 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination-Aware Generative Pretrained Transformer for Cooperative Aerial Mobility Control
Apr 15, 2025This paper proposes SafeGPT, a two-tiered framework that integrates generative pretrained transformers (GPTs) with reinforcement learning (RL) for efficient and reliable unmanned aerial vehicle (UAV) last-mile deliveries. In the proposed design, a Global GPT module assigns high-level tasks such as sector allocation, while an On-Device GPT manages real-time local route planning. An RL-based safety filter monitors each GPT decision and overrides unsafe actions that could lead to battery depletion or duplicate visits, effectively mitigating hallucinations. Furthermore, a dual replay buffer mechanism helps both the GPT modules and the RL agent refine their strategies over time. Simulation results demonstrate that SafeGPT achieves higher delivery success rates compared to a GPT-only baseline, while substantially reducing battery consumption and travel distance. These findings validate the efficacy of combining GPT-based semantic reasoning with formal safety guarantees, contributing a viable solution for robust and energy-efficient UAV logistics.
Handover Protocol Learning for LEO Satellite Networks: Access Delay and Collision Minimization
Oct 31, 2023



This study presents a novel deep reinforcement learning (DRL)-based handover (HO) protocol, called DHO, specifically designed to address the persistent challenge of long propagation delays in low-Earth orbit (LEO) satellite networks' HO procedures. DHO skips the Measurement Report (MR) in the HO procedure by leveraging its predictive capabilities after being trained with a pre-determined LEO satellite orbital pattern. This simplification eliminates the propagation delay incurred during the MR phase, while still providing effective HO decisions. The proposed DHO outperforms the legacy HO protocol across diverse network conditions in terms of access delay, collision rate, and handover success rate, demonstrating the practical applicability of DHO in real-world networks. Furthermore, the study examines the trade-off between access delay and collision rate and also evaluates the training performance and convergence of DHO using various DRL algorithms.
Realizing Stabilized Landing for Computation-Limited Reusable Rockets: A Quantum Reinforcement Learning Approach
Oct 10, 2023



The advent of reusable rockets has heralded a new era in space exploration, reducing the costs of launching satellites by a significant factor. Traditional rockets were disposable, but the design of reusable rockets for repeated use has revolutionized the financial dynamics of space missions. The most critical phase of reusable rockets is the landing stage, which involves managing the tremendous speed and attitude for safe recovery. The complexity of this task presents new challenges for control systems, specifically in terms of precision and adaptability. Classical control systems like the proportional-integral-derivative (PID) controller lack the flexibility to adapt to dynamic system changes, making them costly and time-consuming to redesign of controller. This paper explores the integration of quantum reinforcement learning into the control systems of reusable rockets as a promising alternative. Unlike classical reinforcement learning, quantum reinforcement learning uses quantum bits that can exist in superposition, allowing for more efficient information encoding and reducing the number of parameters required. This leads to increased computational efficiency, reduced memory requirements, and more stable and predictable performance. Due to the nature of reusable rockets, which must be light, heavy computers cannot fit into them. In the reusable rocket scenario, quantum reinforcement learning, which has reduced memory requirements due to fewer parameters, is a good solution.
