 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLITE: A Paradigm Shift in Multi-Object Tracking with Efficient ReID Feature Integration
Sep 06, 2024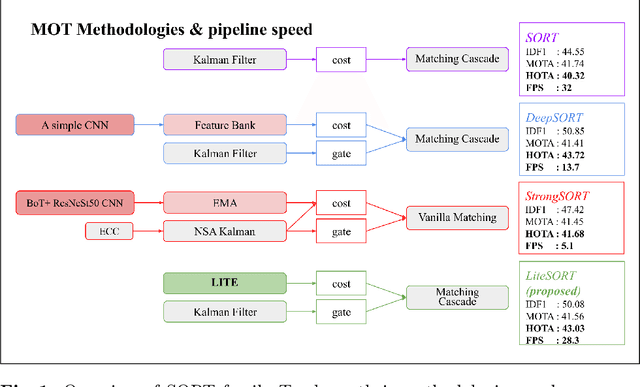
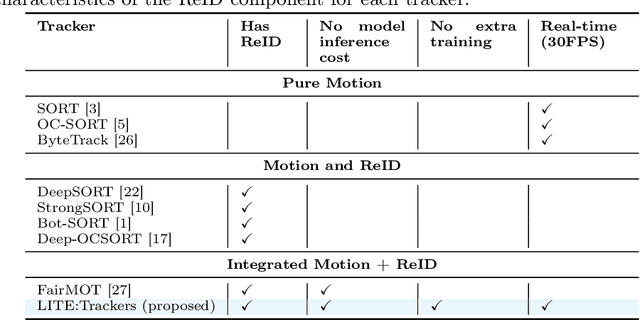
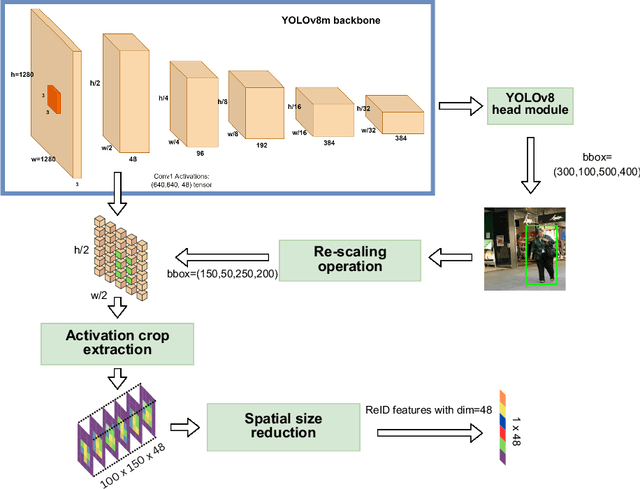
The Lightweight Integrated Tracking-Feature Extraction (LITE) paradigm is introduced as a novel multi-object tracking (MOT) approach. It enhances ReID-based trackers by eliminating inference, pre-processing, post-processing, and ReID model training costs. LITE uses real-time appearance features without compromising speed. By integrating appearance feature extraction directly into the tracking pipeline using standard CNN-based detectors such as YOLOv8m, LITE demonstrates significant performance improvements. The simplest implementation of LITE on top of classic DeepSORT achieves a HOTA score of 43.03% at 28.3 FPS on the MOT17 benchmark, making it twice as fast as DeepSORT on MOT17 and four times faster on the more crowded MOT20 dataset, while maintaining similar accuracy. Additionally, a new evaluation framework for tracking-by-detection approaches reveals that conventional trackers like DeepSORT remain competitive with modern state-of-the-art trackers when evaluated under fair conditions. The code will be available post-publication at https://github.com/Jumabek/LITE.
