 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizer-Aware Hierarchical Neural Codec Modeling for Speech Deepfake Detection
Mar 10, 2026Neural audio codecs discretize speech via residual vector quantization (RVQ), forming a coarse-to-fine hierarchy across quantizers. While codec models have been explored for representation learning, their discrete structure remains underutilized in speech deepfake detection. In particular, different quantization levels capture complementary acoustic cues, where early quantizers encode coarse structure and later quantizers refine residual details that reveal synthesis artifacts. Existing systems either rely on continuous encoder features or ignore this quantizer-level hierarchy. We propose a hierarchy-aware representation learning framework that models quantizer-level contributions through learnable global weighting, enabling structured codec representations aligned with forensic cues. Keeping the speech encoder backbone frozen and updating only 4.4% additional parameters, our method achieves relative EER reductions of 46.2% on ASVspoof 2019 and 13.9% on ASVspoof5 over strong baselines.
I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
Jan 14, 2025


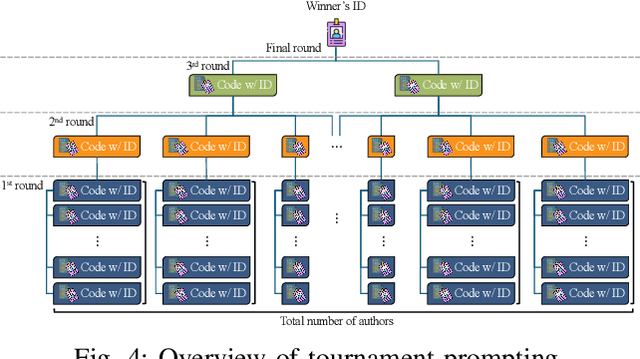
Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.
Meta-TTT: A Meta-learning Minimax Framework For Test-Time Training
Oct 02, 2024
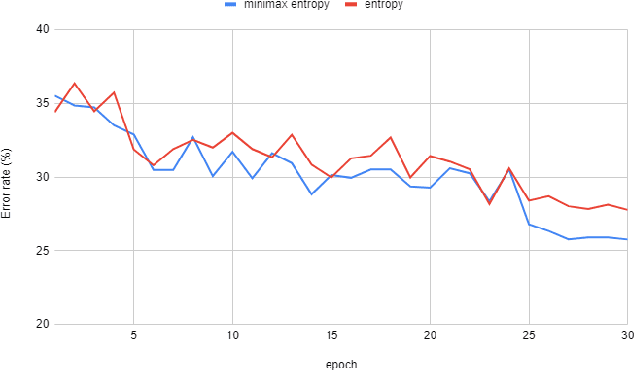


Test-time domain adaptation is a challenging task that aims to adapt a pre-trained model to limited, unlabeled target data during inference. Current methods that rely on self-supervision and entropy minimization underperform when the self-supervised learning (SSL) task does not align well with the primary objective. Additionally, minimizing entropy can lead to suboptimal solutions when there is limited diversity within minibatches. This paper introduces a meta-learning minimax framework for test-time training on batch normalization (BN) layers, ensuring that the SSL task aligns with the primary task while addressing minibatch overfitting. We adopt a mixed-BN approach that interpolates current test batch statistics with the statistics from source domains and propose a stochastic domain synthesizing method to improve model generalization and robustness to domain shifts. Extensive experiments demonstrate that our method surpasses state-of-the-art techniques across various domain adaptation and generalization benchmarks, significantly enhancing the pre-trained model's robustness on unseen domains.
Unsupervised Fingerphoto Presentation Attack Detection With Diffusion Models
Sep 27, 2024
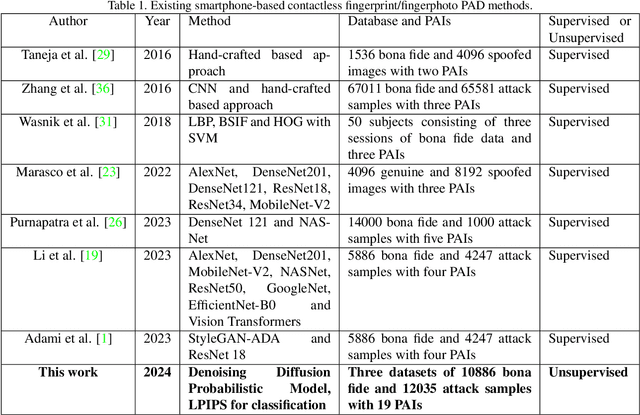
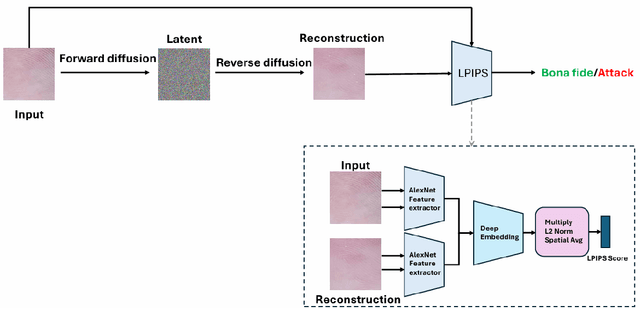
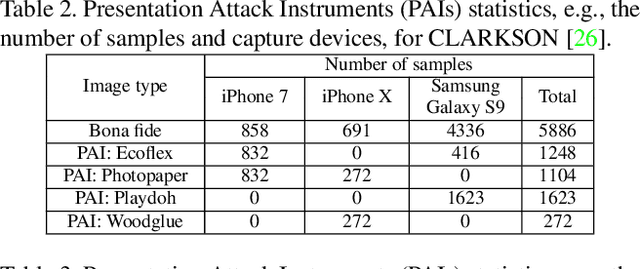
Smartphone-based contactless fingerphoto authentication has become a reliable alternative to traditional contact-based fingerprint biometric systems owing to rapid advances in smartphone camera technology. Despite its convenience, fingerprint authentication through fingerphotos is more vulnerable to presentation attacks, which has motivated recent research efforts towards developing fingerphoto Presentation Attack Detection (PAD) techniques. However, prior PAD approaches utilized supervised learning methods that require labeled training data for both bona fide and attack samples. This can suffer from two key issues, namely (i) generalization:the detection of novel presentation attack instruments (PAIs) unseen in the training data, and (ii) scalability:the collection of a large dataset of attack samples using different PAIs. To address these challenges, we propose a novel unsupervised approach based on a state-of-the-art deep-learning-based diffusion model, the Denoising Diffusion Probabilistic Model (DDPM), which is trained solely on bona fide samples. The proposed approach detects Presentation Attacks (PA) by calculating the reconstruction similarity between the input and output pairs of the DDPM. We present extensive experiments across three PAI datasets to test the accuracy and generalization capability of our approach. The results show that the proposed DDPM-based PAD method achieves significantly better detection error rates on several PAI classes compared to other baseline unsupervised approaches.