Quantum Multi-Agent Reinforcement Learning for Autonomous Mobility Cooperation
Aug 03, 2023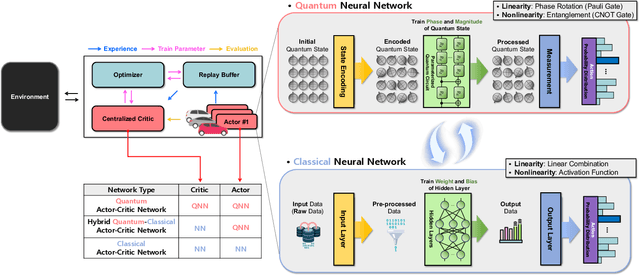
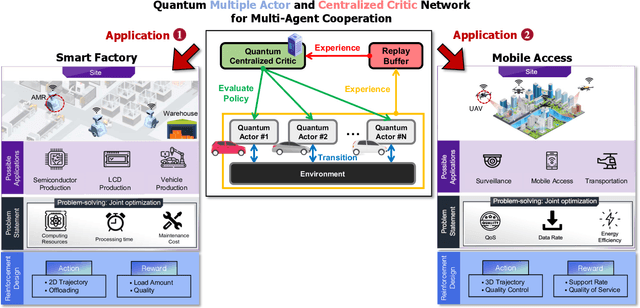
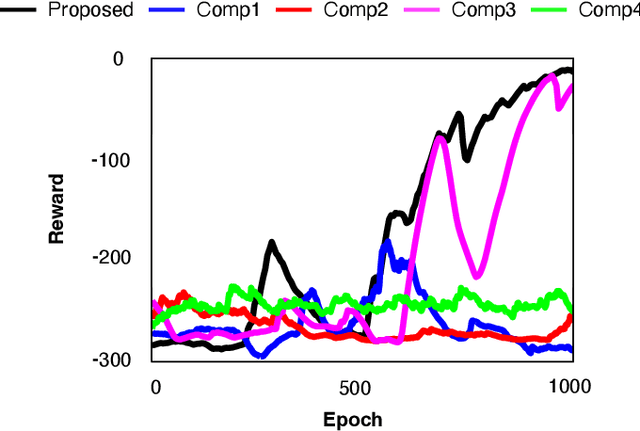

For Industry 4.0 Revolution, cooperative autonomous mobility systems are widely used based on multi-agent reinforcement learning (MARL). However, the MARL-based algorithms suffer from huge parameter utilization and convergence difficulties with many agents. To tackle these problems, a quantum MARL (QMARL) algorithm based on the concept of actor-critic network is proposed, which is beneficial in terms of scalability, to deal with the limitations in the noisy intermediate-scale quantum (NISQ) era. Additionally, our QMARL is also beneficial in terms of efficient parameter utilization and fast convergence due to quantum supremacy. Note that the reward in our QMARL is defined as task precision over computation time in multiple agents, thus, multi-agent cooperation can be realized. For further improvement, an additional technique for scalability is proposed, which is called projection value measure (PVM). Based on PVM, our proposed QMARL can achieve the highest reward, by reducing the action dimension into a logarithmic-scale. Finally, we can conclude that our proposed QMARL with PVM outperforms the other algorithms in terms of efficient parameter utilization, fast convergence, and scalability.
Two Tales of Platoon Intelligence for Autonomous Mobility Control: Enabling Deep Learning Recipes
Jul 19, 2023This paper presents the deep learning-based recent achievements to resolve the problem of autonomous mobility control and efficient resource management of autonomous vehicles and UAVs, i.e., (i) multi-agent reinforcement learning (MARL), and (ii) neural Myerson auction. Representatively, communication network (CommNet), which is one of the most popular MARL algorithms, is introduced to enable multiple agents to take actions in a distributed manner for their shared goals by training all agents' states and actions in a single neural network. Moreover, the neural Myerson auction guarantees trustfulness among multiple agents as well as achieves the optimal revenue of highly dynamic systems. Therefore, we survey the recent studies on autonomous mobility control based on MARL and neural Myerson auction. Furthermore, we emphasize that integration of MARL and neural Myerson auction is expected to be critical for efficient and trustful autonomous mobility services.
Entropy-Aware Similarity for Balanced Clustering: A Case Study with Melanoma Detection
May 11, 2023Clustering data is an unsupervised learning approach that aims to divide a set of data points into multiple groups. It is a crucial yet demanding subject in machine learning and data mining. Its successful applications span various fields. However, conventional clustering techniques necessitate the consideration of balance significance in specific applications. Therefore, this paper addresses the challenge of imbalanced clustering problems and presents a new method for balanced clustering by utilizing entropy-aware similarity, which can be defined as the degree of balances. We have coined the term, entropy-aware similarity for balanced clustering (EASB), which maximizes balance during clustering by complementary clustering of unbalanced data and incorporating entropy in a novel similarity formula that accounts for both angular differences and distances. The effectiveness of the proposed approach is evaluated on actual melanoma medial data, specifically the International Skin Imaging Collaboration (ISIC) 2019 and 2020 challenge datasets, to demonstrate how it can successfully cluster the data while preserving balance. Lastly, we can confirm that the proposed method exhibited outstanding performance in detecting melanoma, comparing to classical methods.
