 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evaluation of Concept Drift in ML-Based Android Malware Detection
Jul 30, 2025



Despite outstanding results, machine learning-based Android malware detection models struggle with concept drift, where rapidly evolving malware characteristics degrade model effectiveness. This study examines the impact of concept drift on Android malware detection, evaluating two datasets and nine machine learning and deep learning algorithms, as well as Large Language Models (LLMs). Various feature types--static, dynamic, hybrid, semantic, and image-based--were considered. The results showed that concept drift is widespread and significantly affects model performance. Factors influencing the drift include feature types, data environments, and detection methods. Balancing algorithms helped with class imbalance but did not fully address concept drift, which primarily stems from the dynamic nature of the malware landscape. No strong link was found between the type of algorithm used and concept drift, the impact was relatively minor compared to other variables since hyperparameters were not fine-tuned, and the default algorithm configurations were used. While LLMs using few-shot learning demonstrated promising detection performance, they did not fully mitigate concept drift, highlighting the need for further investigation.
Understanding Concept Drift with Deprecated Permissions in Android Malware Detection
Jul 29, 2025Permission analysis is a widely used method for Android malware detection. It involves examining the permissions requested by an application to access sensitive data or perform potentially malicious actions. In recent years, various machine learning (ML) algorithms have been applied to Android malware detection using permission-based features and feature selection techniques, often achieving high accuracy. However, these studies have largely overlooked important factors such as protection levels and the deprecation or restriction of permissions due to updates in the Android OS -- factors that can contribute to concept drift. In this study, we investigate the impact of deprecated and restricted permissions on the performance of machine learning models. A large dataset containing 166 permissions was used, encompassing more than 70,000 malware and benign applications. Various machine learning and deep learning algorithms were employed as classifiers, along with different concept drift detection strategies. The results suggest that Android permissions are highly effective features for malware detection, with the exclusion of deprecated and restricted permissions having only a marginal impact on model performance. In some cases, such as with CNN, accuracy improved. Excluding these permissions also enhanced the detection of concept drift using a year-to-year analysis strategy. Dataset balancing further improved model performance, reduced low-accuracy instances, and enhanced concept drift detection via the Kolmogorov-Smirnov test.
Enhancing Vulnerability Reports with Automated and Augmented Description Summarization
Apr 29, 2025Public vulnerability databases, such as the National Vulnerability Database (NVD), document vulnerabilities and facilitate threat information sharing. However, they often suffer from short descriptions and outdated or insufficient information. In this paper, we introduce Zad, a system designed to enrich NVD vulnerability descriptions by leveraging external resources. Zad consists of two pipelines: one collects and filters supplementary data using two encoders to build a detailed dataset, while the other fine-tunes a pre-trained model on this dataset to generate enriched descriptions. By addressing brevity and improving content quality, Zad produces more comprehensive and cohesive vulnerability descriptions. We evaluate Zad using standard summarization metrics and human assessments, demonstrating its effectiveness in enhancing vulnerability information.
Fishing for Phishers: Learning-Based Phishing Detection in Ethereum Transactions
Apr 24, 2025

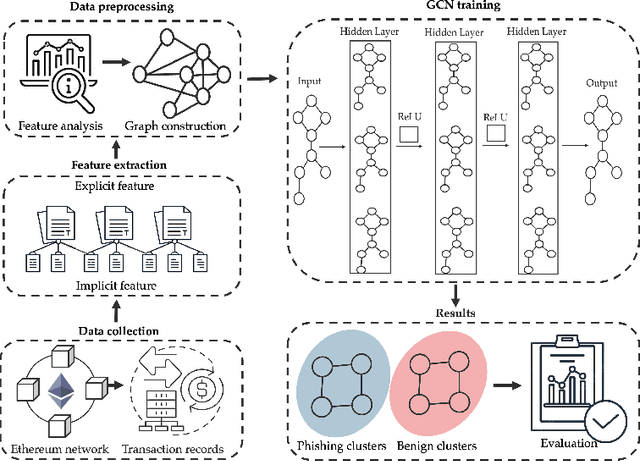

Phishing detection on Ethereum has increasingly leveraged advanced machine learning techniques to identify fraudulent transactions. However, limited attention has been given to understanding the effectiveness of feature selection strategies and the role of graph-based models in enhancing detection accuracy. In this paper, we systematically examine these issues by analyzing and contrasting explicit transactional features and implicit graph-based features, both experimentally and analytically. We explore how different feature sets impact the performance of phishing detection models, particularly in the context of Ethereum's transactional network. Additionally, we address key challenges such as class imbalance and dataset composition and their influence on the robustness and precision of detection methods. Our findings demonstrate the advantages and limitations of each feature type, while also providing a clearer understanding of how feature affect model resilience and generalization in adversarial environments.
Uncertainty-Guided Coarse-to-Fine Tumor Segmentation with Anatomy-Aware Post-Processing
Apr 16, 2025Reliable tumor segmentation in thoracic computed tomography (CT) remains challenging due to boundary ambiguity, class imbalance, and anatomical variability. We propose an uncertainty-guided, coarse-to-fine segmentation framework that combines full-volume tumor localization with refined region-of-interest (ROI) segmentation, enhanced by anatomically aware post-processing. The first-stage model generates a coarse prediction, followed by anatomically informed filtering based on lung overlap, proximity to lung surfaces, and component size. The resulting ROIs are segmented by a second-stage model trained with uncertainty-aware loss functions to improve accuracy and boundary calibration in ambiguous regions. Experiments on private and public datasets demonstrate improvements in Dice and Hausdorff scores, with fewer false positives and enhanced spatial interpretability. These results highlight the value of combining uncertainty modeling and anatomical priors in cascaded segmentation pipelines for robust and clinically meaningful tumor delineation. On the Orlando dataset, our framework improved Swin UNETR Dice from 0.4690 to 0.6447. Reduction in spurious components was strongly correlated with segmentation gains, underscoring the value of anatomically informed post-processing.
Security and Quality in LLM-Generated Code: A Multi-Language, Multi-Model Analysis
Feb 03, 2025



