 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLITE: A Paradigm Shift in Multi-Object Tracking with Efficient ReID Feature Integration
Sep 06, 2024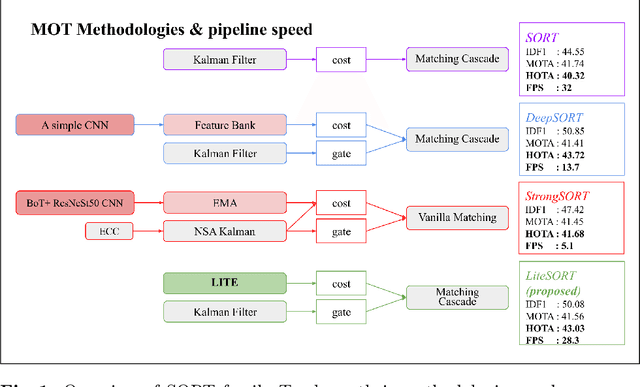
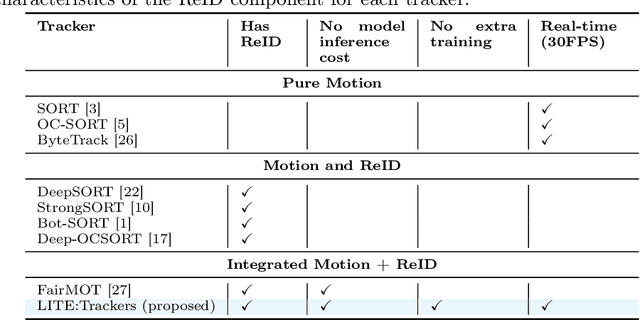
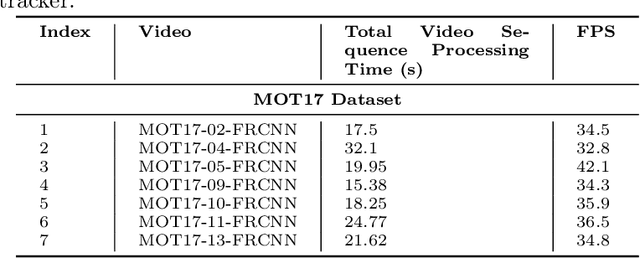
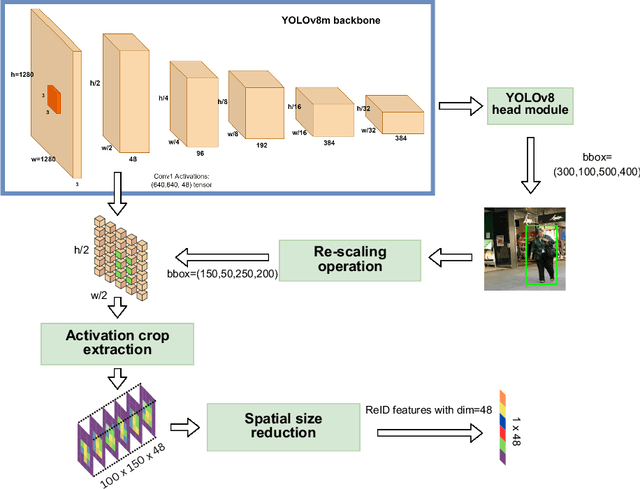
The Lightweight Integrated Tracking-Feature Extraction (LITE) paradigm is introduced as a novel multi-object tracking (MOT) approach. It enhances ReID-based trackers by eliminating inference, pre-processing, post-processing, and ReID model training costs. LITE uses real-time appearance features without compromising speed. By integrating appearance feature extraction directly into the tracking pipeline using standard CNN-based detectors such as YOLOv8m, LITE demonstrates significant performance improvements. The simplest implementation of LITE on top of classic DeepSORT achieves a HOTA score of 43.03% at 28.3 FPS on the MOT17 benchmark, making it twice as fast as DeepSORT on MOT17 and four times faster on the more crowded MOT20 dataset, while maintaining similar accuracy. Additionally, a new evaluation framework for tracking-by-detection approaches reveals that conventional trackers like DeepSORT remain competitive with modern state-of-the-art trackers when evaluated under fair conditions. The code will be available post-publication at https://github.com/Jumabek/LITE.