Quantum Multi-Agent Actor-Critic Networks for Cooperative Mobile Access in Multi-UAV Systems
Feb 09, 2023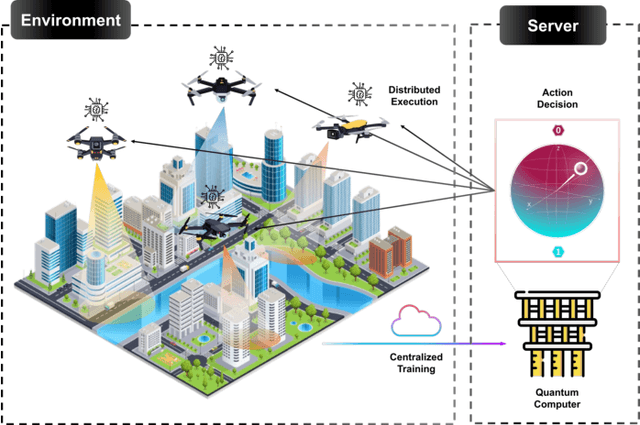
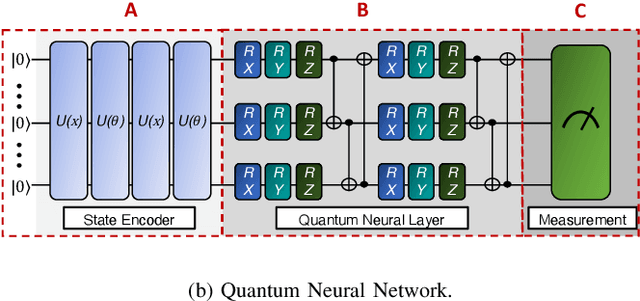
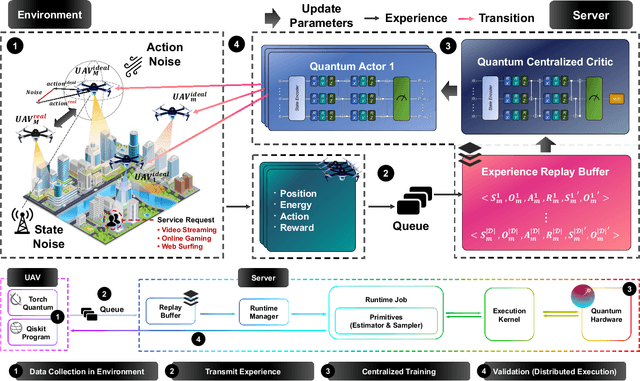
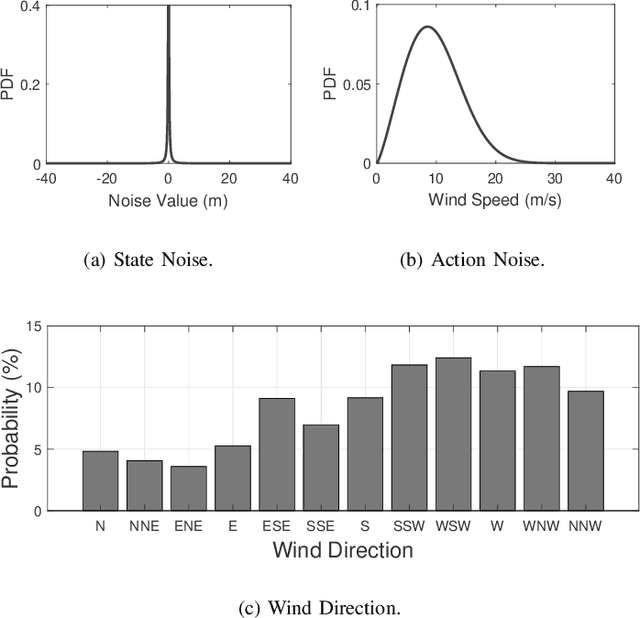
This paper proposes a novel quantum multi-agent actor-critic networks (QMACN) algorithm for autonomously constructing a robust mobile access system using multiple unmanned aerial vehicles (UAVs). For the cooperation of multiple UAVs for autonomous mobile access, multi-agent reinforcement learning (MARL) methods are considered. In addition, we also adopt the concept of quantum computing (QC) to improve the training and inference performances. By utilizing QC, scalability and physical issues can happen. However, our proposed QMACN algorithm builds quantum critic and multiple actor networks in order to handle such problems. Thus, our proposed QMACN algorithm verifies the advantage of quantum MARL with remarkable performance improvements in terms of training speed and wireless service quality in various data-intensive evaluations. Furthermore, we validate that a noise injection scheme can be used for handling environmental uncertainties in order to realize robust mobile access. Our data-intensive simulation results verify that our proposed QMACN algorithm outperforms the other existing algorithms.
