 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRN: Exploiting k-Reliable Neighbors Towards Robust Federated Learning
Paper and Code
May 03, 2022
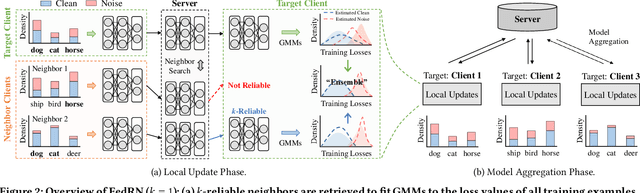
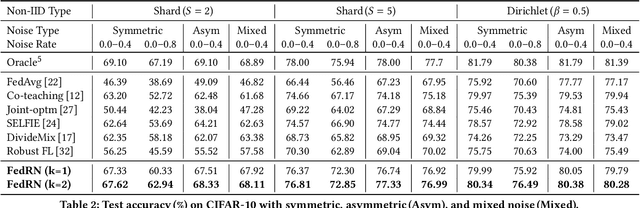
Robustness is becoming another important challenge of federated learning in that the data collection process in each client is naturally accompanied by noisy labels. However, it is far more complex and challenging owing to varying levels of data heterogeneity and noise over clients, which exacerbates the client-to-client performance discrepancy. In this work, we propose a robust federated learning method called FedRN, which exploits k-reliable neighbors with high data expertise or similarity. Our method helps mitigate the gap between low- and high-performance clients by training only with a selected set of clean examples, identified by their ensembled mixture models. We demonstrate the superiority of FedRN via extensive evaluations on three real-world or synthetic benchmark datasets. Compared with existing robust training methods, the results show that FedRN significantly improves the test accuracy in the presence of noisy labels.