 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Vulnerability Reports with Automated and Augmented Description Summarization
Apr 29, 2025Public vulnerability databases, such as the National Vulnerability Database (NVD), document vulnerabilities and facilitate threat information sharing. However, they often suffer from short descriptions and outdated or insufficient information. In this paper, we introduce Zad, a system designed to enrich NVD vulnerability descriptions by leveraging external resources. Zad consists of two pipelines: one collects and filters supplementary data using two encoders to build a detailed dataset, while the other fine-tunes a pre-trained model on this dataset to generate enriched descriptions. By addressing brevity and improving content quality, Zad produces more comprehensive and cohesive vulnerability descriptions. We evaluate Zad using standard summarization metrics and human assessments, demonstrating its effectiveness in enhancing vulnerability information.
Untargeted Code Authorship Evasion with Seq2Seq Transformation
Nov 26, 2023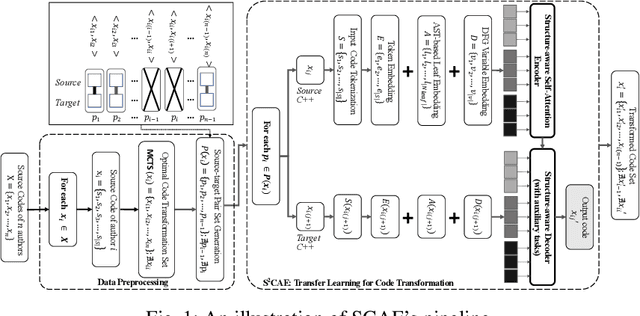



Code authorship attribution is the problem of identifying authors of programming language codes through the stylistic features in their codes, a topic that recently witnessed significant interest with outstanding performance. In this work, we present SCAE, a code authorship obfuscation technique that leverages a Seq2Seq code transformer called StructCoder. SCAE customizes StructCoder, a system designed initially for function-level code translation from one language to another (e.g., Java to C#), using transfer learning. SCAE improved the efficiency at a slight accuracy degradation compared to existing work. We also reduced the processing time by about 68% while maintaining an 85% transformation success rate and up to 95.77% evasion success rate in the untargeted setting.
SHIELD: Thwarting Code Authorship Attribution
Apr 26, 2023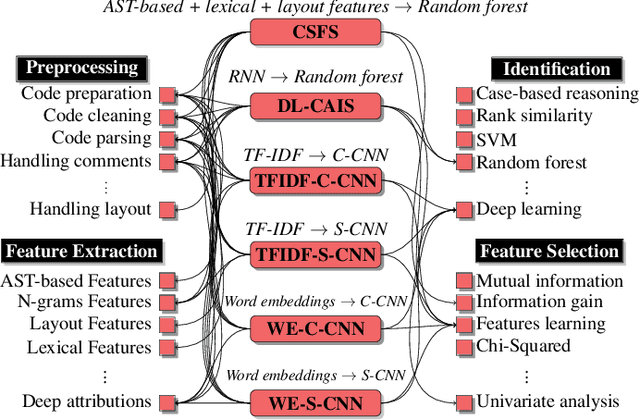



Authorship attribution has become increasingly accurate, posing a serious privacy risk for programmers who wish to remain anonymous. In this paper, we introduce SHIELD to examine the robustness of different code authorship attribution approaches against adversarial code examples. We define four attacks on attribution techniques, which include targeted and non-targeted attacks, and realize them using adversarial code perturbation. We experiment with a dataset of 200 programmers from the Google Code Jam competition to validate our methods targeting six state-of-the-art authorship attribution methods that adopt a variety of techniques for extracting authorship traits from source-code, including RNN, CNN, and code stylometry. Our experiments demonstrate the vulnerability of current authorship attribution methods against adversarial attacks. For the non-targeted attack, our experiments demonstrate the vulnerability of current authorship attribution methods against the attack with an attack success rate exceeds 98.5\% accompanied by a degradation of the identification confidence that exceeds 13\%. For the targeted attacks, we show the possibility of impersonating a programmer using targeted-adversarial perturbations with a success rate ranging from 66\% to 88\% for different authorship attribution techniques under several adversarial scenarios.
