 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgee-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce
Jul 01, 2022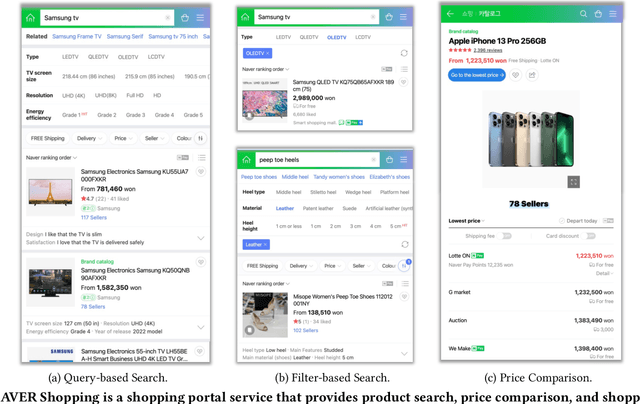
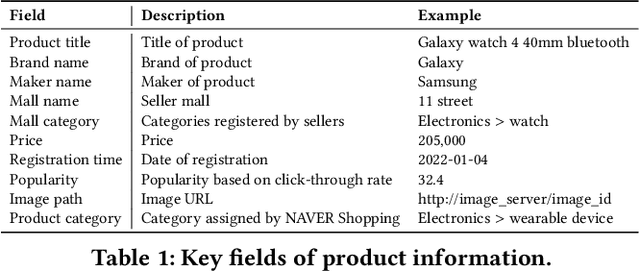
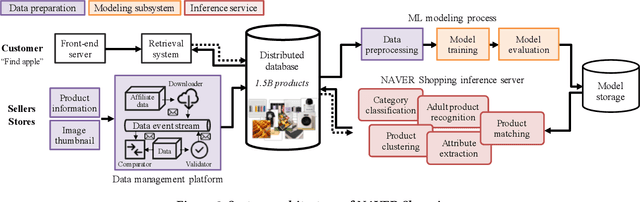
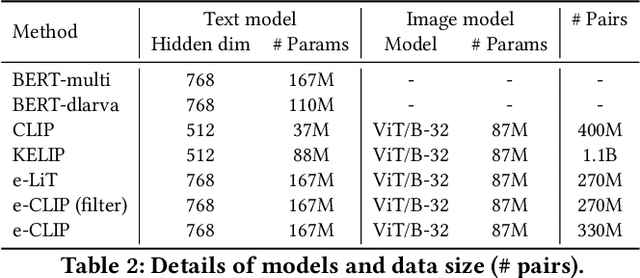
Understanding vision and language representations of product content is vital for search and recommendation applications in e-commerce. As a backbone for online shopping platforms and inspired by the recent success in representation learning research, we propose a contrastive learning framework that aligns language and visual models using unlabeled raw product text and images. We present techniques we used to train large-scale representation learning models and share solutions that address domain-specific challenges. We study the performance using our pre-trained model as backbones for diverse downstream tasks, including category classification, attribute extraction, product matching, product clustering, and adult product recognition. Experimental results show that our proposed method outperforms the baseline in each downstream task regarding both single modality and multiple modalities.
FedRN: Exploiting k-Reliable Neighbors Towards Robust Federated Learning
May 03, 2022
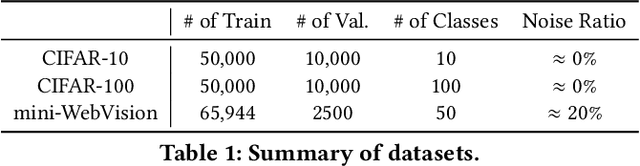
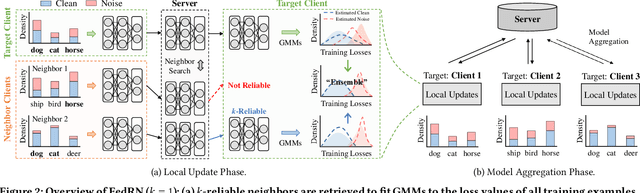
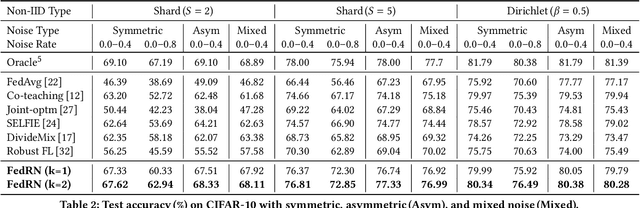
Robustness is becoming another important challenge of federated learning in that the data collection process in each client is naturally accompanied by noisy labels. However, it is far more complex and challenging owing to varying levels of data heterogeneity and noise over clients, which exacerbates the client-to-client performance discrepancy. In this work, we propose a robust federated learning method called FedRN, which exploits k-reliable neighbors with high data expertise or similarity. Our method helps mitigate the gap between low- and high-performance clients by training only with a selected set of clean examples, identified by their ensembled mixture models. We demonstrate the superiority of FedRN via extensive evaluations on three real-world or synthetic benchmark datasets. Compared with existing robust training methods, the results show that FedRN significantly improves the test accuracy in the presence of noisy labels.
