 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHALM: Building a Knowledge Graph from Scratch by Prompting Humans and a Language Model
Oct 11, 2023



Despite the remarkable progress in natural language understanding with pretrained Transformers, neural language models often do not handle commonsense knowledge well. Toward commonsense-aware models, there have been attempts to obtain knowledge, ranging from automatic acquisition to crowdsourcing. However, it is difficult to obtain a high-quality knowledge base at a low cost, especially from scratch. In this paper, we propose PHALM, a method of building a knowledge graph from scratch, by prompting both crowdworkers and a large language model (LLM). We used this method to build a Japanese event knowledge graph and trained Japanese commonsense generation models. Experimental results revealed the acceptability of the built graph and inferences generated by the trained models. We also report the difference in prompting humans and an LLM. Our code, data, and models are available at github.com/nlp-waseda/comet-atomic-ja.
Building a Personalized Dialogue System with Prompt-Tuning
Jun 11, 2022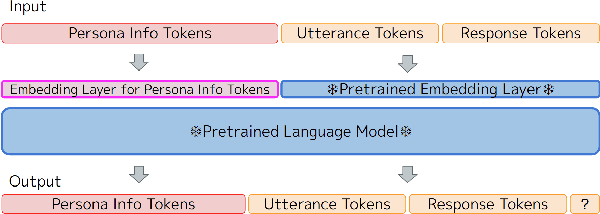
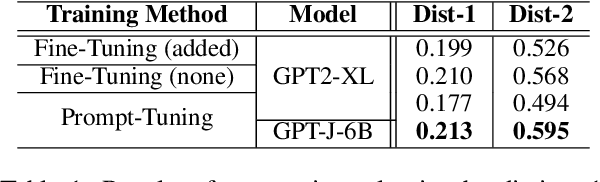
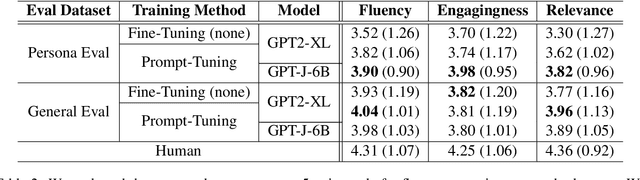
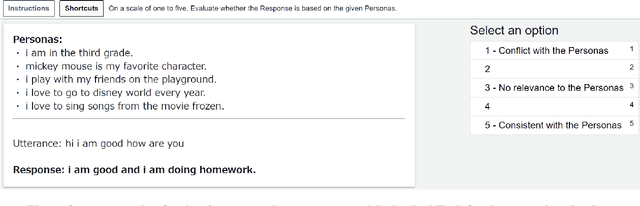
Dialogue systems without consistent responses are not fascinating. In this study, we build a dialogue system that can respond based on a given character setting (persona) to bring consistency. Considering the trend of the rapidly increasing scale of language models, we propose an approach that uses prompt-tuning, which has low learning costs, on pre-trained large-scale language models. The results of automatic and manual evaluations in English and Japanese show that it is possible to build a dialogue system with more natural and personalized responses using less computational resources than fine-tuning.
Which Strategies Matter for Noisy Label Classification? Insight into Loss and Uncertainty
Aug 14, 2020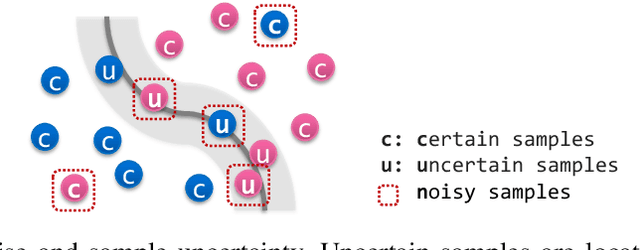
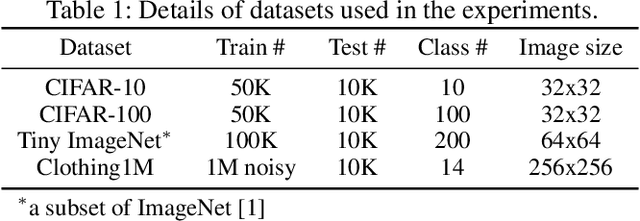
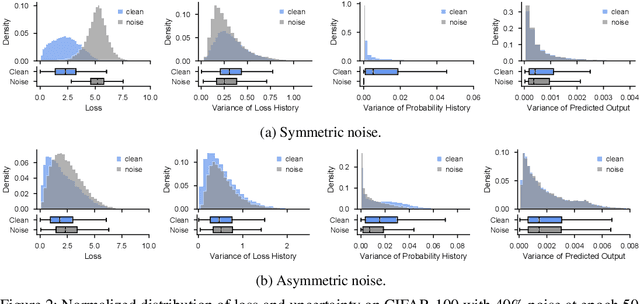
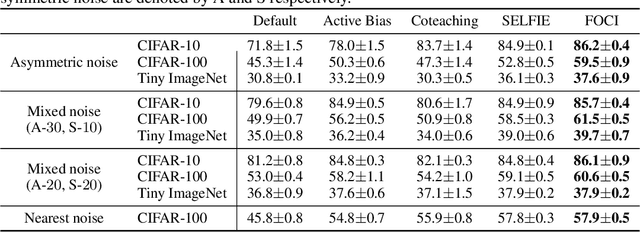