Robust Natural Language Processing: Recent Advances, Challenges, and Future Directions
Jan 03, 2022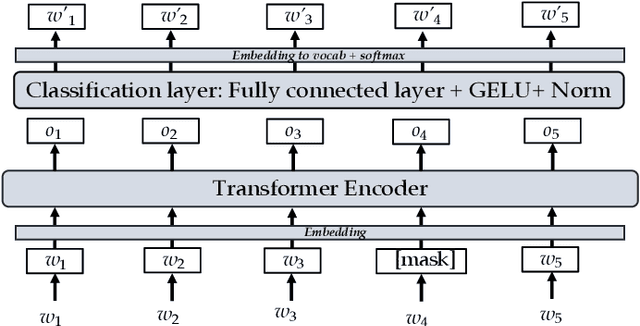
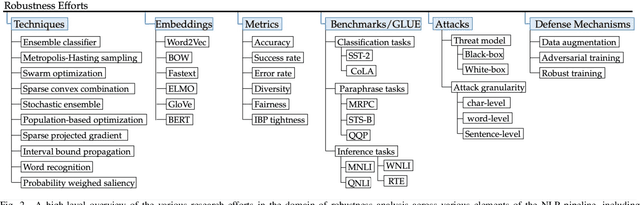
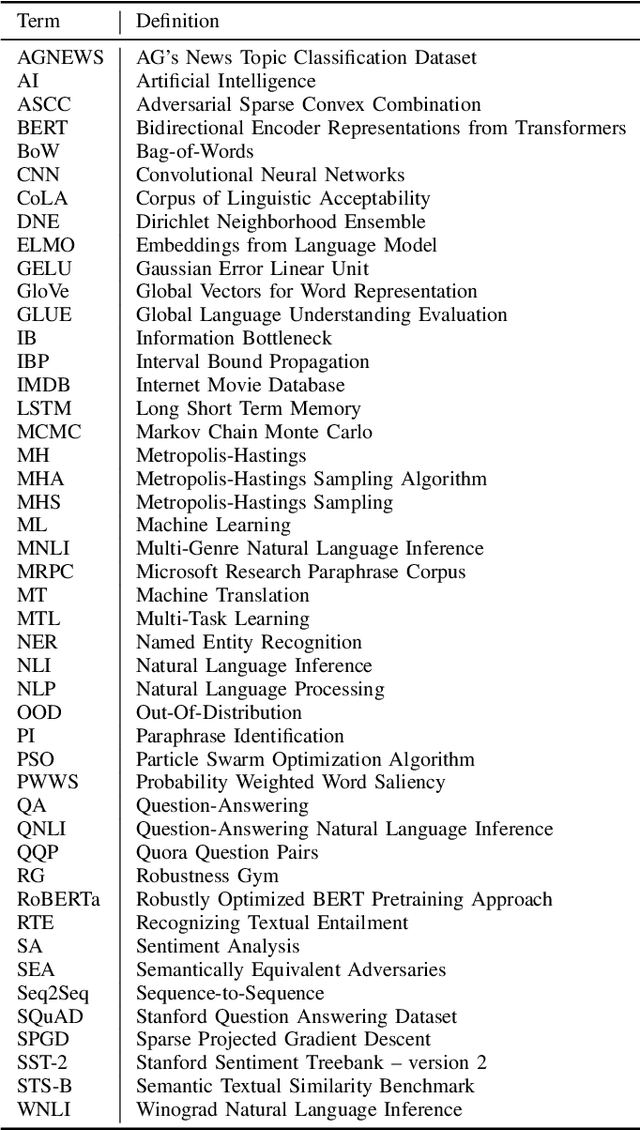
Recent natural language processing (NLP) techniques have accomplished high performance on benchmark datasets, primarily due to the significant improvement in the performance of deep learning. The advances in the research community have led to great enhancements in state-of-the-art production systems for NLP tasks, such as virtual assistants, speech recognition, and sentiment analysis. However, such NLP systems still often fail when tested with adversarial attacks. The initial lack of robustness exposed troubling gaps in current models' language understanding capabilities, creating problems when NLP systems are deployed in real life. In this paper, we present a structured overview of NLP robustness research by summarizing the literature in a systemic way across various dimensions. We then take a deep-dive into the various dimensions of robustness, across techniques, metrics, embeddings, and benchmarks. Finally, we argue that robustness should be multi-dimensional, provide insights into current research, identify gaps in the literature to suggest directions worth pursuing to address these gaps.