Situation-Aware Deep Reinforcement Learning for Autonomous Nonlinear Mobility Control in Cyber-Physical Loitering Munition Systems
Dec 31, 2022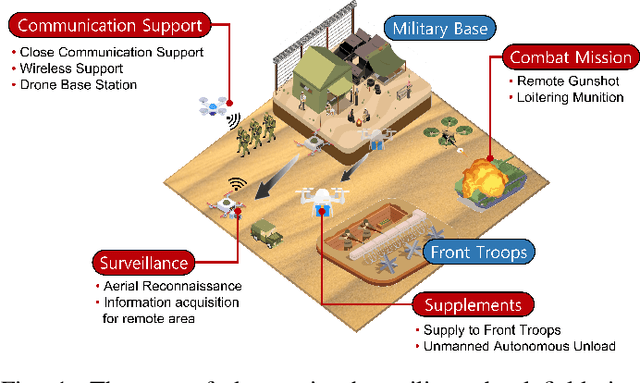
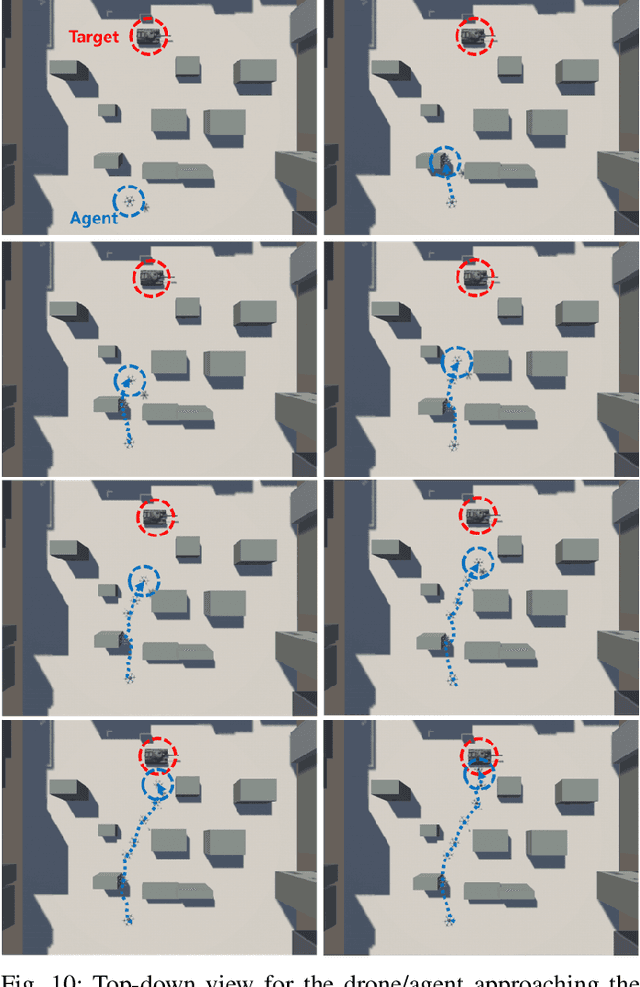

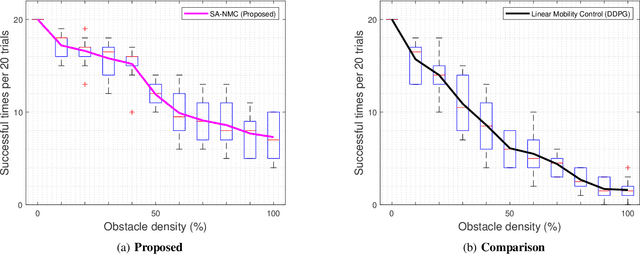
According to the rapid development of drone technologies, drones are widely used in many applications including military domains. In this paper, a novel situation-aware DRL- based autonomous nonlinear drone mobility control algorithm in cyber-physical loitering munition applications. On the battlefield, the design of DRL-based autonomous control algorithm is not straightforward because real-world data gathering is generally not available. Therefore, the approach in this paper is that cyber-physical virtual environment is constructed with Unity environment. Based on the virtual cyber-physical battlefield scenarios, a DRL-based automated nonlinear drone mobility control algorithm can be designed, evaluated, and visualized. Moreover, many obstacles exist which is harmful for linear trajectory control in real-world battlefield scenarios. Thus, our proposed autonomous nonlinear drone mobility control algorithm utilizes situation-aware components those are implemented with a Raycast function in Unity virtual scenarios. Based on the gathered situation-aware information, the drone can autonomously and nonlinearly adjust its trajectory during flight. Therefore, this approach is obviously beneficial for avoiding obstacles in obstacle-deployed battlefields. Our visualization-based performance evaluation shows that the proposed algorithm is superior from the other linear mobility control algorithms.