Edge Device Deployment of Multi-Tasking Network for Self-Driving Operations
Oct 10, 2022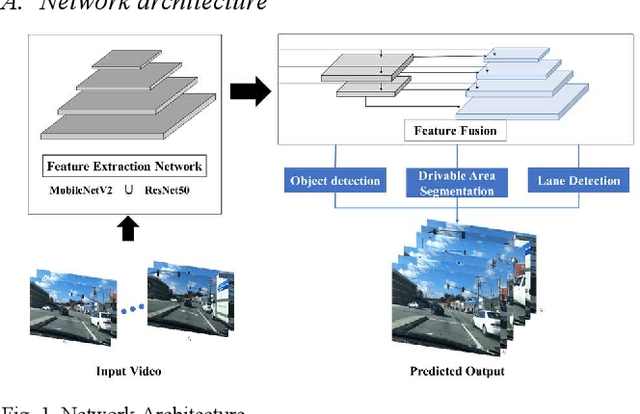


A safe and robust autonomous driving system relies on accurate perception of the environment for application-oriented scenarios. This paper proposes deployment of the three most crucial tasks (i.e., object detection, drivable area segmentation and lane detection tasks) on embedded system for self-driving operations. To achieve this research objective, multi-tasking network is utilized with a simple encoder-decoder architecture. Comprehensive and extensive comparisons for two models based on different backbone networks are performed. All training experiments are performed on server while Nvidia Jetson Xavier NX is chosen as deployment device.
* arXiv admin note: text overlap with arXiv:1908.08926 by other authors
1D CNN Based Network Intrusion Detection with Normalization on Imbalanced Data
Mar 04, 2020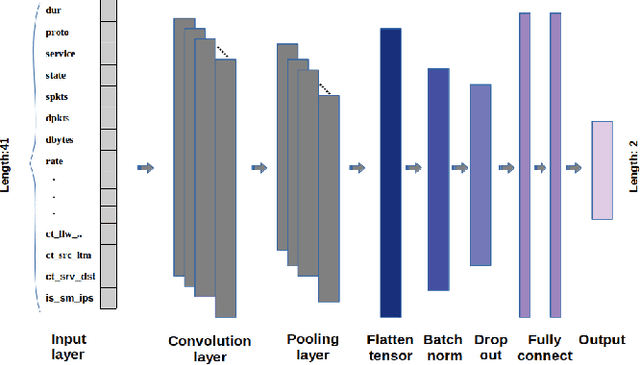

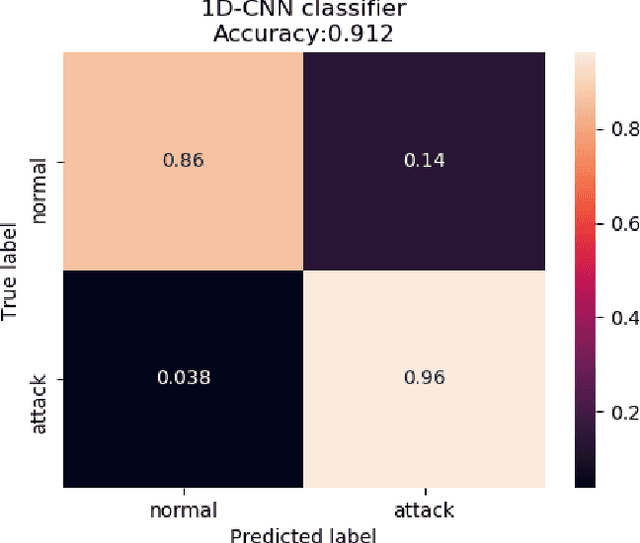

Intrusion detection system (IDS) plays an essential role in computer networks protecting computing resources and data from outside attacks. Recent IDS faces challenges improving flexibility and efficiency of the IDS for unexpected and unpredictable attacks. Deep neural network (DNN) is considered popularly for complex systems to abstract features and learn as a machine learning technique. In this paper, we propose a deep learning approach for developing the efficient and flexible IDS using one-dimensional Convolutional Neural Network (1D-CNN). Two-dimensional CNN methods have shown remarkable performance in detecting objects of images in computer vision area. Meanwhile, the 1D-CNN can be used for supervised learning on time-series data. We establish a machine learning model based on the 1D-CNN by serializing Transmission Control Protocol/Internet Protocol (TCP/IP) packets in a predetermined time range as an invasion Internet traffic model for the IDS, where normal and abnormal network traffics are categorized and labeled for supervised learning in the 1D-CNN. We evaluated our model on UNSW\_NB15 IDS dataset to show the effectiveness of our method. For comparison study in performance, machine learning-based Random Forest (RF) and Support Vector Machine (SVM) models in addition to the 1D-CNN with various network parameters and architecture are exploited. In each experiment, the models are run up to 200 epochs with a learning rate in 0.0001 on imbalanced and balanced data. 1D-CNN and its variant architectures have outperformed compared to the classical machine learning classifiers. This is mainly due to the reason that CNN has the capability to extract high-level feature representations that represent the abstract form of low-level feature sets of network traffic connections.