Generating Adversarial Examples with an Optimized Quality
Jun 30, 2020
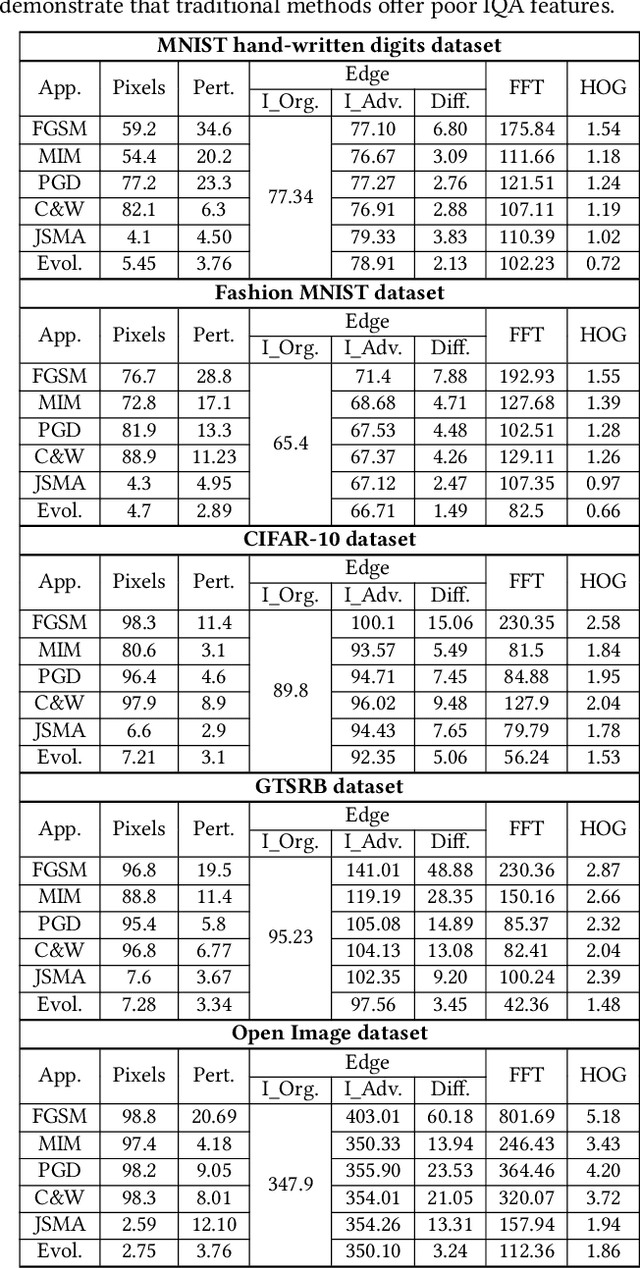
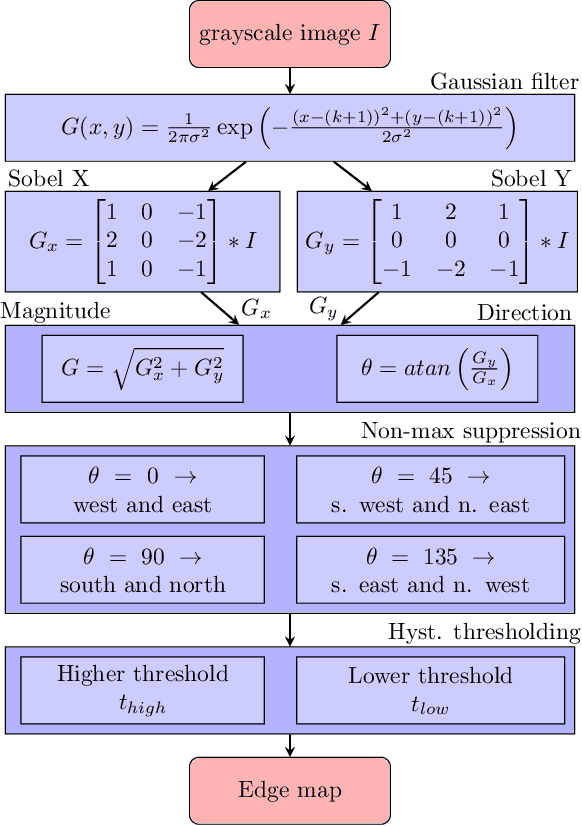
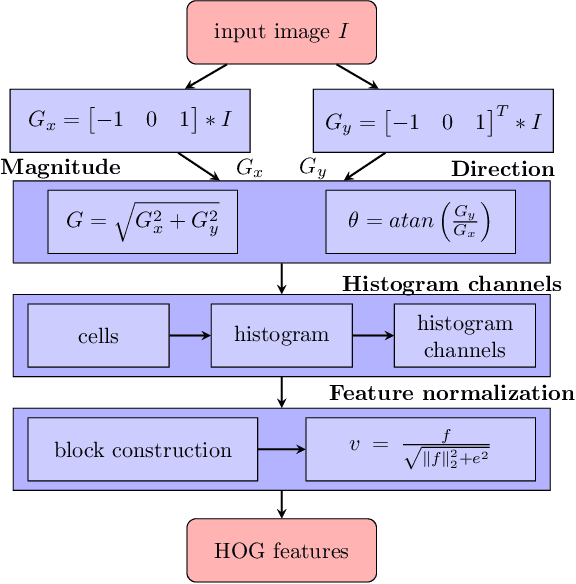
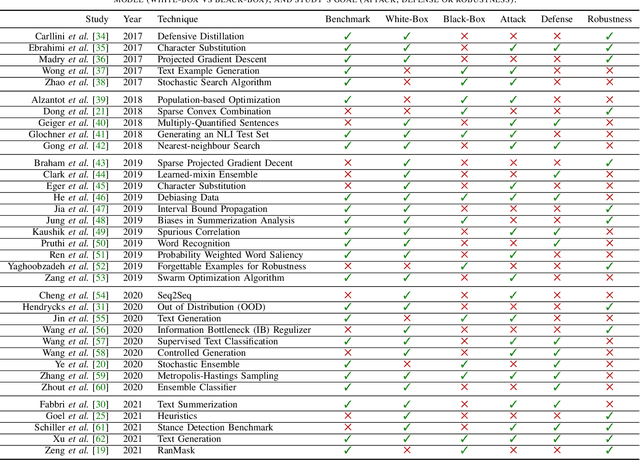
Deep learning models are widely used in a range of application areas, such as computer vision, computer security, etc. However, deep learning models are vulnerable to Adversarial Examples (AEs),carefully crafted samples to deceive those models. Recent studies have introduced new adversarial attack methods, but, to the best of our knowledge, none provided guaranteed quality for the crafted examples as part of their creation, beyond simple quality measures such as Misclassification Rate (MR). In this paper, we incorporateImage Quality Assessment (IQA) metrics into the design and generation process of AEs. We propose an evolutionary-based single- and multi-objective optimization approaches that generate AEs with high misclassification rate and explicitly improve the quality, thus indistinguishability, of the samples, while perturbing only a limited number of pixels. In particular, several IQA metrics, including edge analysis, Fourier analysis, and feature descriptors, are leveraged into the process of generating AEs. Unique characteristics of the evolutionary-based algorithm enable us to simultaneously optimize the misclassification rate and the IQA metrics of the AEs. In order to evaluate the performance of the proposed method, we conduct intensive experiments on different well-known benchmark datasets(MNIST, CIFAR, GTSRB, and Open Image Dataset V5), while considering various objective optimization configurations. The results obtained from our experiments, when compared with the exist-ing attack methods, validate our initial hypothesis that the use ofIQA metrics within generation process of AEs can substantially improve their quality, while maintaining high misclassification rate.Finally, transferability and human perception studies are provided, demonstrating acceptable performance.