Edge Device Deployment of Multi-Tasking Network for Self-Driving Operations
Oct 10, 2022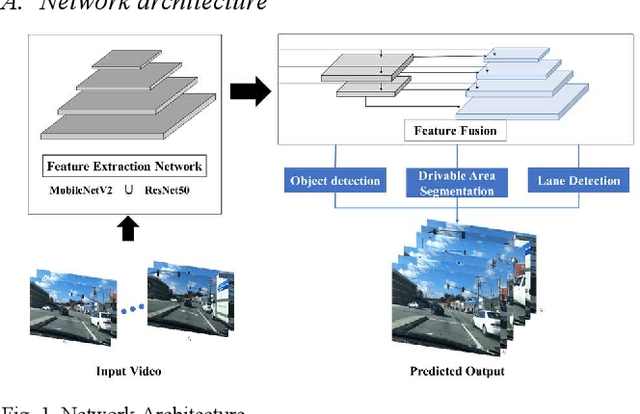


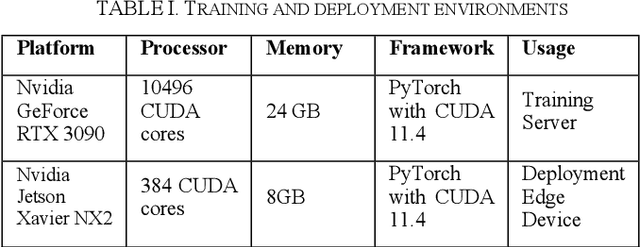
A safe and robust autonomous driving system relies on accurate perception of the environment for application-oriented scenarios. This paper proposes deployment of the three most crucial tasks (i.e., object detection, drivable area segmentation and lane detection tasks) on embedded system for self-driving operations. To achieve this research objective, multi-tasking network is utilized with a simple encoder-decoder architecture. Comprehensive and extensive comparisons for two models based on different backbone networks are performed. All training experiments are performed on server while Nvidia Jetson Xavier NX is chosen as deployment device.
* arXiv admin note: text overlap with arXiv:1908.08926 by other authors
FV-UPatches: Enhancing Universality in Finger Vein Recognition
Jun 02, 2022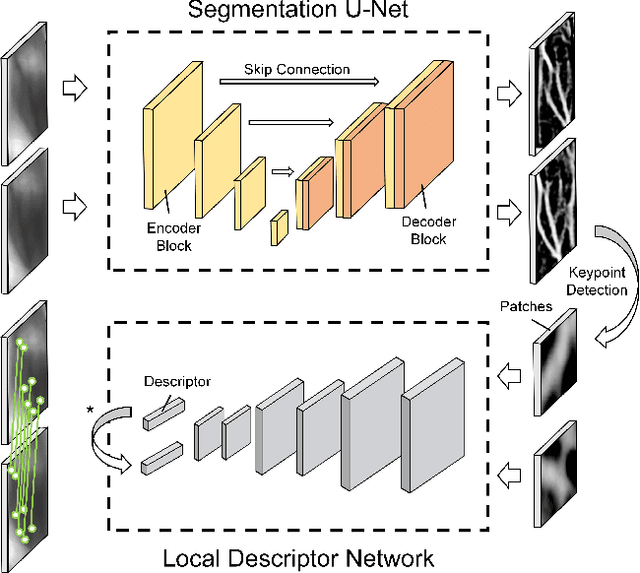


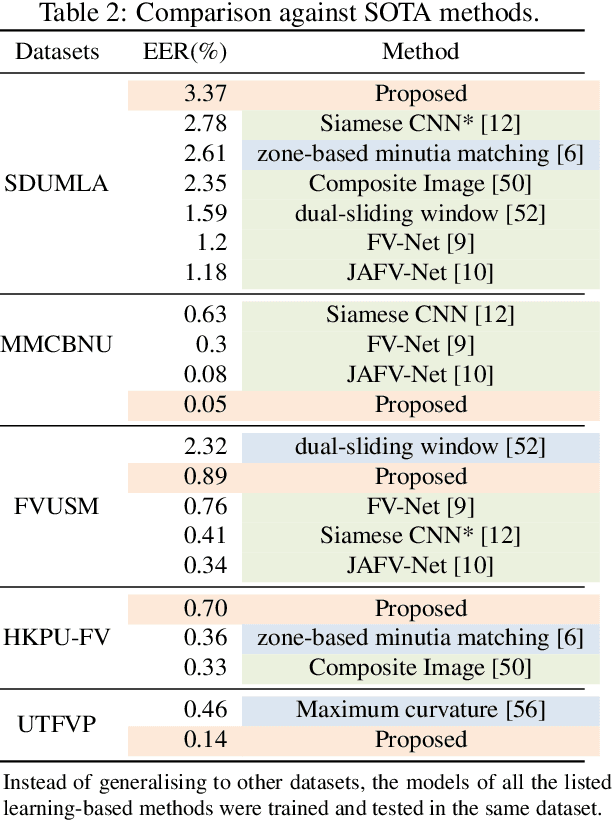
Many deep learning-based models have been introduced in finger vein recognition in recent years. These solutions, however, suffer from data dependency and are difficult to achieve model generalization. To address this problem, we are inspired by the idea of domain adaptation and propose a universal learning-based framework, which achieves generalization while training with limited data. To reduce differences between data distributions, a compressed U-Net is introduced as a domain mapper to map the raw region of interest image onto a target domain. The concentrated target domain is a unified feature space for the subsequent matching, in which a local descriptor model SOSNet is employed to embed patches into descriptors measuring the similarity of matching pairs. In the proposed framework, the domain mapper is an approximation to a specific extraction function thus the training is only a one-time effort with limited data. Moreover, the local descriptor