 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXFormer: Fast and Accurate Monocular 3D Body Capture
May 18, 2023We present XFormer, a novel human mesh and motion capture method that achieves real-time performance on consumer CPUs given only monocular images as input. The proposed network architecture contains two branches: a keypoint branch that estimates 3D human mesh vertices given 2D keypoints, and an image branch that makes predictions directly from the RGB image features. At the core of our method is a cross-modal transformer block that allows information to flow across these two branches by modeling the attention between 2D keypoint coordinates and image spatial features. Our architecture is smartly designed, which enables us to train on various types of datasets including images with 2D/3D annotations, images with 3D pseudo labels, and motion capture datasets that do not have associated images. This effectively improves the accuracy and generalization ability of our system. Built on a lightweight backbone (MobileNetV3), our method runs blazing fast (over 30fps on a single CPU core) and still yields competitive accuracy. Furthermore, with an HRNet backbone, XFormer delivers state-of-the-art performance on Huamn3.6 and 3DPW datasets.
Mixture separability loss in a deep convolutional network for image classification
Jun 16, 2019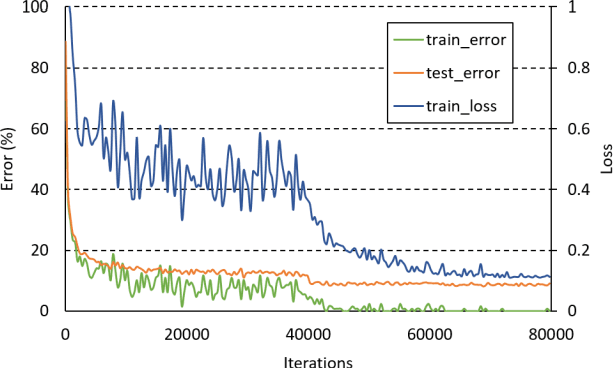

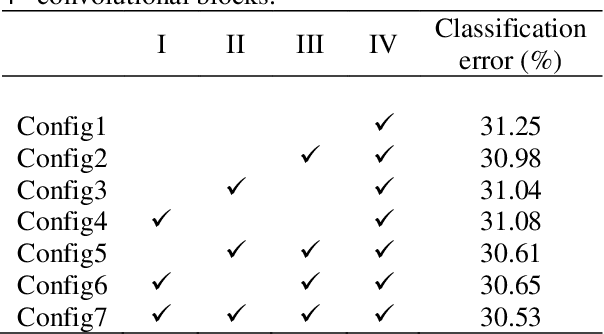
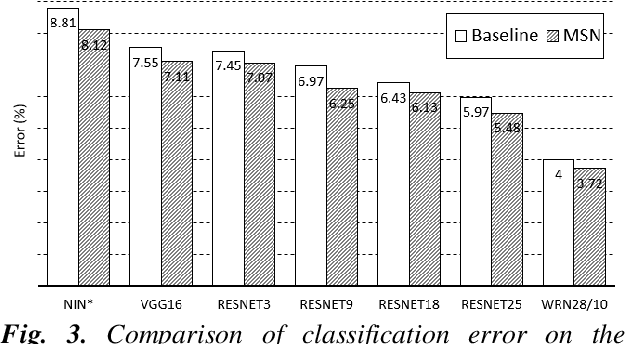
In machine learning, the cost function is crucial because it measures how good or bad a system is. In image classification, well-known networks only consider modifying the network structures and applying cross-entropy loss at the end of the network. However, using only cross-entropy loss causes a network to stop updating weights when all training images are correctly classified. This is the problem of the early saturation. This paper proposes a novel cost function, called mixture separability loss (MSL), which updates the weights of the network even when most of the training images are accurately predicted. MSL consists of between-class and within-class loss. Between-class loss maximizes the differences between inter-class images, whereas within-class loss minimizes the similarities between intra-class images. We designed the proposed loss function to attach to different convolutional layers in the network in order to utilize intermediate feature maps. Experiments show that a network with MSL deepens the learning process and obtains promising results with some public datasets, such as Street View House Number (SVHN), Canadian Institute for Advanced Research (CIFAR), and our self-collected Inha Computer Vision Lab (ICVL) gender dataset.
