 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment-driven Structural Induction and Semantic Alignment for Heterogeneous Tabular Representation
Jun 01, 2026Real-world domains often contain heterogeneous tables whose headers vary while their underlying attribute semantics are shared, making it difficult to induce domain-specialized semantics from table-local evidence alone. Existing encoders model parts of this problem, but often underuse column-level value distributions and apply uniform objectives across attributes with different semantic roles. We propose NAVI, a segment-centric pretraining framework that treats each header-value pair as the unit for aggregating schema-level structural evidence and column-level distributional evidence. We realize this design through Masked Segment Modeling and Entropy-driven Segment Alignment, which jointly enforce structured header-value coupling and semantic alignment across stable and instance-specific attributes. Experiments on heterogeneous in-domain tables show improved reconstruction, semantic consistency, and downstream utility across evaluation settings overall.
Back to the Future: Look-ahead Augmentation and Parallel Self-Refinement for Time Series Forecasting
Feb 02, 2026Long-term time series forecasting (LTSF) remains challenging due to the trade-off between parallel efficiency and sequential modeling of temporal coherence. Direct multi-step forecasting (DMS) methods enable fast, parallel prediction of all future horizons but often lose temporal consistency across steps, while iterative multi-step forecasting (IMS) preserves temporal dependencies at the cost of error accumulation and slow inference. To bridge this gap, we propose Back to the Future (BTTF), a simple yet effective framework that enhances forecasting stability through look-ahead augmentation and self-corrective refinement. Rather than relying on complex model architectures, BTTF revisits the fundamental forecasting process and refines a base model by ensembling the second-stage models augmented with their initial predictions. Despite its simplicity, our approach consistently improves long-horizon accuracy and mitigates the instability of linear forecasting models, achieving accuracy gains of up to 58% and demonstrating stable improvements even when the first-stage model is trained under suboptimal conditions. These results suggest that leveraging model-generated forecasts as augmentation can be a simple yet powerful way to enhance long-term prediction, even without complex architectures.
CREAM: Continual Retrieval on Dynamic Streaming Corpora with Adaptive Soft Memory
Jan 06, 2026Information retrieval (IR) in dynamic data streams is emerging as a challenging task, as shifts in data distribution degrade the performance of AI-powered IR systems. To mitigate this issue, memory-based continual learning has been widely adopted for IR. However, existing methods rely on a fixed set of queries with ground-truth relevant documents, which limits generalization to unseen queries and documents, making them impractical for real-world applications. To enable more effective learning with unseen topics of a new corpus without ground-truth labels, we propose CREAM, a self-supervised framework for memory-based continual retrieval. CREAM captures the evolving semantics of streaming queries and documents into dynamically structured soft memory and leverages it to adapt to both seen and unseen topics in an unsupervised setting. We realize this through three key techniques: fine-grained similarity estimation, regularized cluster prototyping, and stratified coreset sampling. Experiments on two benchmark datasets demonstrate that CREAM exhibits superior adaptability and retrieval accuracy, outperforming the strongest method in a label-free setting by 27.79\% in Success@5 and 44.5\% in Recall@10 on average, and achieving performance comparable to or even exceeding that of supervised methods.
Improving Scientific Document Retrieval with Academic Concept Index
Jan 02, 2026Adapting general-domain retrievers to scientific domains is challenging due to the scarcity of large-scale domain-specific relevance annotations and the substantial mismatch in vocabulary and information needs. Recent approaches address these issues through two independent directions that leverage large language models (LLMs): (1) generating synthetic queries for fine-tuning, and (2) generating auxiliary contexts to support relevance matching. However, both directions overlook the diverse academic concepts embedded within scientific documents, often producing redundant or conceptually narrow queries and contexts. To address this limitation, we introduce an academic concept index, which extracts key concepts from papers and organizes them guided by an academic taxonomy. This structured index serves as a foundation for improving both directions. First, we enhance the synthetic query generation with concept coverage-based generation (CCQGen), which adaptively conditions LLMs on uncovered concepts to generate complementary queries with broader concept coverage. Second, we strengthen the context augmentation with concept-focused auxiliary contexts (CCExpand), which leverages a set of document snippets that serve as concise responses to the concept-aware CCQGen queries. Extensive experiments show that incorporating the academic concept index into both query generation and context augmentation leads to higher-quality queries, better conceptual alignment, and improved retrieval performance.
