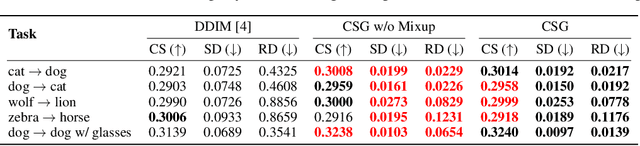
We present a novel algorithm for text-driven image-to-image translation based on a pretrained text-to-image diffusion model. Our method aims to generate a target image by selectively editing the regions of interest in a source image, defined by a modifying text, while preserving the remaining parts. In contrast to existing techniques that solely rely on a target prompt, we introduce a new score function, which considers both a source prompt and a source image, tailored to address specific translation tasks. To this end, we derive the conditional score function in a principled manner, decomposing it into a standard score and a guiding term for target image generation. For the gradient computation, we adopt a Gaussian distribution of the posterior distribution, estimating its mean and variance without requiring additional training. In addition, to enhance the conditional score guidance, we incorporate a simple yet effective mixup method. This method combines two cross-attention maps derived from the source and target latents, promoting the generation of the target image by a desirable fusion of the original parts in the source image and the edited regions aligned with the target prompt. Through comprehensive experiments, we demonstrate that our approach achieves outstanding image-to-image translation performance on various tasks.