model can be trained to be representative enough based on a public dataset of non-finger-vein images. The whole pipeline enables the framework to be well generalized, making it possible to enhance universality and helps to reduce costs of data collection, tuning and retraining. The comparable experimental results to state-of-the-art (SOTA) performance in five public datasets prove the effectiveness of the proposed framework. Furthermore, the framework shows application potential in other vein-based biometric recognition as well.
Mixture separability loss in a deep convolutional network for image classification
Jun 16, 2019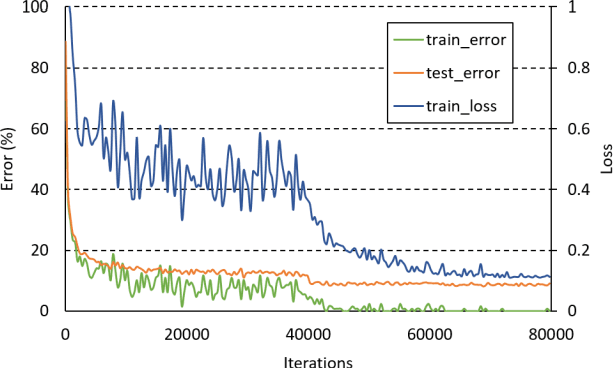

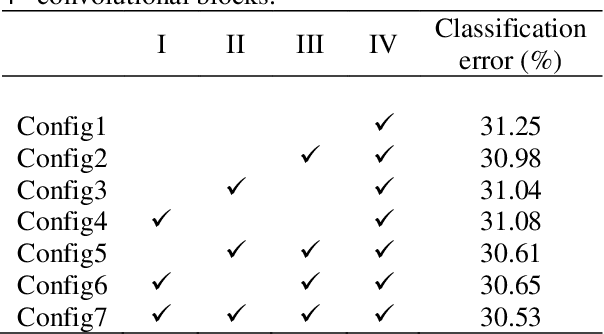
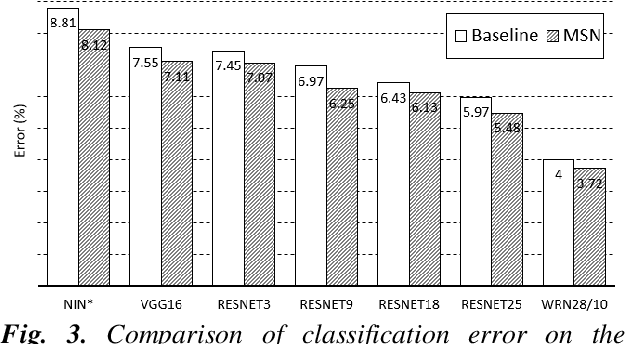
In machine learning, the cost function is crucial because it measures how good or bad a system is. In image classification, well-known networks only consider modifying the network structures and applying cross-entropy loss at the end of the network. However, using only cross-entropy loss causes a network to stop updating weights when all training images are correctly classified. This is the problem of the early saturation. This paper proposes a novel cost function, called mixture separability loss (MSL), which updates the weights of the network even when most of the training images are accurately predicted. MSL consists of between-class and within-class loss. Between-class loss maximizes the differences between inter-class images, whereas within-class loss minimizes the similarities between intra-class images. We designed the proposed loss function to attach to different convolutional layers in the network in order to utilize intermediate feature maps. Experiments show that a network with MSL deepens the learning process and obtains promising results with some public datasets, such as Street View House Number (SVHN), Canadian Institute for Advanced Research (CIFAR), and our self-collected Inha Computer Vision Lab (ICVL) gender dataset.