References Indeed Matter? Reference-Free Preference Optimization for Conversational Query Reformulation
May 10, 2025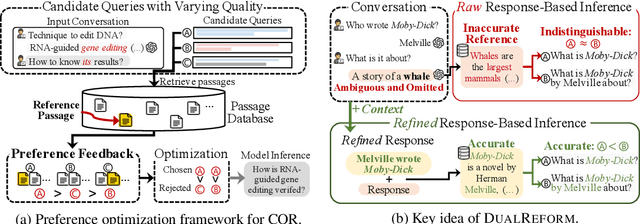
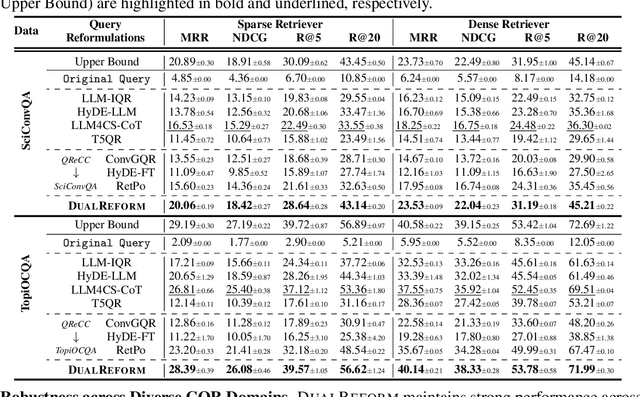
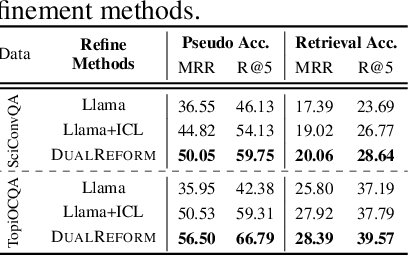
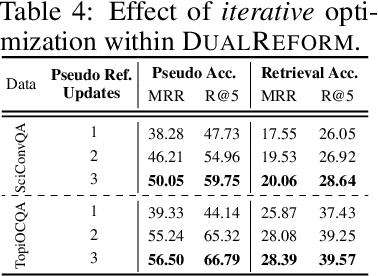
Conversational query reformulation (CQR) has become indispensable for improving retrieval in dialogue-based applications. However, existing approaches typically rely on reference passages for optimization, which are impractical to acquire in real-world scenarios. To address this limitation, we introduce a novel reference-free preference optimization framework DualReform that generates pseudo reference passages from commonly-encountered conversational datasets containing only queries and responses. DualReform attains this goal through two key innovations: (1) response-based inference, where responses serve as proxies to infer pseudo reference passages, and (2) response refinement via the dual-role of CQR, where a CQR model refines responses based on the shared objectives between response refinement and CQR. Despite not relying on reference passages, DualReform achieves 96.9--99.1% of the retrieval accuracy attainable only with reference passages and surpasses the state-of-the-art method by up to 31.6%.
Why These Documents? Explainable Generative Retrieval with Hierarchical Category Paths
Nov 08, 2024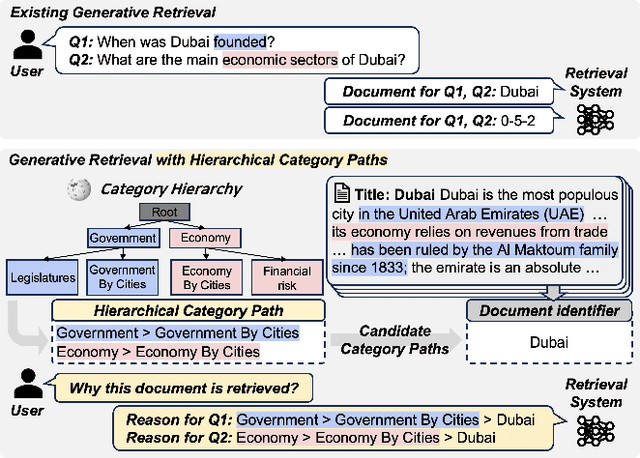
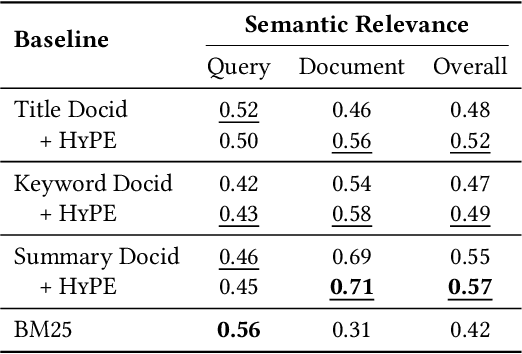
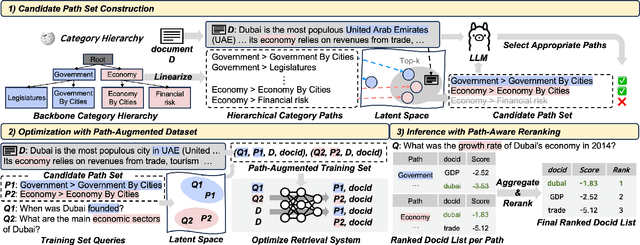
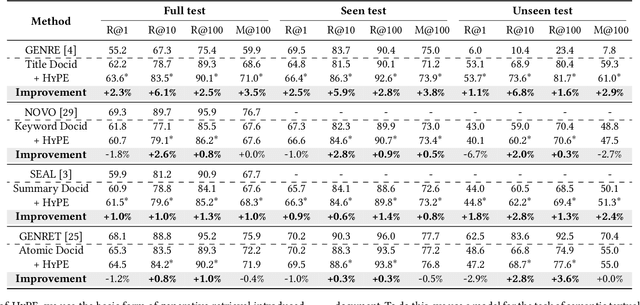
Generative retrieval has recently emerged as a new alternative of traditional information retrieval approaches. However, existing generative retrieval methods directly decode docid when a query is given, making it impossible to provide users with explanations as an answer for "Why this document is retrieved?". To address this limitation, we propose Hierarchical Category Path-Enhanced Generative Retrieval(HyPE), which enhances explainability by generating hierarchical category paths step-by-step before decoding docid. HyPE leverages hierarchical category paths as explanation, progressing from broad to specific semantic categories. This approach enables diverse explanations for the same document depending on the query by using shared category paths between the query and the document, and provides reasonable explanation by reflecting the document's semantic structure through a coarse-to-fine manner. HyPE constructs category paths with external high-quality semantic hierarchy, leverages LLM to select appropriate candidate paths for each document, and optimizes the generative retrieval model with path-augmented dataset. During inference, HyPE utilizes path-aware reranking strategy to aggregate diverse topic information, allowing the most relevant documents to be prioritized in the final ranked list of docids. Our extensive experiments demonstrate that HyPE not only offers a high level of explainability but also improves the retrieval performance in the document retrieval task.
