 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking RAG in Long Videos: What to Retrieve and How to Use It?
Jun 11, 2026Retrieval-augmented generation is moving beyond text into long, egocentric video, where systems must select query-relevant chunks across multiple modalities and temporal granularities. Yet progress in VideoRAG is limited by two gaps: existing benchmarks allow queries to be answered without the video, obscuring retrieval errors, and prior methods apply a single modality-granularity configuration per query, ignoring chunk-level variability. We address both by introducing V-RAGBench, a benchmark of $\langle$query, evidence chunk, answer$\rangle$ triplets that enables faithful, decoupled evaluation of retrieval and generation, and CARVE, a simple method that runs parallel retrievers across configurations and employs chunk-adaptive reranking to identify the winning configuration for each chunk. Each chunk then enters the generator under its winning configuration selected during retrieval, yielding an interleaved evidence form where the chunk-level decision propagates across both stages. CARVE outperforms eight recent VideoRAG baselines, with the chunks supplied to the generator interleaving multiple configurations rather than sharing a single one, a behavior unattainable by query-level methods.
SoCRATES: Towards Reliable Automated Evaluation of Proactive LLM Mediation across Domains and Socio-cognitive Variations
Jun 04, 2026Evaluating LLM mediators remains challenging, as mediation unfolds as a real-time trajectory shaped by disputants' shifting emotions, intentions, and context. Existing testbeds rely on a few expert-authored domains, vary mainly strategic posture, and score every turn against every topic, introducing off-topic noise. We introduce SoCRATES, a benchmark for evaluating proactive LLM mediators in realistic, multi-domain testbeds. It constructs scenarios from real conflicts through an agentic pipeline across eight domains, probes five socio-cognitive adaptation axes (strategic posture, party composition, history length, emotional reactivity, and cultural identity), and scores each topic only on the turns that advance it via a topic-localized evaluator. The evaluator reaches 0.82 alignment with human experts, more than doubling a per-turn baseline. Benchmarking eight frontier LLMs, we find that even the strongest mediator closes only about a third of the unmediated consensus gap under diverse and realistic testbeds, with performance varying sharply by socio-cognitive axis, highlighting that progress lies in social adaptation to diverse conditions.
Quantile-Free Uncertainty Quantification in Graph Neural Networks
May 06, 2026Uncertainty quantification (UQ) in graph neural networks (GNNs) is crucial in high-stakes domains but remains a significant challenge. In graph settings, message passing often relies on strong assumptions such as exchangeability, which are rarely satisfied in practice. Moreover, achieving reliable UQ typically requires costly resampling or post-hoc calibration. To address these issues, we introduce Quantile-free Prediction Interval GNN (QpiGNN), a framework that builds on quantile regression (QR) to enable GNN-based UQ by directly optimizing coverage and interval width without requiring quantile inputs or post-processing. QpiGNN employs a dual-head architecture that decouples prediction and uncertainty, and is trained with label-only supervision through a quantile-free joint loss. This design allows efficient training and yields robust prediction intervals, with theoretical guarantees of asymptotic coverage and near-optimal width under mild assumptions. Experiments on 19 synthetic and real-world benchmarks show QpiGNN achieves average 22\% higher coverage and 50\% narrower intervals than baselines, while ensuring efficiency and robustness to noise and structural shifts.
Distilling Long-CoT Reasoning through Collaborative Step-wise Multi-Teacher Decoding
May 04, 2026Distilling large reasoning models is essential for making Long-CoT reasoning practical, as full-scale inference remains computationally prohibitive. Existing curation-based approaches select complete reasoning traces post-hoc, overlooking collaboration among heterogeneous teachers and lacking dynamic exploration, which leads to redundant sampling and missed complementary reasoning. We introduce CoRD, a collaborative multi-teacher decoding framework that performs step-wise reasoning synthesis guided by predictive perplexity-based scoring and beam search. This enables heterogeneous LRMs to jointly construct coherent reasoning trajectories while efficiently preserving diverse, high-potential hypotheses. Experiments show that CoRD produces higher-quality reasoning data and achieves near teacher-level student performance with fewer, structured supervision signals, without substantial efficiency overhead. CoRD further generalizes well to out-of-domain and open-ended settings. The dataset and model are available at \href{https://github.com/DISL-Lab/CoRD}{https://github.com/DISL-Lab/CoRD}.
