 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferences Indeed Matter? Reference-Free Preference Optimization for Conversational Query Reformulation
May 10, 2025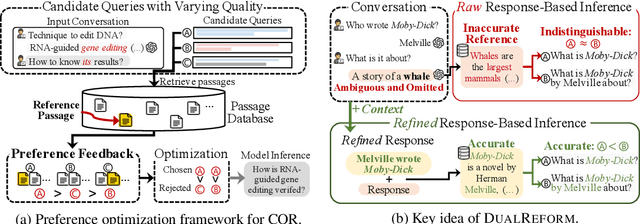
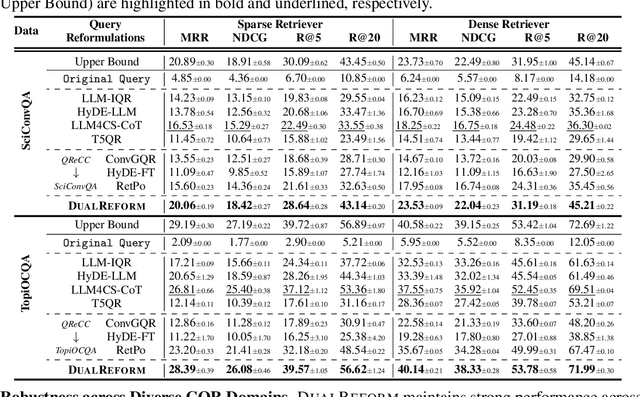
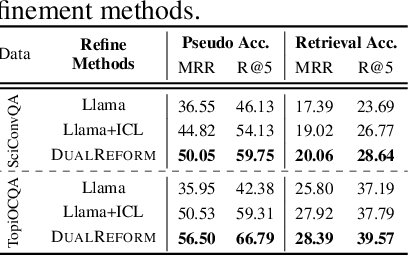
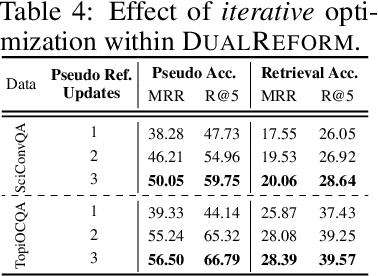
Conversational query reformulation (CQR) has become indispensable for improving retrieval in dialogue-based applications. However, existing approaches typically rely on reference passages for optimization, which are impractical to acquire in real-world scenarios. To address this limitation, we introduce a novel reference-free preference optimization framework DualReform that generates pseudo reference passages from commonly-encountered conversational datasets containing only queries and responses. DualReform attains this goal through two key innovations: (1) response-based inference, where responses serve as proxies to infer pseudo reference passages, and (2) response refinement via the dual-role of CQR, where a CQR model refines responses based on the shared objectives between response refinement and CQR. Despite not relying on reference passages, DualReform achieves 96.9--99.1% of the retrieval accuracy attainable only with reference passages and surpasses the state-of-the-art method by up to 31.6%.
One Size Fits All for Semantic Shifts: Adaptive Prompt Tuning for Continual Learning
Nov 18, 2023



In real-world continual learning scenarios, tasks often exhibit intricate and unpredictable semantic shifts, posing challenges for fixed prompt management strategies. We identify the inadequacy of universal and specific prompting in handling these dynamic shifts. Universal prompting is ineffective for tasks with abrupt semantic changes, while specific prompting struggles with overfitting under mild semantic shifts. To overcome these limitations, we propose an adaptive prompting approach that tailors minimal yet sufficient prompts based on the task semantics. Our methodology, SemPrompt, incorporates a two-level semantic grouping process: macroscopic semantic assignment and microscopic semantic refinement. This process ensures optimal prompt utilization for varying task semantics, improving the efficiency and effectiveness of learning in real-world CL settings. Our experimental results demonstrate that SemPrompt consistently outperforms existing methods in adapting to diverse semantic shifts in tasks.
