 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooped Diffusion Language Models
May 25, 2026Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models for language modeling, yet the effective design of transformer architectures for MDMs remains underexplored. In this paper, we show that selectively looping the early-middle transformer layers significantly improves both training efficiency and model performance in MDMs. We call this approach LoopMDM(Looped Masked Diffusion Model), which brings two key benefits: looping layers at training-time yields a depth-scaling effect without adding parameters, while varying the number of loops at inference-time enables flexible compute scaling. Despite the simplicity, the results are striking: across multiple pre-training corpora, LoopMDM matches the performance of same-size MDMs with up to 3.3 fewer training FLOPs, while its final performance outperforms them on various reasoning benchmarks, including up to 8.5 points on GSM8K. It even surpasses deeper non-looped MDMs trained with comparable per-step compute, indicating that selective looping is more effective than naive depth scaling. Furthermore, LoopMDM can scale inference-time compute by increasing the number of loops. Adaptively adjusting the number of loops throughout the sampling process further yields additional gains in compute efficiency while maintaining performance. Lastly, with attention analysis, we provide evidence that looping is effective in MDMs by promoting interactions among masked positions. Our code and weights will be publicly released.
Raon-OpenTTS: Open Models and Data for Robust Text-to-Speech
May 20, 2026Recent advances in text-to-speech (TTS) models show impressive speech naturalness and quality, yet the role of large-scale open data in driving this progress remains underexplored. In this work, we introduce Raon-OpenTTS, an open TTS model that performs competitively with state-of-the-art closed-data TTS models, and Raon-OpenTTS-Pool, a large-scale open dataset for reproducible TTS training. Raon-OpenTTS-Pool consists of 615K hours of 240M speech segments aggregated from publicly available English speech corpora and web-sourced recordings. With a model-based filtering pipeline applied to Raon-OpenTTS-Pool, we derive Raon-OpenTTS-Core, a curated, high-quality subset of 510K hours and 194M speech segments. Using Raon-OpenTTS-Core, we train Raon-OpenTTS, a series of diffusion transformer (DiT)-based TTS models from 0.3B to 1B parameters. On multiple benchmarks, Raon-OpenTTS-1B shows comparable performance to state-of-the-art models such as Qwen3-TTS and CosyVoice 3, which are trained on several million hours of proprietary speech data. Notably, on Seed-TTS-Eval, Raon-OpenTTS-1B achieves a word error rate (WER) of 1.78% and a speaker similarity (SIM) of 0.749, ranking second on WER and first on SIM among recent open-weight TTS baselines. On CV3-Hard-EN, Raon-OpenTTS-1B achieves a WER of 6.15% and a SIM of 0.775, ranking first on both metrics. Furthermore, to support robust evaluation, we introduce Raon-OpenTTS-Eval, a structured benchmark for assessing TTS robustness across diverse acoustic conditions including clean, noisy, in-the-wild, and expressive speech. On Raon-OpenTTS-Eval, Raon-OpenTTS-1B achieves the best average WER and SIM among all evaluated models, and the second-best human preference, as measured by comparative mean opinion score (CMOS). Our data pool, filtering pipeline, training code, and checkpoints are publicly available at https://github.com/krafton-ai/RAON-OpenTTS.
VLM-SubtleBench: How Far Are VLMs from Human-Level Subtle Comparative Reasoning?
Mar 09, 2026The ability to distinguish subtle differences between visually similar images is essential for diverse domains such as industrial anomaly detection, medical imaging, and aerial surveillance. While comparative reasoning benchmarks for vision-language models (VLMs) have recently emerged, they primarily focus on images with large, salient differences and fail to capture the nuanced reasoning required for real-world applications. In this work, we introduce VLM-SubtleBench, a benchmark designed to evaluate VLMs on subtle comparative reasoning. Our benchmark covers ten difference types - Attribute, State, Emotion, Temporal, Spatial, Existence, Quantity, Quality, Viewpoint, and Action - and curate paired question-image sets reflecting these fine-grained variations. Unlike prior benchmarks restricted to natural image datasets, our benchmark spans diverse domains, including industrial, aerial, and medical imagery. Through extensive evaluation of both proprietary and open-source VLMs, we reveal systematic gaps between model and human performance across difference types and domains, and provide controlled analyses highlighting where VLMs' reasoning sharply deteriorates. Together, our benchmark and findings establish a foundation for advancing VLMs toward human-level comparative reasoning.