Deep CT to MR Synthesis using Paired and Unpaired Data
Sep 03, 2018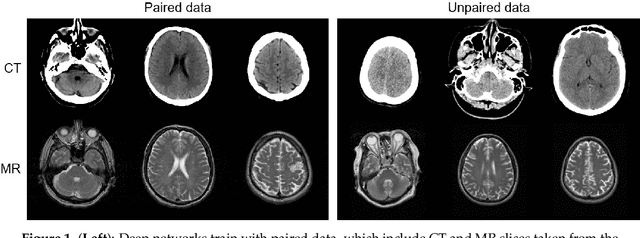
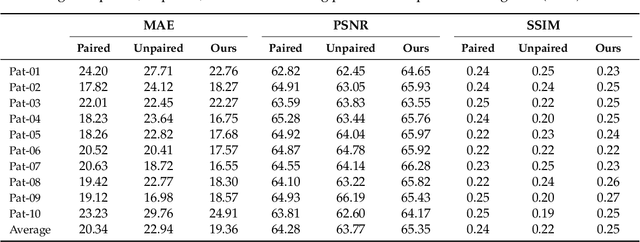
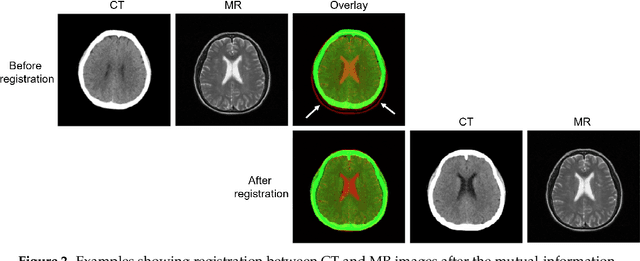
MR imaging will play a very important role in radiotherapy treatment planning for segmentation of tumor volumes and organs. However, the use of MR-based radiotherapy is limited because of the high cost and the increased use of metal implants such as cardiac pacemakers and artificial joints in aging society. To improve the accuracy of CT-based radiotherapy planning, we propose a synthetic approach that translates a CT image into an MR image using paired and unpaired training data. In contrast to the current synthetic methods for medical images, which depend on sparse pairwise-aligned data or plentiful unpaired data, the proposed approach alleviates the rigid registration challenge of paired training and overcomes the context-misalignment problem of the unpaired training. A generative adversarial network was trained to transform 2D brain CT image slices into 2D brain MR image slices, combining adversarial loss, dual cycle-consistent loss, and voxel-wise loss. The experiments were analyzed using CT and MR images of 202 patients. Qualitative and quantitative comparisons against independent paired training and unpaired training methods demonstrate the superiority of our approach.
Real-Time Action Detection in Video Surveillance using Sub-Action Descriptor with Multi-CNN
Oct 10, 2017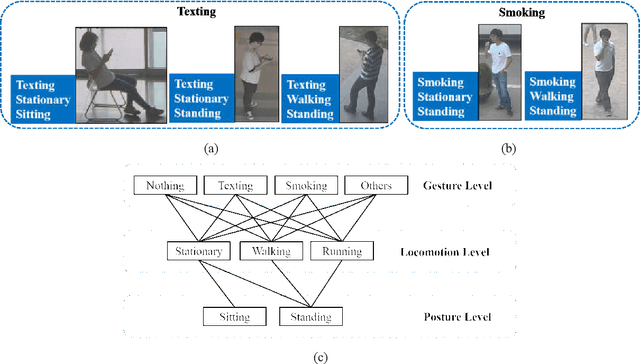

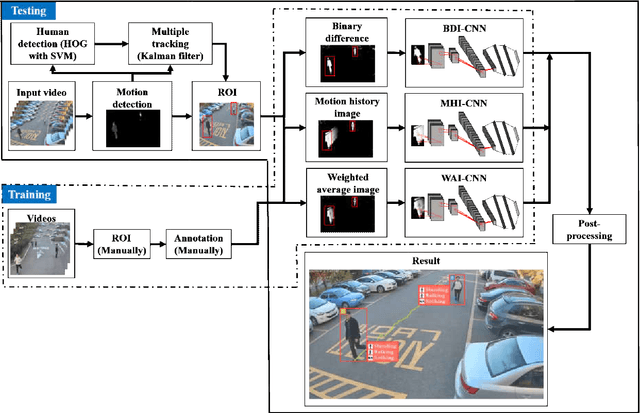
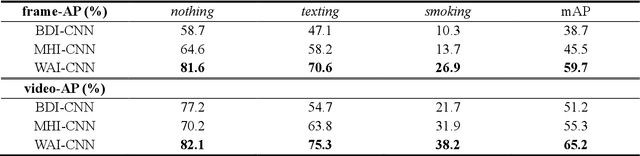
When we say a person is texting, can you tell the person is walking or sitting? Emphatically, no. In order to solve this incomplete representation problem, this paper presents a sub-action descriptor for detailed action detection. The sub-action descriptor consists of three levels: the posture, the locomotion, and the gesture level. The three levels give three sub-action categories for one action to address the representation problem. The proposed action detection model simultaneously localizes and recognizes the actions of multiple individuals in video surveillance using appearance-based temporal features with multi-CNN. The proposed approach achieved a mean average precision (mAP) of 76.6% at the frame-based and 83.5% at the video-based measurement on the new large-scale ICVL video surveillance dataset that the authors introduce and make available to the community with this paper. Extensive experiments on the benchmark KTH dataset demonstrate that the proposed approach achieved better performance, which in turn boosts the action recognition performance over the state-of-the-art. The action detection model can run at around 25 fps on the ICVL and more than 80 fps on the KTH dataset, which is suitable for real-time surveillance applications.