Meta-Query-Net: Resolving Purity-Informativeness Dilemma in Open-set Active Learning
Oct 13, 2022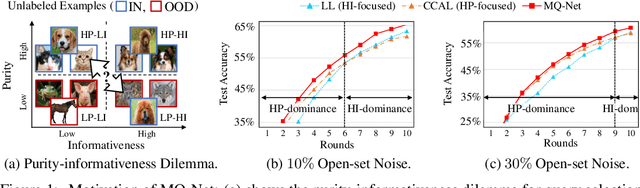
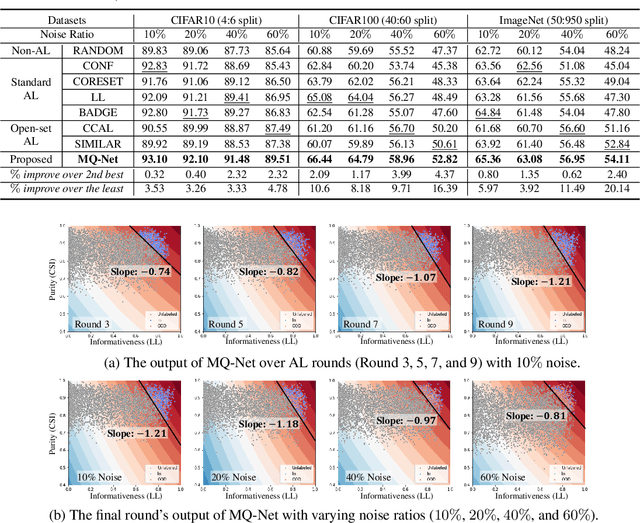
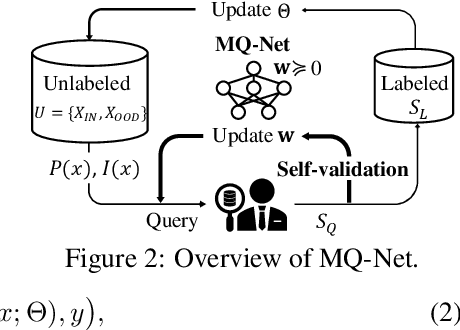
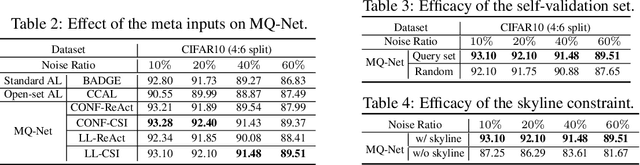
Unlabeled data examples awaiting annotations contain open-set noise inevitably. A few active learning studies have attempted to deal with this open-set noise for sample selection by filtering out the noisy examples. However, because focusing on the purity of examples in a query set leads to overlooking the informativeness of the examples, the best balancing of purity and informativeness remains an important question. In this paper, to solve this purity-informativeness dilemma in open-set active learning, we propose a novel Meta-Query-Net,(MQ-Net) that adaptively finds the best balancing between the two factors. Specifically, by leveraging the multi-round property of active learning, we train MQ-Net using a query set without an additional validation set. Furthermore, a clear dominance relationship between unlabeled examples is effectively captured by MQ-Net through a novel skyline regularization. Extensive experiments on multiple open-set active learning scenarios demonstrate that the proposed MQ-Net achieves 20.14% improvement in terms of accuracy, compared with the state-of-the-art methods.
Adaptive Model Pooling for Online Deep Anomaly Detection from a Complex Evolving Data Stream
Jun 09, 2022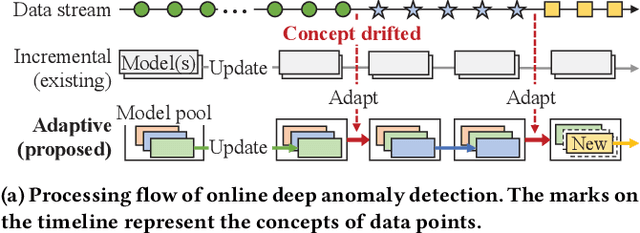
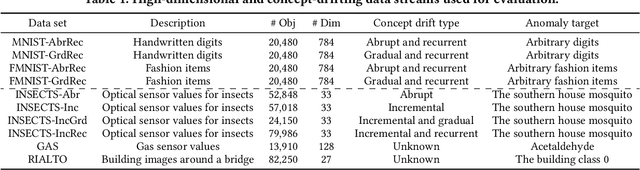

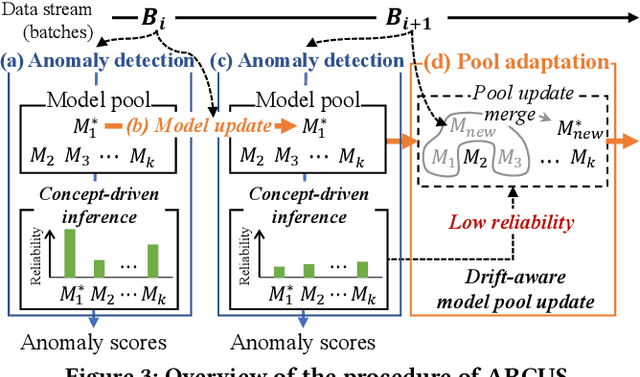
Online anomaly detection from a data stream is critical for the safety and security of many applications but is facing severe challenges due to complex and evolving data streams from IoT devices and cloud-based infrastructures. Unfortunately, existing approaches fall too short for these challenges; online anomaly detection methods bear the burden of handling the complexity while offline deep anomaly detection methods suffer from the evolving data distribution. This paper presents a framework for online deep anomaly detection, ARCUS, which can be instantiated with any autoencoder-based deep anomaly detection methods. It handles the complex and evolving data streams using an adaptive model pooling approach with two novel techniques: concept-driven inference and drift-aware model pool update; the former detects anomalies with a combination of models most appropriate for the complexity, and the latter adapts the model pool dynamically to fit the evolving data streams. In comprehensive experiments with ten data sets which are both high-dimensional and concept-drifted, ARCUS improved the anomaly detection accuracy of the streaming variants of state-of-the-art autoencoder-based methods and that of the state-of-the-art streaming anomaly detection methods by up to 22% and 37%, respectively.