Label noise is a critical factor that degrades the generalization performance of deep neural networks, thus leading to severe issues in real-world problems. Existing studies have employed strategies based on either loss or uncertainty to address noisy labels, and ironically some strategies contradict each other: emphasizing or discarding uncertain samples or concentrating on high or low loss samples. To elucidate how opposing strategies can enhance model performance and offer insights into training with noisy labels, we present analytical results on how loss and uncertainty values of samples change throughout the training process. From the in-depth analysis, we design a new robust training method that emphasizes clean and informative samples, while minimizing the influence of noise using both loss and uncertainty. We demonstrate the effectiveness of our method with extensive experiments on synthetic and real-world datasets for various deep learning models. The results show that our method significantly outperforms other state-of-the-art methods and can be used generally regardless of neural network architectures.
Real-Time Action Detection in Video Surveillance using Sub-Action Descriptor with Multi-CNN
Oct 10, 2017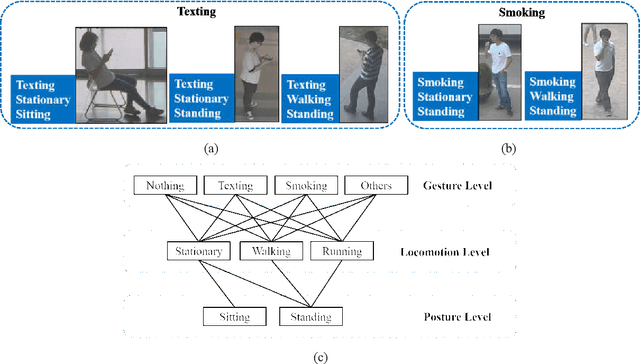

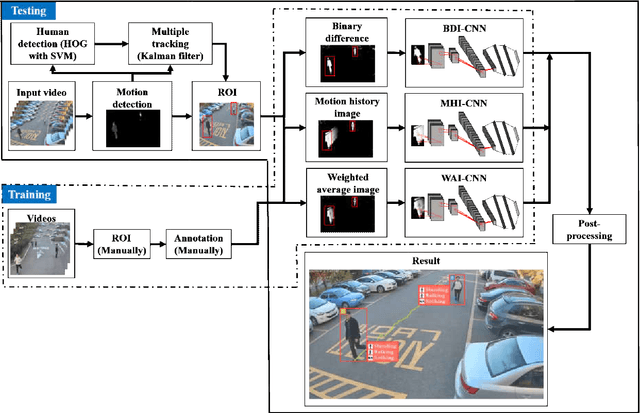
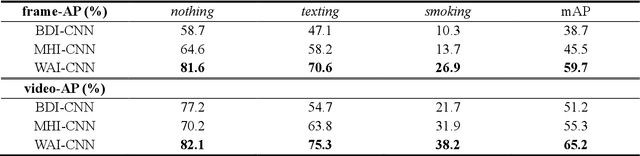
When we say a person is texting, can you tell the person is walking or sitting? Emphatically, no. In order to solve this incomplete representation problem, this paper presents a sub-action descriptor for detailed action detection. The sub-action descriptor consists of three levels: the posture, the locomotion, and the gesture level. The three levels give three sub-action categories for one action to address the representation problem. The proposed action detection model simultaneously localizes and recognizes the actions of multiple individuals in video surveillance using appearance-based temporal features with multi-CNN. The proposed approach achieved a mean average precision (mAP) of 76.6% at the frame-based and 83.5% at the video-based measurement on the new large-scale ICVL video surveillance dataset that the authors introduce and make available to the community with this paper. Extensive experiments on the benchmark KTH dataset demonstrate that the proposed approach achieved better performance, which in turn boosts the action recognition performance over the state-of-the-art. The action detection model can run at around 25 fps on the ICVL and more than 80 fps on the KTH dataset, which is suitable for real-time surveillance applications.