 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-Guided Geometric Stylization of 3D Meshes
Apr 09, 2026Recent generative models can create visually plausible 3D representations of objects. However, the generation process often allows for implicit control signals, such as contextual descriptions, and rarely supports bold geometric distortions beyond existing data distributions. We propose a geometric stylization framework that deforms a 3D mesh, allowing it to express the style of an image. While style is inherently ambiguous, we utilize pre-trained diffusion models to extract an abstract representation of the provided image. Our coarse-to-fine stylization pipeline can drastically deform the input 3D model to express a diverse range of geometric variations while retaining the valid topology of the original mesh and part-level semantics. We also propose an approximate VAE encoder that provides efficient and reliable gradients from mesh renderings. Extensive experiments demonstrate that our method can create stylized 3D meshes that reflect unique geometric features of the pictured assets, such as expressive poses and silhouettes, thereby supporting the creation of distinctive artistic 3D creations. Project page: https://changwoonchoi.github.io/GeoStyle
Calibrated Test-Time Guidance for Bayesian Inference
Feb 25, 2026Test-time guidance is a widely used mechanism for steering pretrained diffusion models toward outcomes specified by a reward function. Existing approaches, however, focus on maximizing reward rather than sampling from the true Bayesian posterior, leading to miscalibrated inference. In this work, we show that common test-time guidance methods do not recover the correct posterior distribution and identify the structural approximations responsible for this failure. We then propose consistent alternative estimators that enable calibrated sampling from the Bayesian posterior. We significantly outperform previous methods on a set of Bayesian inference tasks, and match state-of-the-art in black hole image reconstruction.
Point2Pose: A Generative Framework for 3D Human Pose Estimation with Multi-View Point Cloud Dataset
Dec 11, 2025We propose a novel generative approach for 3D human pose estimation. 3D human pose estimation poses several key challenges due to the complex geometry of the human body, self-occluding joints, and the requirement for large-scale real-world motion datasets. To address these challenges, we introduce Point2Pose, a framework that effectively models the distribution of human poses conditioned on sequential point cloud and pose history. Specifically, we employ a spatio-temporal point cloud encoder and a pose feature encoder to extract joint-wise features, followed by an attention-based generative regressor. Additionally, we present a large-scale indoor dataset MVPose3D, which contains multiple modalities, including IMU data of non-trivial human motions, dense multi-view point clouds, and RGB images. Experimental results show that the proposed method outperforms the baseline models, demonstrating its superior performance across various datasets.
SyncSDE: A Probabilistic Framework for Diffusion Synchronization
Mar 27, 2025There have been many attempts to leverage multiple diffusion models for collaborative generation, extending beyond the original domain. A prominent approach involves synchronizing multiple diffusion trajectories by mixing the estimated scores to artificially correlate the generation processes. However, existing methods rely on naive heuristics, such as averaging, without considering task specificity. These approaches do not clarify why such methods work and often fail when a heuristic suitable for one task is blindly applied to others. In this paper, we present a probabilistic framework for analyzing why diffusion synchronization works and reveal where heuristics should be focused - modeling correlations between multiple trajectories and adapting them to each specific task. We further identify optimal correlation models per task, achieving better results than previous approaches that apply a single heuristic across all tasks without justification.
Diffusion-Based Conditional Image Editing through Optimized Inference with Guidance
Dec 20, 2024We present a simple but effective training-free approach for text-driven image-to-image translation based on a pretrained text-to-image diffusion model. Our goal is to generate an image that aligns with the target task while preserving the structure and background of a source image. To this end, we derive the representation guidance with a combination of two objectives: maximizing the similarity to the target prompt based on the CLIP score and minimizing the structural distance to the source latent variable. This guidance improves the fidelity of the generated target image to the given target prompt while maintaining the structure integrity of the source image. To incorporate the representation guidance component, we optimize the target latent variable of diffusion model's reverse process with the guidance. Experimental results demonstrate that our method achieves outstanding image-to-image translation performance on various tasks when combined with the pretrained Stable Diffusion model.
Conditional Score Guidance for Text-Driven Image-to-Image Translation
May 29, 2023
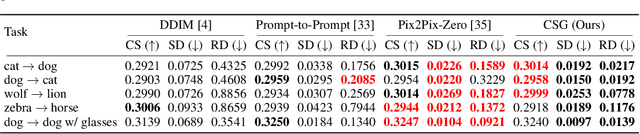
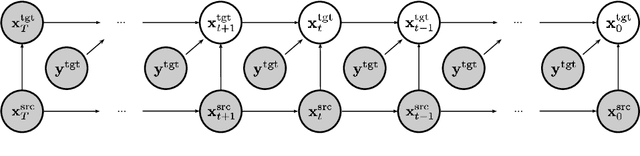
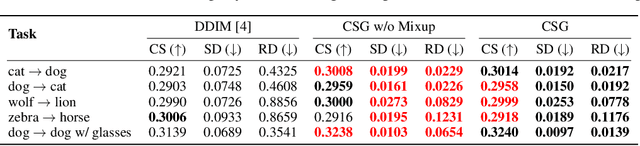
We present a novel algorithm for text-driven image-to-image translation based on a pretrained text-to-image diffusion model. Our method aims to generate a target image by selectively editing the regions of interest in a source image, defined by a modifying text, while preserving the remaining parts. In contrast to existing techniques that solely rely on a target prompt, we introduce a new score function, which considers both a source prompt and a source image, tailored to address specific translation tasks. To this end, we derive the conditional score function in a principled manner, decomposing it into a standard score and a guiding term for target image generation. For the gradient computation, we adopt a Gaussian distribution of the posterior distribution, estimating its mean and variance without requiring additional training. In addition, to enhance the conditional score guidance, we incorporate a simple yet effective mixup method. This method combines two cross-attention maps derived from the source and target latents, promoting the generation of the target image by a desirable fusion of the original parts in the source image and the edited regions aligned with the target prompt. Through comprehensive experiments, we demonstrate that our approach achieves outstanding image-to-image translation performance on various tasks.
