 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishing for Phishers: Learning-Based Phishing Detection in Ethereum Transactions
Apr 24, 2025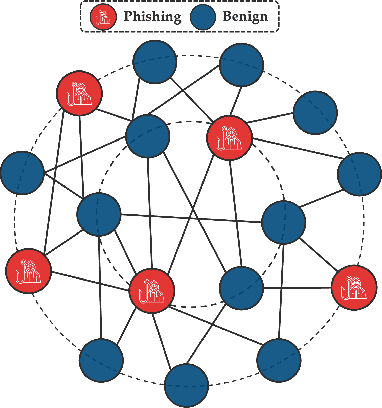

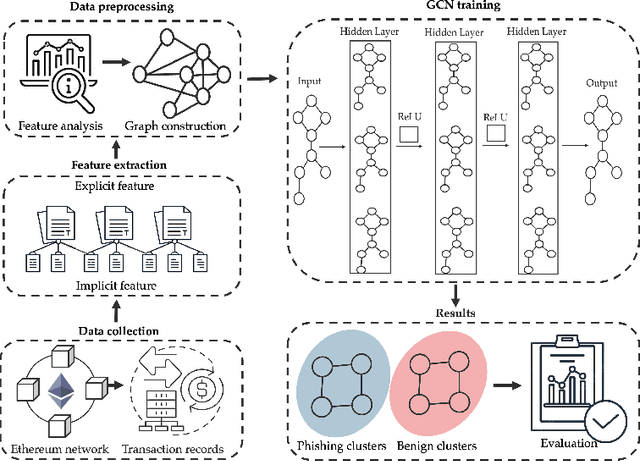

Phishing detection on Ethereum has increasingly leveraged advanced machine learning techniques to identify fraudulent transactions. However, limited attention has been given to understanding the effectiveness of feature selection strategies and the role of graph-based models in enhancing detection accuracy. In this paper, we systematically examine these issues by analyzing and contrasting explicit transactional features and implicit graph-based features, both experimentally and analytically. We explore how different feature sets impact the performance of phishing detection models, particularly in the context of Ethereum's transactional network. Additionally, we address key challenges such as class imbalance and dataset composition and their influence on the robustness and precision of detection methods. Our findings demonstrate the advantages and limitations of each feature type, while also providing a clearer understanding of how feature affect model resilience and generalization in adversarial environments.
Security and Quality in LLM-Generated Code: A Multi-Language, Multi-Model Analysis
Feb 03, 2025



Artificial Intelligence (AI)-driven code generation tools are increasingly used throughout the software development lifecycle to accelerate coding tasks. However, the security of AI-generated code using Large Language Models (LLMs) remains underexplored, with studies revealing various risks and weaknesses. This paper analyzes the security of code generated by LLMs across different programming languages. We introduce a dataset of 200 tasks grouped into six categories to evaluate the performance of LLMs in generating secure and maintainable code. Our research shows that while LLMs can automate code creation, their security effectiveness varies by language. Many models fail to utilize modern security features in recent compiler and toolkit updates, such as Java 17. Moreover, outdated methods are still commonly used, particularly in C++. This highlights the need for advancing LLMs to enhance security and quality while incorporating emerging best practices in programming languages.
I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
Jan 14, 2025


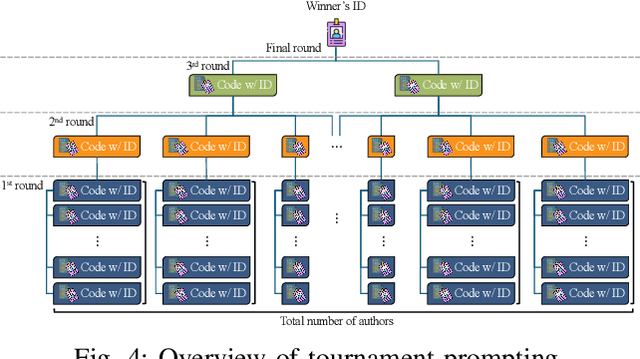
Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.
Untargeted Code Authorship Evasion with Seq2Seq Transformation
Nov 26, 2023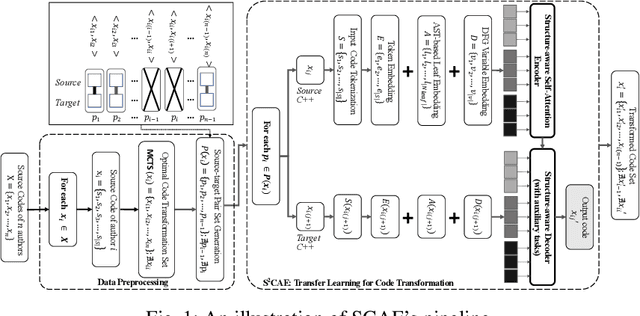