Multi-Agent Deep Reinforcement Learning for Efficient Passenger Delivery in Urban Air Mobility
Nov 13, 2022It has been considered that urban air mobility (UAM), also known as drone-taxi or electrical vertical takeoff and landing (eVTOL), will play a key role in future transportation. By putting UAM into practical future transportation, several benefits can be realized, i.e., (i) the total travel time of passengers can be reduced compared to traditional transportation and (ii) there is no environmental pollution and no special labor costs to operate the system because electric batteries will be used in UAM system. However, there are various dynamic and uncertain factors in the flight environment, i.e., passenger sudden service requests, battery discharge, and collision among UAMs. Therefore, this paper proposes a novel cooperative MADRL algorithm based on centralized training and distributed execution (CTDE) concepts for reliable and efficient passenger delivery in UAM networks. According to the performance evaluation results, we confirm that the proposed algorithm outperforms other existing algorithms in terms of the number of serviced passengers increase (30%) and the waiting time per serviced passenger decrease (26%)
Self-Configurable Stabilized Real-Time Detection Learning for Autonomous Driving Applications
Sep 29, 2022

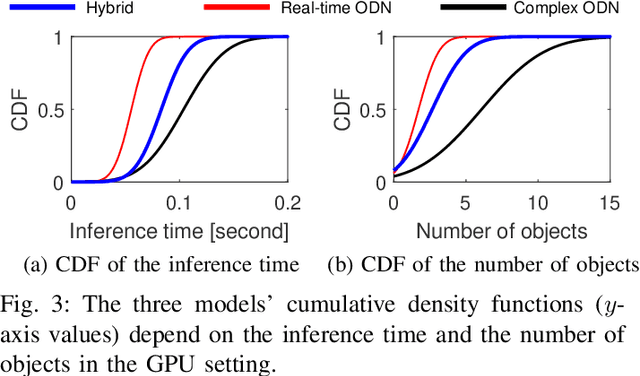

Guaranteeing real-time and accurate object detection simultaneously is paramount in autonomous driving environments. However, the existing object detection neural network systems are characterized by a tradeoff between computation time and accuracy, making it essential to optimize such a tradeoff. Fortunately, in many autonomous driving environments, images come in a continuous form, providing an opportunity to use optical flow. In this paper, we improve the performance of an object detection neural network utilizing optical flow estimation. In addition, we propose a Lyapunov optimization framework for time-average performance maximization subject to stability. It adaptively determines whether to use optical flow to suit the dynamic vehicle environment, thereby ensuring the vehicle's queue stability and the time-average maximum performance simultaneously. To verify the key ideas, we conduct numerical experiments with various object detection neural networks and optical flow estimation networks. In addition, we demonstrate the self-configurable stabilized detection with YOLOv3-tiny and FlowNet2-S, which are the real-time object detection network and an optical flow estimation network, respectively. In the demonstration, our proposed framework improves the accuracy by 3.02%, the number of detected objects by 59.6%, and the queue stability for computing capabilities.