Real-time and robust multiple-view gender classification using gait features in video surveillance
May 03, 2019

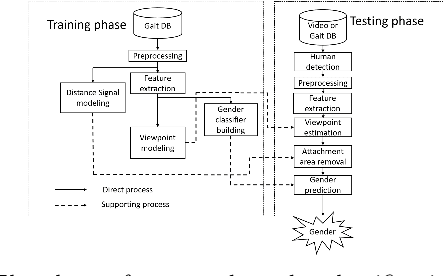

It is common to view people in real applications walking in arbitrary directions, holding items, or wearing heavy coats. These factors are challenges in gait-based application methods because they significantly change a person's appearance. This paper proposes a novel method for classifying human gender in real time using gait information. The use of an average gait image (AGI), rather than a gait energy image (GEI), allows this method to be computationally efficient and robust against view changes. A viewpoint (VP) model is created for automatically determining the viewing angle during the testing phase. A distance signal (DS) model is constructed to remove any areas with an attachment (carried items, worn coats) from a silhouette to reduce the interference in the resulting classification. Finally, the human gender is classified using multiple view-dependent classifiers trained using a support vector machine. Experiment results confirm that the proposed method achieves a high accuracy of 98.8% on the CASIA Dataset B and outperforms the recent state-of-the-art methods.
Blind Deconvolution Method using Omnidirectional Gabor Filter-based Edge Information
May 03, 2019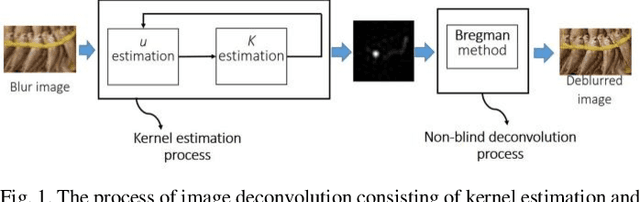



In the previous blind deconvolution methods, de-blurred images can be obtained by using the edge or pixel information. However, the existing edge-based methods did not take advantage of edge information in ommi-directions, but only used horizontal and vertical edges when recovering the de-blurred images. This limitation lowers the quality of the recovered images. This paper proposes a method which utilizes edges in different directions to recover the true sharp image. We also provide a statistical table score to show how many directions are enough to recover a high quality true sharp image. In order to grade the quality of the deblurring image, we introduce a measurement, namely Haar defocus score that takes advantage of the Haar-Wavelet transform. The experimental results prove that the proposed method obtains a high quality deblurred image with respect to both the Haar defocus score and the Peak Signal to Noise Ratio.