* Need more polishing
W-Net: A CNN-based Architecture for White Blood Cells Image Classification
Oct 02, 2019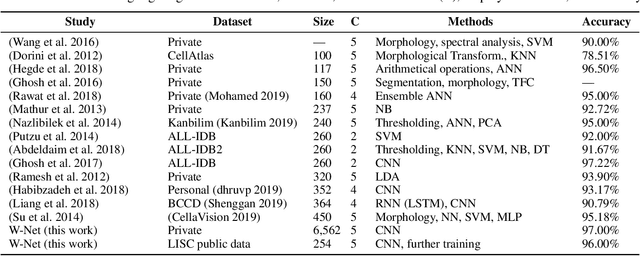
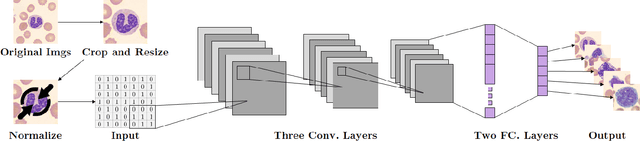
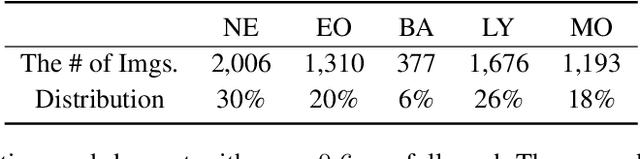
Computer-aided methods for analyzing white blood cells (WBC) have become widely popular due to the complexity of the manual process. Recent works have shown highly accurate segmentation and detection of white blood cells from microscopic blood images. However, the classification of the observed cells is still a challenge and highly demanded as the distribution of the five types reflects on the condition of the immune system. This work proposes W-Net, a CNN-based method for WBC classification. We evaluate W-Net on a real-world large-scale dataset, obtained from The Catholic University of Korea, that includes 6,562 real images of the five WBC types. W-Net achieves an average accuracy of 97%.
Transfer Learning Based on AdaBoost for Feature Selection from Multiple ConvNet Layer Features
Mar 25, 2016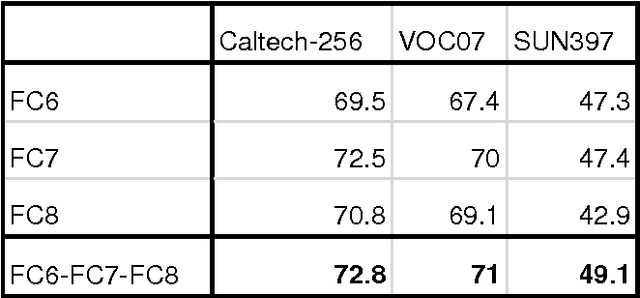
Convolutional Networks (ConvNets) are powerful models that learn hierarchies of visual features, which could also be used to obtain image representations for transfer learning. The basic pipeline for transfer learning is to first train a ConvNet on a large dataset (source task) and then use feed-forward units activation of the trained ConvNet as image representation for smaller datasets (target task). Our key contribution is to demonstrate superior performance of multiple ConvNet layer features over single ConvNet layer features. Combining multiple ConvNet layer features will result in more complex feature space with some features being repetitive. This requires some form of feature selection. We use AdaBoost with single stumps to implicitly select only distinct features that are useful towards classification from concatenated ConvNet features. Experimental results show that using multiple ConvNet layer activation features instead of single ConvNet layer features consistently will produce superior performance. Improvements becomes significant as we increase the distance between source task and the target task.