Situation-Aware Deep Reinforcement Learning for Autonomous Nonlinear Mobility Control in Cyber-Physical Loitering Munition Systems
Dec 31, 2022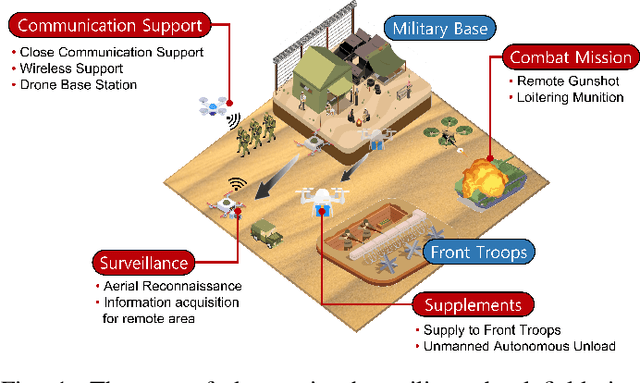
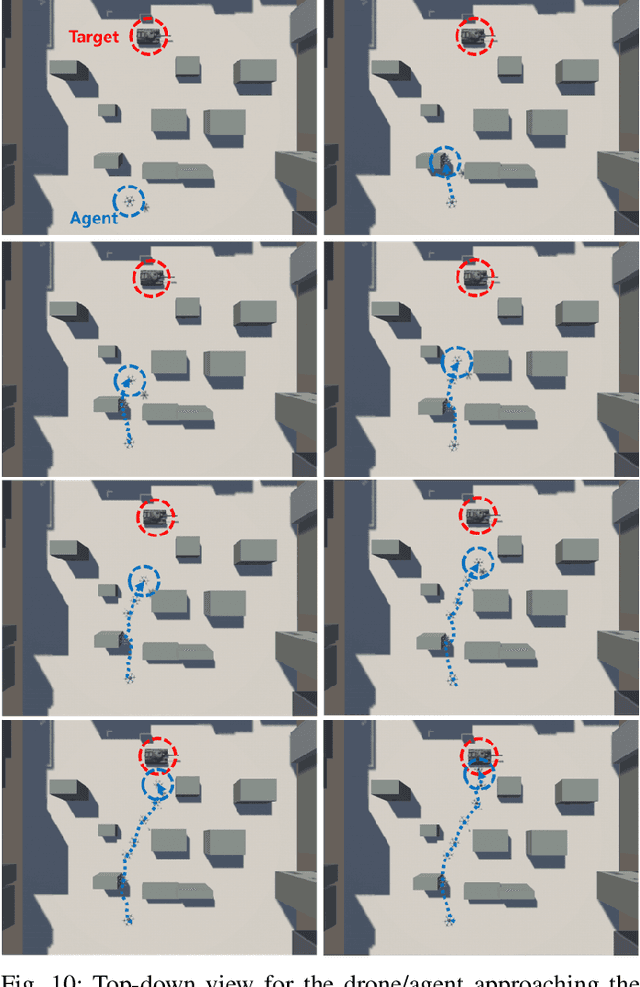

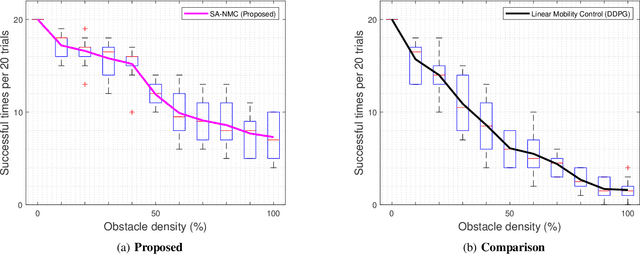
According to the rapid development of drone technologies, drones are widely used in many applications including military domains. In this paper, a novel situation-aware DRL- based autonomous nonlinear drone mobility control algorithm in cyber-physical loitering munition applications. On the battlefield, the design of DRL-based autonomous control algorithm is not straightforward because real-world data gathering is generally not available. Therefore, the approach in this paper is that cyber-physical virtual environment is constructed with Unity environment. Based on the virtual cyber-physical battlefield scenarios, a DRL-based automated nonlinear drone mobility control algorithm can be designed, evaluated, and visualized. Moreover, many obstacles exist which is harmful for linear trajectory control in real-world battlefield scenarios. Thus, our proposed autonomous nonlinear drone mobility control algorithm utilizes situation-aware components those are implemented with a Raycast function in Unity virtual scenarios. Based on the gathered situation-aware information, the drone can autonomously and nonlinearly adjust its trajectory during flight. Therefore, this approach is obviously beneficial for avoiding obstacles in obstacle-deployed battlefields. Our visualization-based performance evaluation shows that the proposed algorithm is superior from the other linear mobility control algorithms.