What Makes a Sale? Rethinking End-to-End Seller--Buyer Retail Dynamics with LLM Agents
Apr 06, 2026Evaluating retail strategies before deployment is difficult, as outcomes are determined across multiple stages, from seller-side persuasion through buyer-seller interaction to purchase decisions. However, existing retail simulators capture only partial aspects of this process and do not model cross-stage dependencies, making it difficult to assess how early decisions affect downstream outcomes. We present RetailSim, an end-to-end retail simulation framework that models this pipeline in a unified environment, explicitly designed for simulation fidelity through diverse product spaces, persona-driven agents, and multi-turn interactions. We evaluate RetailSim with a dual protocol comprising human evaluation of behavioral fidelity and meta-evaluation against real-world economic regularities, showing that it successfully reproduces key patterns such as demographic purchasing behavior, the price-demand relationship, and heterogeneous price elasticity. We further demonstrate its practical utility via decision-oriented use cases, including persona inference, seller-buyer interaction analysis, and sales strategy evaluation, showing RetailSim's potential as a controlled testbed for exploring retail strategies.
Reasoning over Video: Evaluating How MLLMs Extract, Integrate, and Reconstruct Spatiotemporal Evidence
Mar 13, 2026The growing interest in embodied agents increases the demand for spatiotemporal video understanding, yet existing benchmarks largely emphasize extractive reasoning, where answers can be explicitly presented within spatiotemporal events. It remains unclear whether multimodal large language models can instead perform abstractive spatiotemporal reasoning, which requires integrating observations over time, combining dispersed cues, and inferring implicit spatial and contextual structure. To address this gap, we formalize abstractive spatiotemporal reasoning from videos by introducing a structured evaluation taxonomy that systematically targets its core dimensions and construct a controllable, scenario-driven synthetic egocentric video dataset tailored to evaluate abstractive spatiotemporal reasoning capabilities, spanning object-, room-, and floor-plan-level scenarios. Based on this framework, we present VAEX-BENCH, a benchmark comprising five abstractive reasoning tasks together with their extractive counterparts. Our extensive experiments compare the performance of state-of-the-art MLLMs under extractive and abstractive settings, exposing their limitations on abstractive tasks and providing a fine-grained analysis of the underlying bottlenecks. The dataset will be released soon.
Completing Missing Annotation: Multi-Agent Debate for Accurate and Scalable Relevant Assessment for IR Benchmarks
Feb 06, 2026Information retrieval (IR) evaluation remains challenging due to incomplete IR benchmark datasets that contain unlabeled relevant chunks. While LLMs and LLM-human hybrid strategies reduce costly human effort, they remain prone to LLM overconfidence and ineffective AI-to-human escalation. To address this, we propose DREAM, a multi-round debate-based relevance assessment framework with LLM agents, built on opposing initial stances and iterative reciprocal critique. Through our agreement-based debate, it yields more accurate labeling for certain cases and more reliable AI-to-human escalation for uncertain ones, achieving 95.2% labeling accuracy with only 3.5% human involvement. Using DREAM, we build BRIDGE, a refined benchmark that mitigates evaluation bias and enables fairer retriever comparison by uncovering 29,824 missing relevant chunks. We then re-benchmark IR systems and extend evaluation to RAG, showing that unaddressed holes not only distort retriever rankings but also drive retrieval-generation misalignment. The relevance assessment framework is available at https: //github.com/DISL-Lab/DREAM-ICLR-26; and the BRIDGE dataset is available at https://github.com/DISL-Lab/BRIDGE-Benchmark.
Towards a Holistic and Automated Evaluation Framework for Multi-Level Comprehension of LLMs in Book-Length Contexts
Aug 27, 2025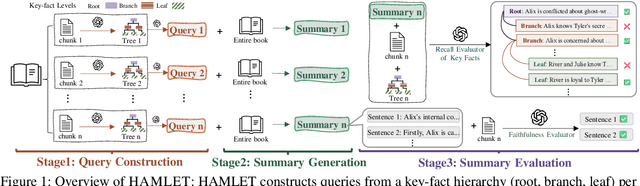
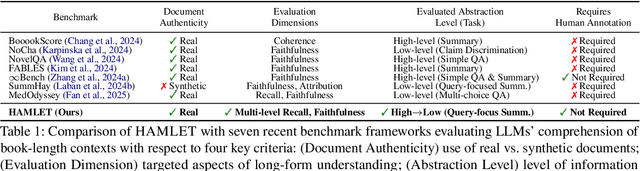


We introduce HAMLET, a holistic and automated framework for evaluating the long-context comprehension of large language models (LLMs). HAMLET structures source texts into a three-level key-fact hierarchy at root-, branch-, and leaf-levels, and employs query-focused summarization to evaluate how well models recall and faithfully represent information at each level. To validate the reliability of our fully automated pipeline, we conduct a systematic human study, showing that our automatic evaluation achieves over 90% agreement with expert human judgments, while reducing the cost by up to 25 times. HAMLET reveals that LLMs struggle with fine-grained comprehension, especially at the leaf level, and are sensitive to positional effects like the lost-in-the-middle. Analytical queries pose greater challenges than narrative ones, and consistent performance gaps emerge between open-source and proprietary models, as well as across model scales. Our code and dataset are publicly available at https://github.com/DISL-Lab/HAMLET.