Code authorship attribution is the problem of identifying authors of programming language codes through the stylistic features in their codes, a topic that recently witnessed significant interest with outstanding performance. In this work, we present SCAE, a code authorship obfuscation technique that leverages a Seq2Seq code transformer called StructCoder. SCAE customizes StructCoder, a system designed initially for function-level code translation from one language to another (e.g., Java to C#), using transfer learning. SCAE improved the efficiency at a slight accuracy degradation compared to existing work. We also reduced the processing time by about 68% while maintaining an 85% transformation success rate and up to 95.77% evasion success rate in the untargeted setting.
Robust Natural Language Processing: Recent Advances, Challenges, and Future Directions
Jan 03, 2022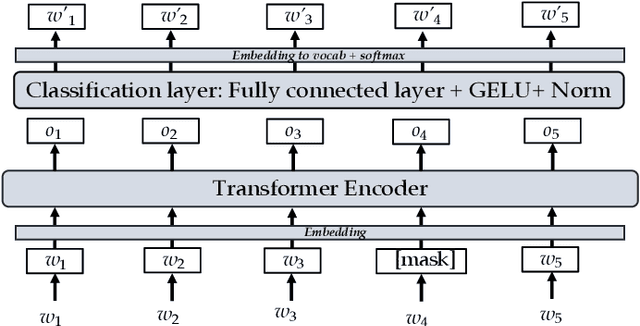
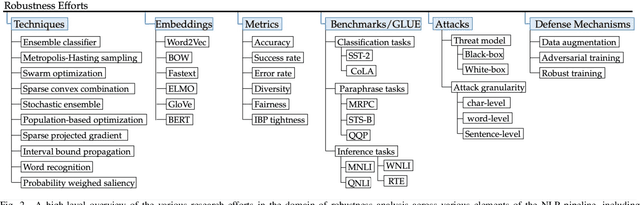
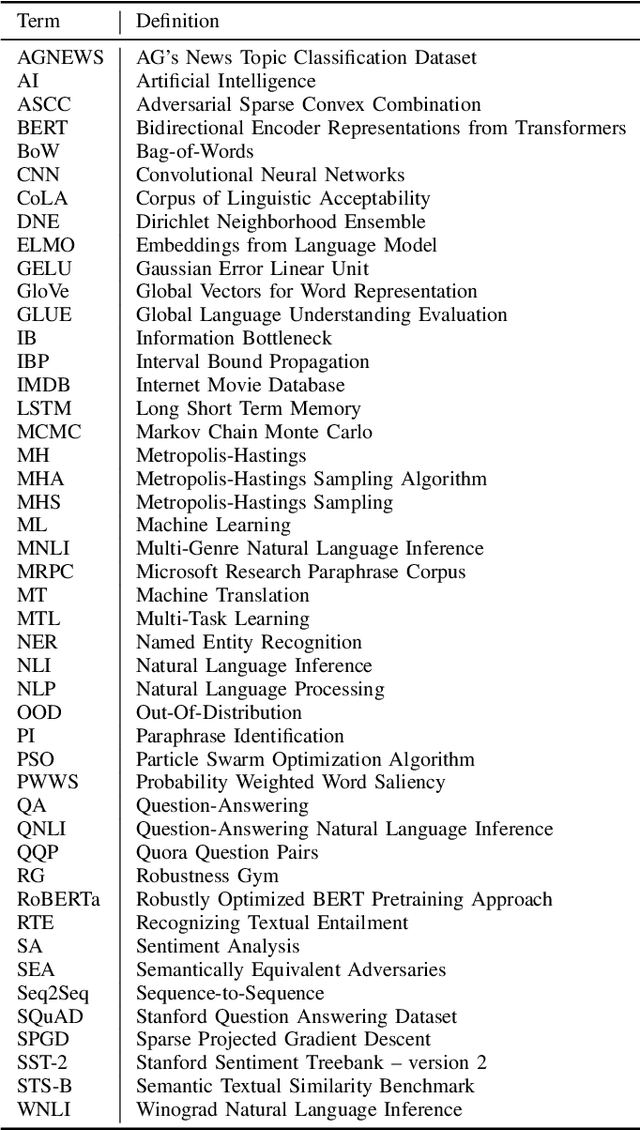
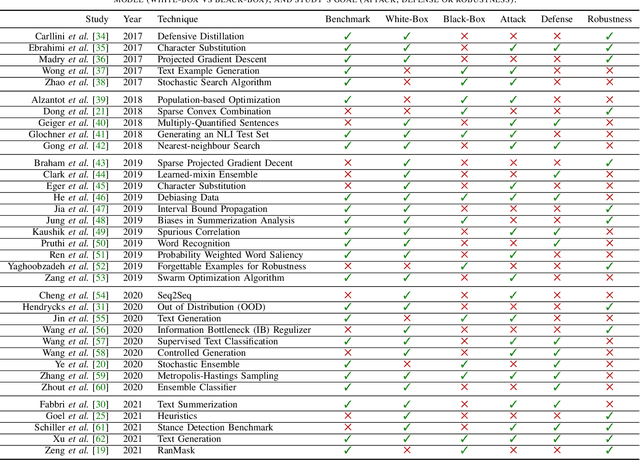
Recent natural language processing (NLP) techniques have accomplished high performance on benchmark datasets, primarily due to the significant improvement in the performance of deep learning. The advances in the research community have led to great enhancements in state-of-the-art production systems for NLP tasks, such as virtual assistants, speech recognition, and sentiment analysis. However, such NLP systems still often fail when tested with adversarial attacks. The initial lack of robustness exposed troubling gaps in current models' language understanding capabilities, creating problems when NLP systems are deployed in real life. In this paper, we present a structured overview of NLP robustness research by summarizing the literature in a systemic way across various dimensions. We then take a deep-dive into the various dimensions of robustness, across techniques, metrics, embeddings, and benchmarks. Finally, we argue that robustness should be multi-dimensional, provide insights into current research, identify gaps in the literature to suggest directions worth pursuing to address these gaps.