Deep CT to MR Synthesis using Paired and Unpaired Data
Sep 03, 2018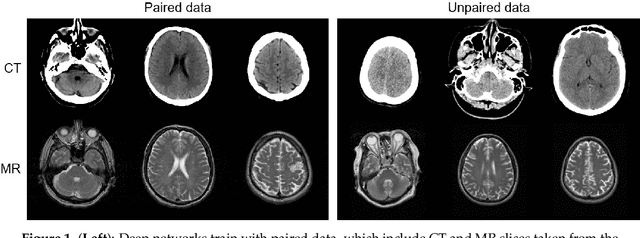
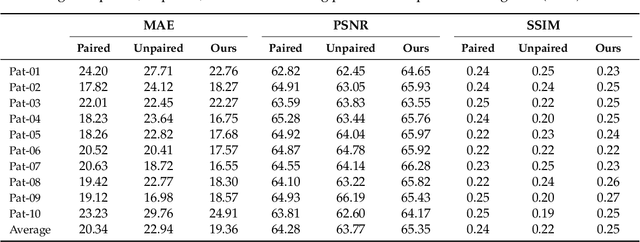
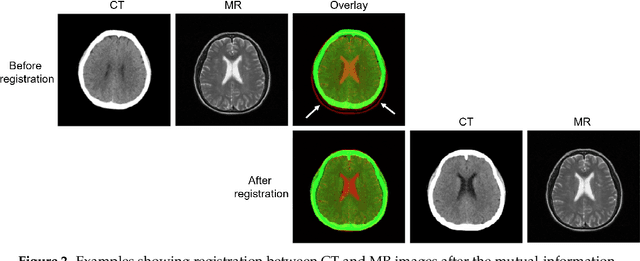
MR imaging will play a very important role in radiotherapy treatment planning for segmentation of tumor volumes and organs. However, the use of MR-based radiotherapy is limited because of the high cost and the increased use of metal implants such as cardiac pacemakers and artificial joints in aging society. To improve the accuracy of CT-based radiotherapy planning, we propose a synthetic approach that translates a CT image into an MR image using paired and unpaired training data. In contrast to the current synthetic methods for medical images, which depend on sparse pairwise-aligned data or plentiful unpaired data, the proposed approach alleviates the rigid registration challenge of paired training and overcomes the context-misalignment problem of the unpaired training. A generative adversarial network was trained to transform 2D brain CT image slices into 2D brain MR image slices, combining adversarial loss, dual cycle-consistent loss, and voxel-wise loss. The experiments were analyzed using CT and MR images of 202 patients. Qualitative and quantitative comparisons against independent paired training and unpaired training methods demonstrate the superiority of our approach.
End-to-End Fingerprints Liveness Detection using Convolutional Networks with Gram module
Mar 21, 2018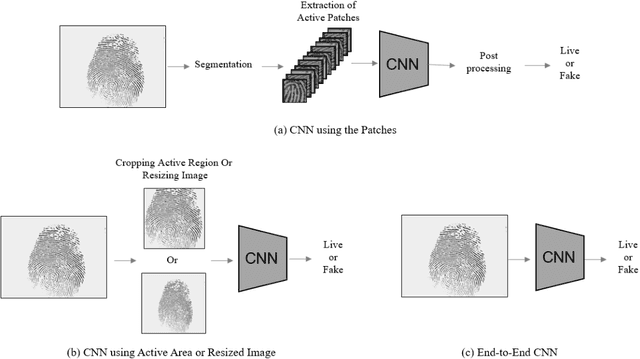
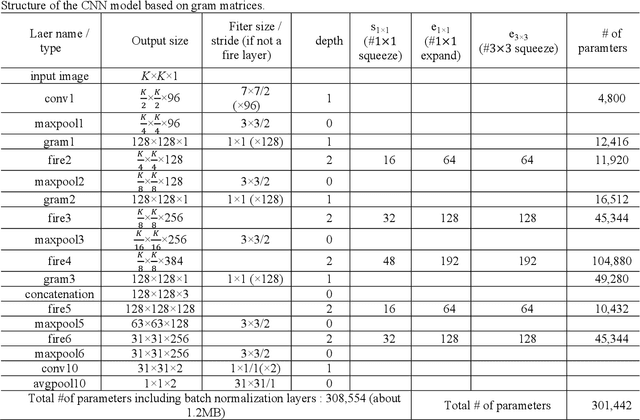
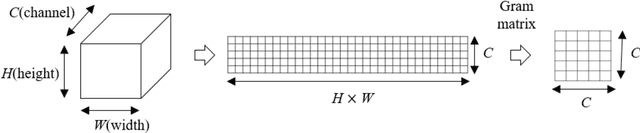
This paper proposes an end-to-end CNN(Convolutional Neural Networks) model that uses gram modules with parameters that are approximately 1.2MB in size to detect fake fingerprints. The proposed method assumes that texture is the most appropriate characteristic in fake fingerprint detection, and implements the gram module to extract textures from the CNN. The proposed CNN structure uses the fire module as the base model and uses the gram module for texture extraction. Tensors that passed the fire module will be joined with gram modules to create a gram matrix with the same spatial size. After 3 gram matrices extracted from different layers are combined with the channel axis, it becomes the basis for categorizing fake fingerprints. The experiment results had an average detection error of 2.61% from the LivDet 2011, 2013, 2015 data, proving that an end-to-end CNN structure with few parameters that is able to be used in fake fingerprint detection can be designed.