References Indeed Matter? Reference-Free Preference Optimization for Conversational Query Reformulation
May 10, 2025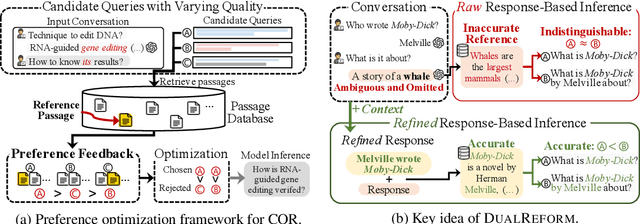
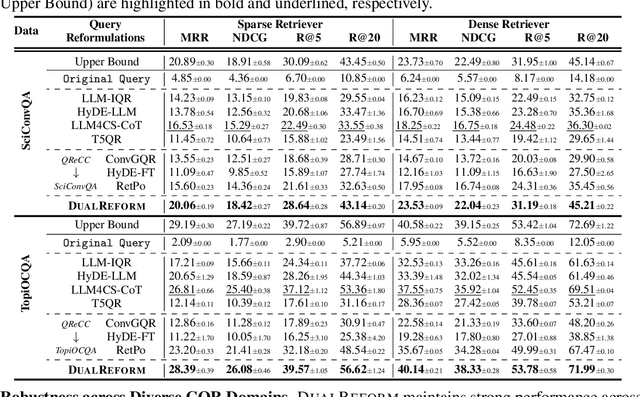
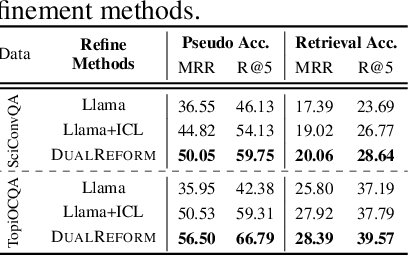
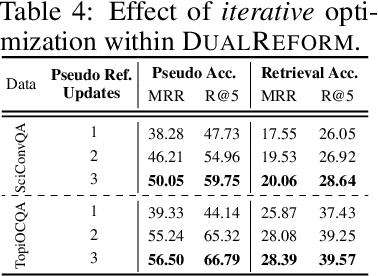
Conversational query reformulation (CQR) has become indispensable for improving retrieval in dialogue-based applications. However, existing approaches typically rely on reference passages for optimization, which are impractical to acquire in real-world scenarios. To address this limitation, we introduce a novel reference-free preference optimization framework DualReform that generates pseudo reference passages from commonly-encountered conversational datasets containing only queries and responses. DualReform attains this goal through two key innovations: (1) response-based inference, where responses serve as proxies to infer pseudo reference passages, and (2) response refinement via the dual-role of CQR, where a CQR model refines responses based on the shared objectives between response refinement and CQR. Despite not relying on reference passages, DualReform achieves 96.9--99.1% of the retrieval accuracy attainable only with reference passages and surpasses the state-of-the-art method by up to 31.6%.
Rethinking LLM-Based Recommendations: A Query Generation-Based, Training-Free Approach
Apr 16, 2025Existing large language model LLM-based recommendation methods face several challenges, including inefficiency in handling large candidate pools, sensitivity to item order within prompts ("lost in the middle" phenomenon) poor scalability, and unrealistic evaluation due to random negative sampling. To address these issues, we propose a Query-to-Recommendation approach that leverages LLMs to generate personalized queries for retrieving relevant items from the entire candidate pool, eliminating the need for candidate pre-selection. This method can be integrated into an ID-based recommendation system without additional training, enhances recommendation performance and diversity through LLMs' world knowledge, and performs well even for less popular item groups. Experiments on three datasets show up to 57 percent improvement, with an average gain of 31 percent, demonstrating strong zero-shot performance and further gains when ensembled with existing models.