Artificial Intelligence (AI)-driven code generation tools are increasingly used throughout the software development lifecycle to accelerate coding tasks. However, the security of AI-generated code using Large Language Models (LLMs) remains underexplored, with studies revealing various risks and weaknesses. This paper analyzes the security of code generated by LLMs across different programming languages. We introduce a dataset of 200 tasks grouped into six categories to evaluate the performance of LLMs in generating secure and maintainable code. Our research shows that while LLMs can automate code creation, their security effectiveness varies by language. Many models fail to utilize modern security features in recent compiler and toolkit updates, such as Java 17. Moreover, outdated methods are still commonly used, particularly in C++. This highlights the need for advancing LLMs to enhance security and quality while incorporating emerging best practices in programming languages.
Through the Looking Glass: LLM-Based Analysis of AR/VR Android Applications Privacy Policies
Jan 31, 2025\begin{abstract} This paper comprehensively analyzes privacy policies in AR/VR applications, leveraging BERT, a state-of-the-art text classification model, to evaluate the clarity and thoroughness of these policies. By comparing the privacy policies of AR/VR applications with those of free and premium websites, this study provides a broad perspective on the current state of privacy practices within the AR/VR industry. Our findings indicate that AR/VR applications generally offer a higher percentage of positive segments than free content but lower than premium websites. The analysis of highlighted segments and words revealed that AR/VR applications strategically emphasize critical privacy practices and key terms. This enhances privacy policies' clarity and effectiveness.
I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
Jan 14, 2025


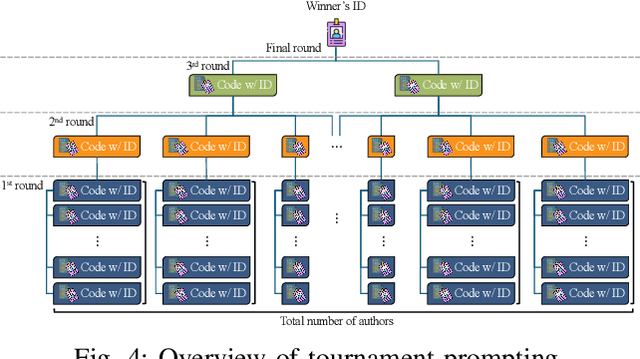
Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.
Simple Perturbations Subvert Ethereum Phishing Transactions Detection: An Empirical Analysis
Aug 06, 2024



This paper explores the vulnerability of machine learning models, specifically Random Forest, Decision Tree, and K-Nearest Neighbors, to very simple single-feature adversarial attacks in the context of Ethereum fraudulent transaction detection. Through comprehensive experimentation, we investigate the impact of various adversarial attack strategies on model performance metrics, such as accuracy, precision, recall, and F1-score. Our findings, highlighting how prone those techniques are to simple attacks, are alarming, and the inconsistency in the attacks' effect on different algorithms promises ways for attack mitigation. We examine the effectiveness of different mitigation strategies, including adversarial training and enhanced feature selection, in enhancing model robustness.
Untargeted Code Authorship Evasion with Seq2Seq Transformation
Nov 26, 2023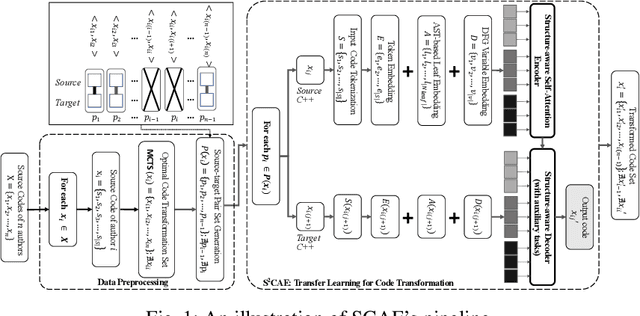



Code authorship attribution is the problem of identifying authors of programming language codes through the stylistic features in their codes, a topic that recently witnessed significant interest with outstanding performance. In this work, we present SCAE, a code authorship obfuscation technique that leverages a Seq2Seq code transformer called StructCoder. SCAE customizes StructCoder, a system designed initially for function-level code translation from one language to another (e.g., Java to C#), using transfer learning. SCAE improved the efficiency at a slight accuracy degradation compared to existing work. We also reduced the processing time by about 68% while maintaining an 85% transformation success rate and up to 95.77% evasion success rate in the untargeted setting.