Patch-based Fake Fingerprint Detection Using a Fully Convolutional Neural Network with a Small Number of Parameters and an Optimal Threshold
Mar 21, 2018
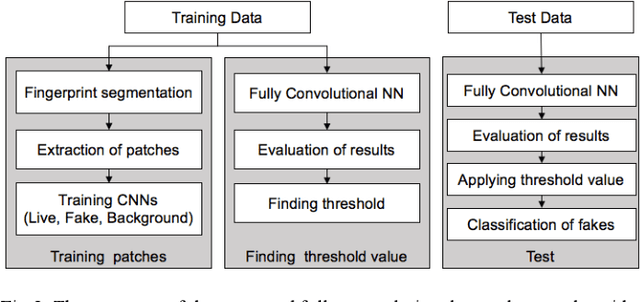
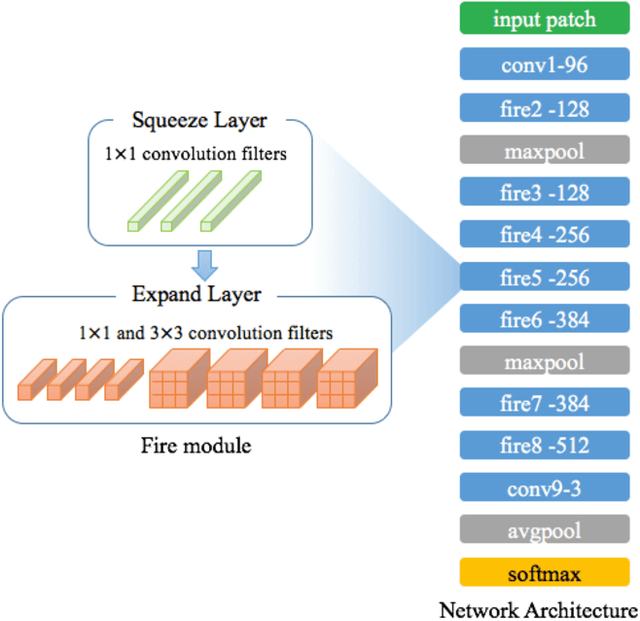
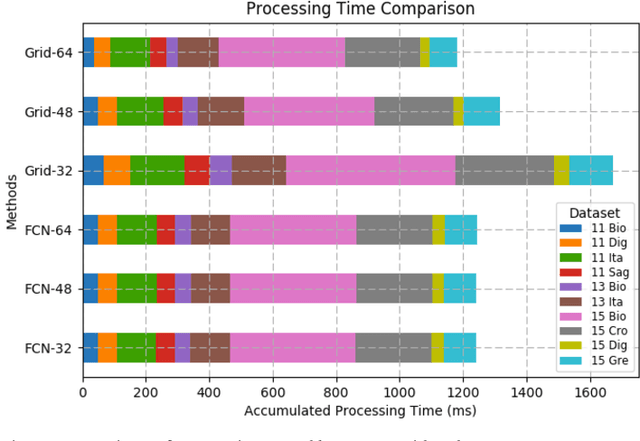
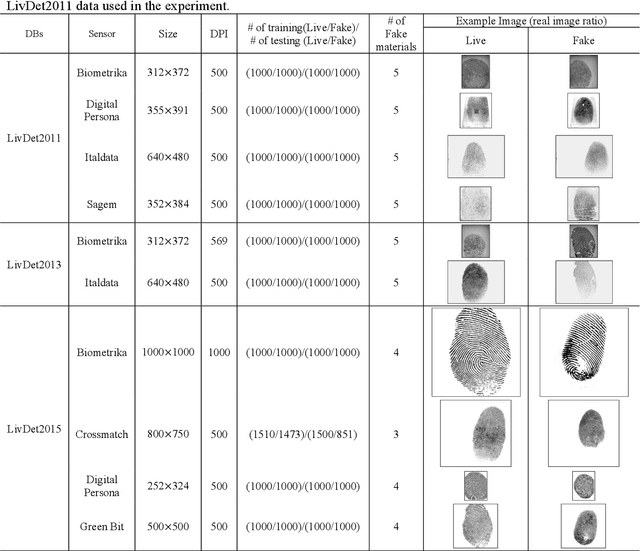
Fingerprint authentication is widely used in biometrics due to its simple process, but it is vulnerable to fake fingerprints. This study proposes a patch-based fake fingerprint detection method using a fully convolutional neural network with a small number of parameters and an optimal threshold to solve the above-mentioned problem. Unlike the existing methods that classify a fingerprint as live or fake, the proposed method classifies fingerprints as fake, live, or background, so preprocessing methods such as segmentation are not needed. The proposed convolutional neural network (CNN) structure applies the Fire module of SqueezeNet, and the fewer parameters used require only 2.0 MB of memory. The network that has completed training is applied to the training data in a fully convolutional way, and the optimal threshold to distinguish fake fingerprints is determined, which is used in the final test. As a result of this study experiment, the proposed method showed an average classification error of 1.35%, demonstrating a fake fingerprint detection method using a high-performance CNN with a small number of parameters.