See and Fix the Flaws: Enabling VLMs and Diffusion Models to Comprehend Visual Artifacts via Agentic Data Synthesis
Feb 24, 2026Despite recent advances in diffusion models, AI generated images still often contain visual artifacts that compromise realism. Although more thorough pre-training and bigger models might reduce artifacts, there is no assurance that they can be completely eliminated, which makes artifact mitigation a highly crucial area of study. Previous artifact-aware methodologies depend on human-labeled artifact datasets, which are costly and difficult to scale, underscoring the need for an automated approach to reliably acquire artifact-annotated datasets. In this paper, we propose ArtiAgent, which efficiently creates pairs of real and artifact-injected images. It comprises three agents: a perception agent that recognizes and grounds entities and subentities from real images, a synthesis agent that introduces artifacts via artifact injection tools through novel patch-wise embedding manipulation within a diffusion transformer, and a curation agent that filters the synthesized artifacts and generates both local and global explanations for each instance. Using ArtiAgent, we synthesize 100K images with rich artifact annotations and demonstrate both efficacy and versatility across diverse applications. Code is available at link.
THINKSAFE: Self-Generated Safety Alignment for Reasoning Models
Jan 30, 2026Large reasoning models (LRMs) achieve remarkable performance by leveraging reinforcement learning (RL) on reasoning tasks to generate long chain-of-thought (CoT) reasoning. However, this over-optimization often prioritizes compliance, making models vulnerable to harmful prompts. To mitigate this safety degradation, recent approaches rely on external teacher distillation, yet this introduces a distributional discrepancy that degrades native reasoning. We propose ThinkSafe, a self-generated alignment framework that restores safety alignment without external teachers. Our key insight is that while compliance suppresses safety mechanisms, models often retain latent knowledge to identify harm. ThinkSafe unlocks this via lightweight refusal steering, guiding the model to generate in-distribution safety reasoning traces. Fine-tuning on these self-generated responses effectively realigns the model while minimizing distribution shift. Experiments on DeepSeek-R1-Distill and Qwen3 show ThinkSafe significantly improves safety while preserving reasoning proficiency. Notably, it achieves superior safety and comparable reasoning to GRPO, with significantly reduced computational cost. Code, models, and datasets are available at https://github.com/seanie12/ThinkSafe.git.
Active Learning for Continual Learning: Keeping the Past Alive in the Present
Jan 24, 2025



Continual learning (CL) enables deep neural networks to adapt to ever-changing data distributions. In practice, there may be scenarios where annotation is costly, leading to active continual learning (ACL), which performs active learning (AL) for the CL scenarios when reducing the labeling cost by selecting the most informative subset is preferable. However, conventional AL strategies are not suitable for ACL, as they focus solely on learning the new knowledge, leading to catastrophic forgetting of previously learned tasks. Therefore, ACL requires a new AL strategy that can balance the prevention of catastrophic forgetting and the ability to quickly learn new tasks. In this paper, we propose AccuACL, Accumulated informativeness-based Active Continual Learning, by the novel use of the Fisher information matrix as a criterion for sample selection, derived from a theoretical analysis of the Fisher-optimality preservation properties within the framework of ACL, while also addressing the scalability issue of Fisher information-based AL. Extensive experiments demonstrate that AccuACL significantly outperforms AL baselines across various CL algorithms, increasing the average accuracy and forgetting by 23.8% and 17.0%, respectively, in average.