Online Drift Detection with Maximum Concept Discrepancy
Jul 07, 2024Continuous learning from an immense volume of data streams becomes exceptionally critical in the internet era. However, data streams often do not conform to the same distribution over time, leading to a phenomenon called concept drift. Since a fixed static model is unreliable for inferring concept-drifted data streams, establishing an adaptive mechanism for detecting concept drift is crucial. Current methods for concept drift detection primarily assume that the labels or error rates of downstream models are given and/or underlying statistical properties exist in data streams. These approaches, however, struggle to address high-dimensional data streams with intricate irregular distribution shifts, which are more prevalent in real-world scenarios. In this paper, we propose MCD-DD, a novel concept drift detection method based on maximum concept discrepancy, inspired by the maximum mean discrepancy. Our method can adaptively identify varying forms of concept drift by contrastive learning of concept embeddings without relying on labels or statistical properties. With thorough experiments under synthetic and real-world scenarios, we demonstrate that the proposed method outperforms existing baselines in identifying concept drifts and enables qualitative analysis with high explainability.
SCStory: Self-supervised and Continual Online Story Discovery
Nov 27, 2023We present a framework SCStory for online story discovery, that helps people digest rapidly published news article streams in real-time without human annotations. To organize news article streams into stories, existing approaches directly encode the articles and cluster them based on representation similarity. However, these methods yield noisy and inaccurate story discovery results because the generic article embeddings do not effectively reflect the story-indicative semantics in an article and cannot adapt to the rapidly evolving news article streams. SCStory employs self-supervised and continual learning with a novel idea of story-indicative adaptive modeling of news article streams. With a lightweight hierarchical embedding module that first learns sentence representations and then article representations, SCStory identifies story-relevant information of news articles and uses them to discover stories. The embedding module is continuously updated to adapt to evolving news streams with a contrastive learning objective, backed up by two unique techniques, confidence-aware memory replay and prioritized-augmentation, employed for label absence and data scarcity problems. Thorough experiments on real and the latest news data sets demonstrate that SCStory outperforms existing state-of-the-art algorithms for unsupervised online story discovery.
One Size Fits All for Semantic Shifts: Adaptive Prompt Tuning for Continual Learning
Nov 18, 2023



In real-world continual learning scenarios, tasks often exhibit intricate and unpredictable semantic shifts, posing challenges for fixed prompt management strategies. We identify the inadequacy of universal and specific prompting in handling these dynamic shifts. Universal prompting is ineffective for tasks with abrupt semantic changes, while specific prompting struggles with overfitting under mild semantic shifts. To overcome these limitations, we propose an adaptive prompting approach that tailors minimal yet sufficient prompts based on the task semantics. Our methodology, SemPrompt, incorporates a two-level semantic grouping process: macroscopic semantic assignment and microscopic semantic refinement. This process ensures optimal prompt utilization for varying task semantics, improving the efficiency and effectiveness of learning in real-world CL settings. Our experimental results demonstrate that SemPrompt consistently outperforms existing methods in adapting to diverse semantic shifts in tasks.
Unsupervised Story Discovery from Continuous News Streams via Scalable Thematic Embedding
May 04, 2023



Unsupervised discovery of stories with correlated news articles in real-time helps people digest massive news streams without expensive human annotations. A common approach of the existing studies for unsupervised online story discovery is to represent news articles with symbolic- or graph-based embedding and incrementally cluster them into stories. Recent large language models are expected to improve the embedding further, but a straightforward adoption of the models by indiscriminately encoding all information in articles is ineffective to deal with text-rich and evolving news streams. In this work, we propose a novel thematic embedding with an off-the-shelf pretrained sentence encoder to dynamically represent articles and stories by considering their shared temporal themes. To realize the idea for unsupervised online story discovery, a scalable framework USTORY is introduced with two main techniques, theme- and time-aware dynamic embedding and novelty-aware adaptive clustering, fueled by lightweight story summaries. A thorough evaluation with real news data sets demonstrates that USTORY achieves higher story discovery performances than baselines while being robust and scalable to various streaming settings.