Real-Time Action Detection in Video Surveillance using Sub-Action Descriptor with Multi-CNN
Oct 10, 2017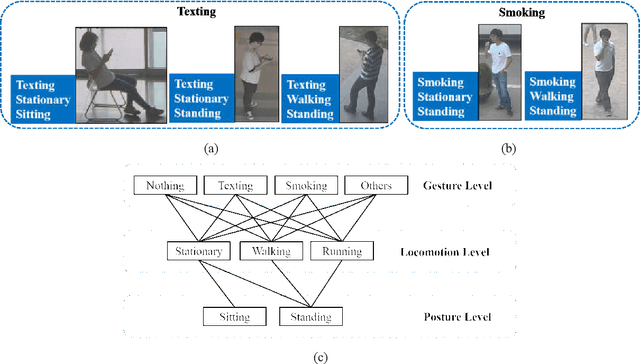

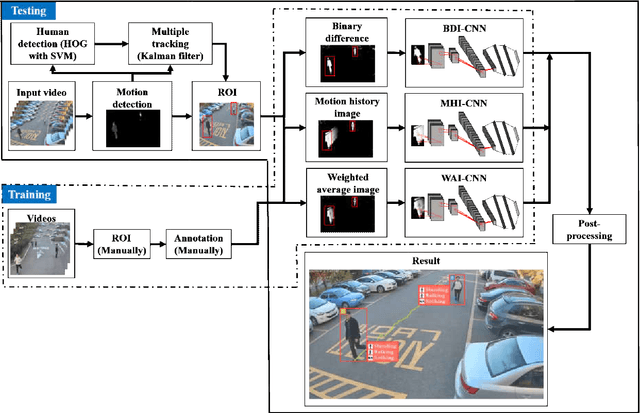
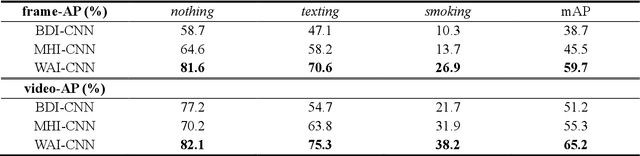
When we say a person is texting, can you tell the person is walking or sitting? Emphatically, no. In order to solve this incomplete representation problem, this paper presents a sub-action descriptor for detailed action detection. The sub-action descriptor consists of three levels: the posture, the locomotion, and the gesture level. The three levels give three sub-action categories for one action to address the representation problem. The proposed action detection model simultaneously localizes and recognizes the actions of multiple individuals in video surveillance using appearance-based temporal features with multi-CNN. The proposed approach achieved a mean average precision (mAP) of 76.6% at the frame-based and 83.5% at the video-based measurement on the new large-scale ICVL video surveillance dataset that the authors introduce and make available to the community with this paper. Extensive experiments on the benchmark KTH dataset demonstrate that the proposed approach achieved better performance, which in turn boosts the action recognition performance over the state-of-the-art. The action detection model can run at around 25 fps on the ICVL and more than 80 fps on the KTH dataset, which is suitable for real-time surveillance applications.