Alignment without Over-optimization: Training-Free Solution for Diffusion Models
Jan 10, 2025



Diffusion models excel in generative tasks, but aligning them with specific objectives while maintaining their versatility remains challenging. Existing fine-tuning methods often suffer from reward over-optimization, while approximate guidance approaches fail to optimize target rewards effectively. Addressing these limitations, we propose a training-free sampling method based on Sequential Monte Carlo (SMC) to sample from the reward-aligned target distribution. Our approach, tailored for diffusion sampling and incorporating tempering techniques, achieves comparable or superior target rewards to fine-tuning methods while preserving diversity and cross-reward generalization. We demonstrate its effectiveness in single-reward optimization, multi-objective scenarios, and online black-box optimization. This work offers a robust solution for aligning diffusion models with diverse downstream objectives without compromising their general capabilities. Code is available at https://github.com/krafton-ai/DAS .
Rare-to-Frequent: Unlocking Compositional Generation Power of Diffusion Models on Rare Concepts with LLM Guidance
Oct 29, 2024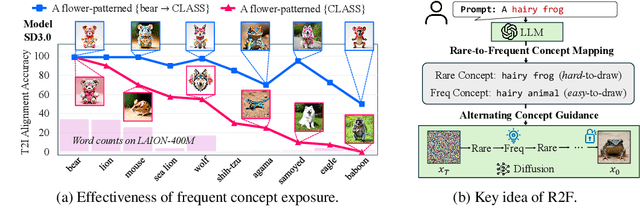
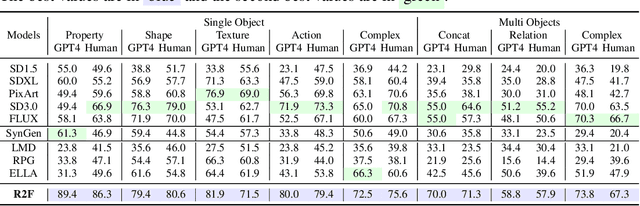
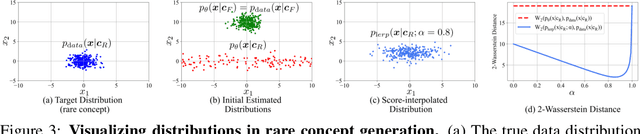
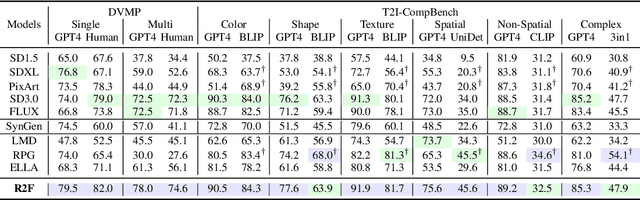
State-of-the-art text-to-image (T2I) diffusion models often struggle to generate rare compositions of concepts, e.g., objects with unusual attributes. In this paper, we show that the compositional generation power of diffusion models on such rare concepts can be significantly enhanced by the Large Language Model (LLM) guidance. We start with empirical and theoretical analysis, demonstrating that exposing frequent concepts relevant to the target rare concepts during the diffusion sampling process yields more accurate concept composition. Based on this, we propose a training-free approach, R2F, that plans and executes the overall rare-to-frequent concept guidance throughout the diffusion inference by leveraging the abundant semantic knowledge in LLMs. Our framework is flexible across any pre-trained diffusion models and LLMs, and can be seamlessly integrated with the region-guided diffusion approaches. Extensive experiments on three datasets, including our newly proposed benchmark, RareBench, containing various prompts with rare compositions of concepts, R2F significantly surpasses existing models including SD3.0 and FLUX by up to 28.1%p in T2I alignment. Code is available at https://github.com/krafton-ai/Rare2Frequent.