Sensor-based Continuous Authentication of Smartphones' Users Using Behavioral Biometrics: A Survey
Jan 23, 2020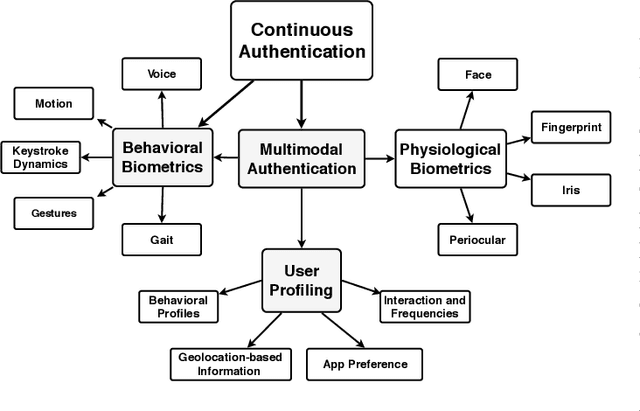
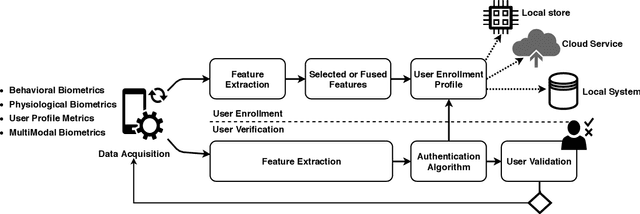
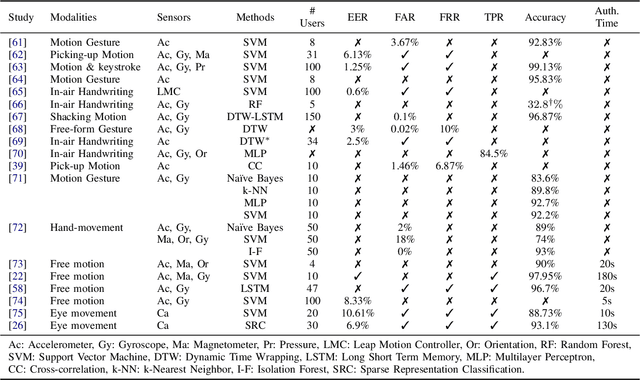
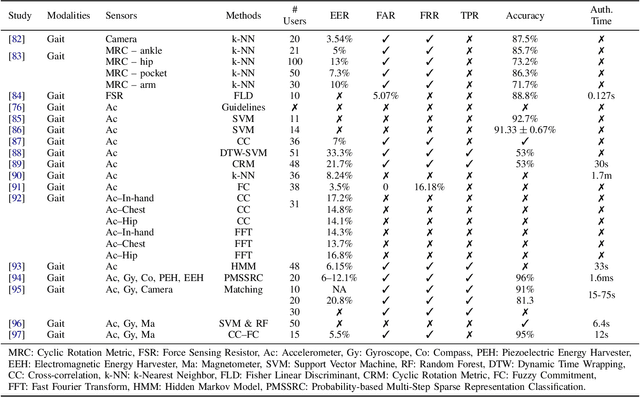
Mobile devices and technologies have become increasingly popular, offering comparable storage and computational capabilities to desktop computers allowing users to store and interact with sensitive and private information. The security and protection of such personal information are becoming more and more important since mobile devices are vulnerable to unauthorized access or theft. User authentication is a task of paramount importance that grants access to legitimate users at the point-of-entry and continuously through the usage session. This task is made possible with today's smartphones' embedded sensors that enable continuous and implicit user authentication by capturing behavioral biometrics and traits. In this paper, we survey more than 140 recent behavioral biometric-based approaches for continuous user authentication, including motion-based methods (27 studies), gait-based methods (23 studies), keystroke dynamics-based methods (20 studies), touch gesture-based methods (29 studies), voice-based methods (16 studies), and multimodal-based methods (33 studies). The survey provides an overview of the current state-of-the-art approaches for continuous user authentication using behavioral biometrics captured by smartphones' embedded sensors, including insights and open challenges for adoption, usability, and performance.