Which Strategies Matter for Noisy Label Classification? Insight into Loss and Uncertainty
Aug 14, 2020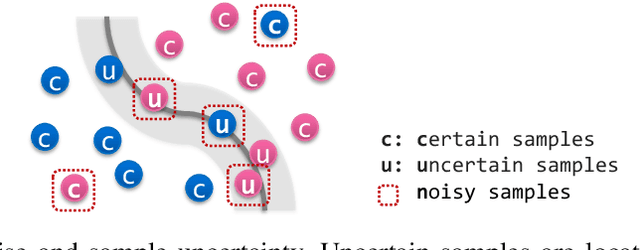
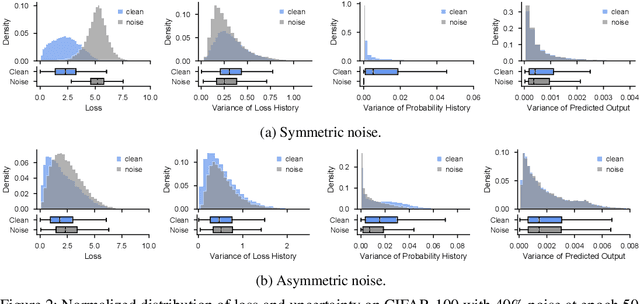
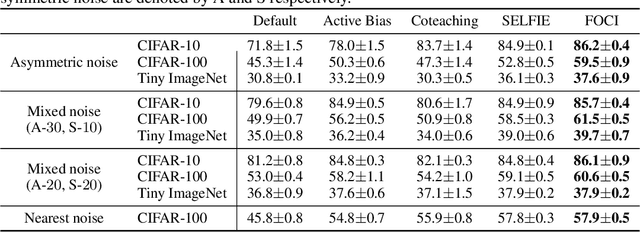
Label noise is a critical factor that degrades the generalization performance of deep neural networks, thus leading to severe issues in real-world problems. Existing studies have employed strategies based on either loss or uncertainty to address noisy labels, and ironically some strategies contradict each other: emphasizing or discarding uncertain samples or concentrating on high or low loss samples. To elucidate how opposing strategies can enhance model performance and offer insights into training with noisy labels, we present analytical results on how loss and uncertainty values of samples change throughout the training process. From the in-depth analysis, we design a new robust training method that emphasizes clean and informative samples, while minimizing the influence of noise using both loss and uncertainty. We demonstrate the effectiveness of our method with extensive experiments on synthetic and real-world datasets for various deep learning models. The results show that our method significantly outperforms other state-of-the-art methods and can be used generally regardless of neural network architectures.
Graphs, Entities, and Step Mixture
May 18, 2020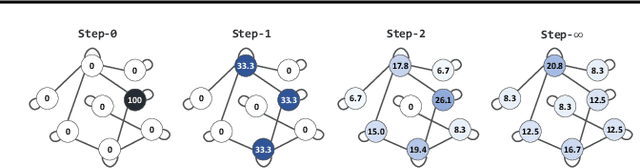
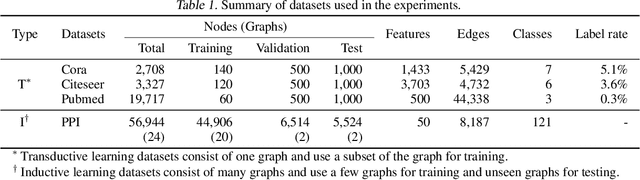
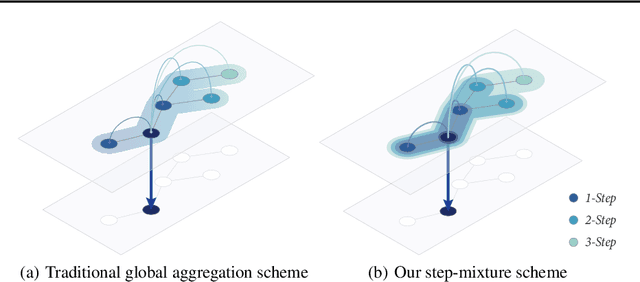
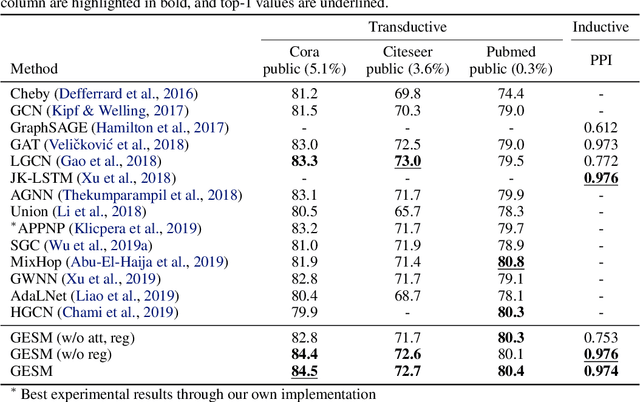
Existing approaches for graph neural networks commonly suffer from the oversmoothing issue, regardless of how neighborhoods are aggregated. Most methods also focus on transductive scenarios for fixed graphs, leading to poor generalization for unseen graphs. To address these issues, we propose a new graph neural network that considers both edge-based neighborhood relationships and node-based entity features, i.e. Graph Entities with Step Mixture via random walk (GESM). GESM employs a mixture of various steps through random walk to alleviate the oversmoothing problem, attention to dynamically reflect interrelations depending on node information, and structure-based regularization to enhance embedding representation. With intensive experiments, we show that the proposed GESM achieves state-of-the-art or comparable performances on eight benchmark graph datasets comprising transductive and inductive learning tasks. Furthermore, we empirically demonstrate the significance of considering global information.