Mitigating Dialogue Hallucination for Large Multi-modal Models via Adversarial Instruction Tuning
Mar 15, 2024
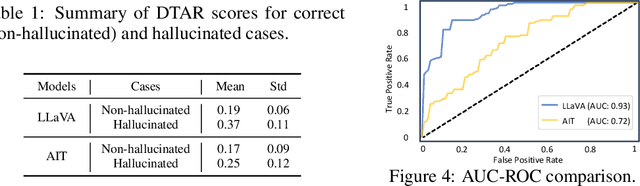
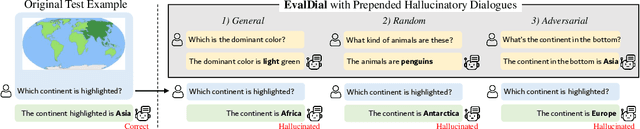
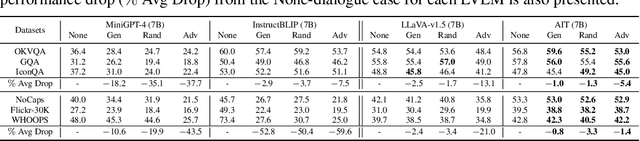
Mitigating hallucinations of Large Multi-modal Models(LMMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LMMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues generated by our novel Adversarial Question Generator, which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LMMs. On our benchmark, the zero-shot performance of state-of-the-art LMMs dropped significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning that robustly fine-tunes LMMs on augmented multi-modal instruction-following datasets with hallucinatory dialogues. Extensive experiments show that our proposed approach successfully reduces dialogue hallucination while maintaining or even improving performance.
Prioritizing Informative Features and Examples for Deep Learning from Noisy Data
Feb 27, 2024
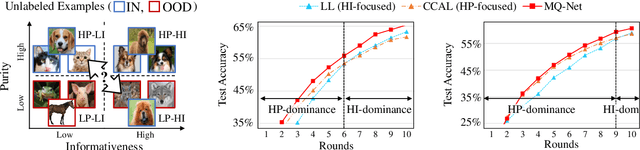
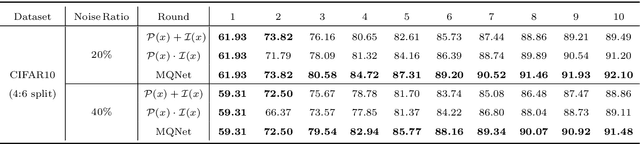
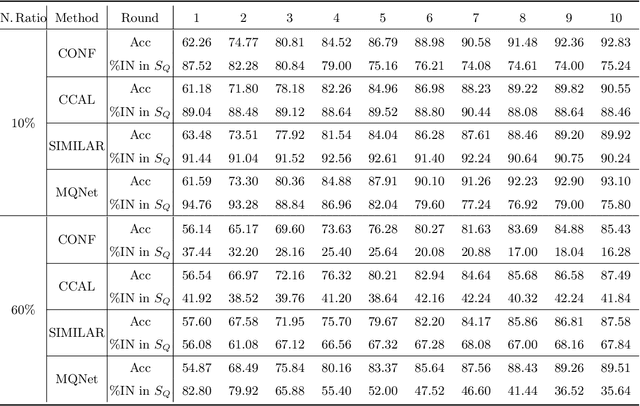
In this dissertation, we propose a systemic framework that prioritizes informative features and examples to enhance each stage of the development process. Specifically, we prioritize informative features and examples and improve the performance of feature learning, data labeling, and data selection. We first propose an approach to extract only informative features that are inherent to solving a target task by using auxiliary out-of-distribution data. We deactivate the noise features in the target distribution by using that in the out-of-distribution data. Next, we introduce an approach that prioritizes informative examples from unlabeled noisy data in order to reduce the labeling cost of active learning. In order to solve the purity-information dilemma, where an attempt to select informative examples induces the selection of many noisy examples, we propose a meta-model that finds the best balance between purity and informativeness. Lastly, we suggest an approach that prioritizes informative examples from labeled noisy data to preserve the performance of data selection. For labeled image noise data, we propose a data selection method that considers the confidence of neighboring samples to maintain the performance of the state-of-the-art Re-labeling models. For labeled text noise data, we present an instruction selection method that takes diversity into account for ranking the quality of instructions with prompting, thereby enhancing the performance of aligned large language models. Overall, our unified framework induces the deep learning development process robust to noisy data, thereby effectively mitigating noisy features and examples in real-world applications.