W-Net: A CNN-based Architecture for White Blood Cells Image Classification
Oct 02, 2019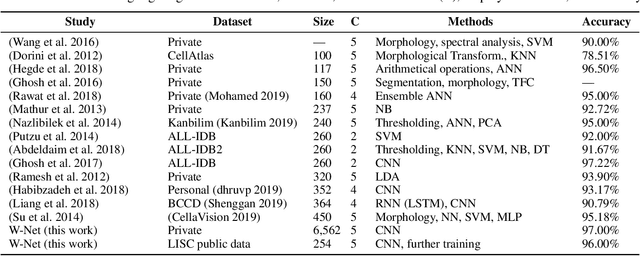
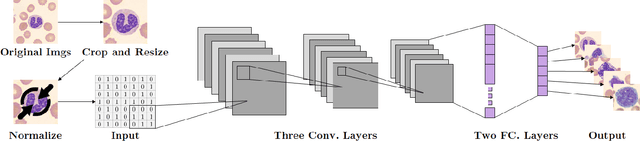
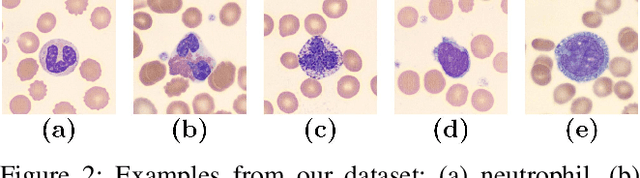
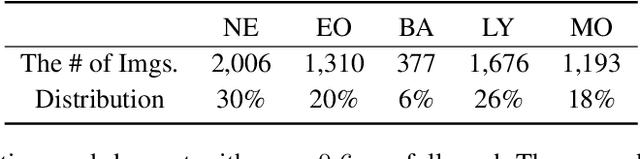
Computer-aided methods for analyzing white blood cells (WBC) have become widely popular due to the complexity of the manual process. Recent works have shown highly accurate segmentation and detection of white blood cells from microscopic blood images. However, the classification of the observed cells is still a challenge and highly demanded as the distribution of the five types reflects on the condition of the immune system. This work proposes W-Net, a CNN-based method for WBC classification. We evaluate W-Net on a real-world large-scale dataset, obtained from The Catholic University of Korea, that includes 6,562 real images of the five WBC types. W-Net achieves an average accuracy of 97%.
COPYCAT: Practical Adversarial Attacks on Visualization-Based Malware Detection
Sep 20, 2019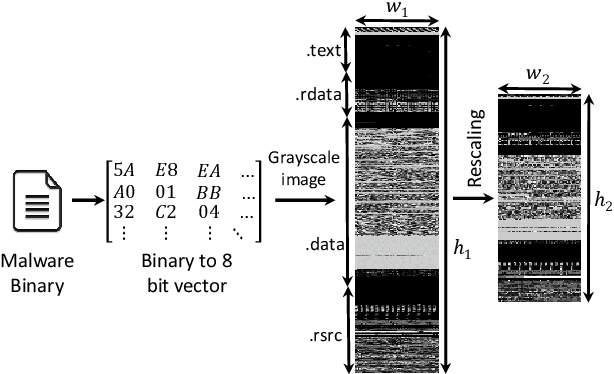


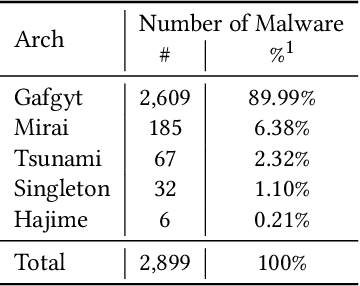
Despite many attempts, the state-of-the-art of adversarial machine learning on malware detection systems generally yield unexecutable samples. In this work, we set out to examine the robustness of visualization-based malware detection system against adversarial examples (AEs) that not only are able to fool the model, but also maintain the executability of the original input. As such, we first investigate the application of existing off-the-shelf adversarial attack approaches on malware detection systems through which we found that those approaches do not necessarily maintain the functionality of the original inputs. Therefore, we proposed an approach to generate adversarial examples, COPYCAT, which is specifically designed for malware detection systems considering two main goals; achieving a high misclassification rate and maintaining the executability and functionality of the original input. We designed two main configurations for COPYCAT, namely AE padding and sample injection. While the first configuration results in untargeted misclassification attacks, the sample injection configuration is able to force the model to generate a targeted output, which is highly desirable in the malware attribution setting. We evaluate the performance of COPYCAT through an extensive set of experiments on two malware datasets, and report that we were able to generate adversarial samples that are misclassified at a rate of 98.9% and 96.5% with Windows and IoT binary datasets, respectively, outperforming the misclassification rates in the literature. Most importantly, we report that those AEs were executable unlike AEs generated by off-the-shelf approaches. Our transferability study demonstrates that the generated AEs through our proposed method can be generalized to other models.