 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning and Distilling Mixture-of-Experts into Dense Language Models
May 27, 2026Mixture-of-Experts (MoE) is now the dominant architecture for frontier language models, yet it requires all expert parameters to be loaded in memory, making it less preferable for memory-constrained deployment. Existing compression methods reduce the number of experts but the output remains an MoE model with the same fundamental limitation. We present the first systematic framework for converting a trained MoE into a standard fully dense architecture: experts are scored, selected, and grouped, then concatenated into a dense FFN and refined by knowledge distillation from the MoE teacher. We evaluate 7 scoring, 5 grouping, and 2 magnitude scaling methods across a range of selected expert counts on Qwen3-30B-A3B, yielding 350 configurations. We find that the choice of scoring method is the most impactful, with our novel diversity-aware scoring consistently outperforming prior methods on Qwen3-30B-A3B, DeepSeek-V2-Lite, and GPT-OSS-20B. Under a controlled comparison at matched parameter count, MoE-to-dense outperforms dense-to-dense pruning by +6.3 pp in average downstream accuracy after ~4B-token distillation at 1.6x faster training wall-clock speed.
Towards Faithful Agentic XAI: A Verification Method and an Open-World Benchmark for Better Model Faithfulness
May 27, 2026Explainable AI (XAI) helps users interpret model behavior and identify potential faults. Agentic XAI systems use Large Language Models (LLMs) to make explanations more accessible through natural-language interaction, but they can also produce plausible yet unfaithful explanations. This risk arises because unreliable XAI outputs for complex models can be amplified by LLMs and mislead users. We propose Faithful Agentic XAI (FAX), a framework that improves explanation faithfulness through explicit verification. FAX decomposes draft explanations into claims and cross-checks them against inherently faithful tools, filtering unsupported or contradictory claims before final generation. We also introduce CRAFTER-XAI-Bench, an open-world reinforcement learning benchmark with complex policies, diverse goals, and challenging scenarios for assessing model-specific faithfulness. On CRAFTER-XAI-Bench, FAX improves simulation faithfulness from 0.20 for the strongest baseline to 0.46 while maintaining high informativeness, relevance, and fluency. On three tabular benchmarks, FAX performs competitively with prior Agentic XAI baselines, but our analysis shows that these settings can conflate task accuracy with model-specific faithfulness. These findings show that explicit verification is essential for faithful Agentic XAI and that that faithfulness benchmarks must be designed to test explanations against the behavior of the target model itself.
Raon-OpenTTS: Open Models and Data for Robust Text-to-Speech
May 20, 2026Recent advances in text-to-speech (TTS) models show impressive speech naturalness and quality, yet the role of large-scale open data in driving this progress remains underexplored. In this work, we introduce Raon-OpenTTS, an open TTS model that performs competitively with state-of-the-art closed-data TTS models, and Raon-OpenTTS-Pool, a large-scale open dataset for reproducible TTS training. Raon-OpenTTS-Pool consists of 615K hours of 240M speech segments aggregated from publicly available English speech corpora and web-sourced recordings. With a model-based filtering pipeline applied to Raon-OpenTTS-Pool, we derive Raon-OpenTTS-Core, a curated, high-quality subset of 510K hours and 194M speech segments. Using Raon-OpenTTS-Core, we train Raon-OpenTTS, a series of diffusion transformer (DiT)-based TTS models from 0.3B to 1B parameters. On multiple benchmarks, Raon-OpenTTS-1B shows comparable performance to state-of-the-art models such as Qwen3-TTS and CosyVoice 3, which are trained on several million hours of proprietary speech data. Notably, on Seed-TTS-Eval, Raon-OpenTTS-1B achieves a word error rate (WER) of 1.78% and a speaker similarity (SIM) of 0.749, ranking second on WER and first on SIM among recent open-weight TTS baselines. On CV3-Hard-EN, Raon-OpenTTS-1B achieves a WER of 6.15% and a SIM of 0.775, ranking first on both metrics. Furthermore, to support robust evaluation, we introduce Raon-OpenTTS-Eval, a structured benchmark for assessing TTS robustness across diverse acoustic conditions including clean, noisy, in-the-wild, and expressive speech. On Raon-OpenTTS-Eval, Raon-OpenTTS-1B achieves the best average WER and SIM among all evaluated models, and the second-best human preference, as measured by comparative mean opinion score (CMOS). Our data pool, filtering pipeline, training code, and checkpoints are publicly available at https://github.com/krafton-ai/RAON-OpenTTS.
Distilling LLM Agent into Small Models with Retrieval and Code Tools
May 23, 2025Large language models (LLMs) excel at complex reasoning tasks but remain computationally expensive, limiting their practical deployment. To address this, recent works have focused on distilling reasoning capabilities into smaller language models (sLMs) using chain-of-thought (CoT) traces from teacher LLMs. However, this approach struggles in scenarios requiring rare factual knowledge or precise computation, where sLMs often hallucinate due to limited capability. In this work, we propose Agent Distillation, a framework for transferring not only reasoning capability but full task-solving behavior from LLM-based agents into sLMs with retrieval and code tools. We improve agent distillation along two complementary axes: (1) we introduce a prompting method called first-thought prefix to enhance the quality of teacher-generated trajectories; and (2) we propose a self-consistent action generation for improving test-time robustness of small agents. We evaluate our method on eight reasoning tasks across factual and mathematical domains, covering both in-domain and out-of-domain generalization. Our results show that sLMs as small as 0.5B, 1.5B, 3B parameters can achieve performance competitive with next-tier larger 1.5B, 3B, 7B models fine-tuned using CoT distillation, demonstrating the potential of agent distillation for building practical, tool-using small agents. Our code is available at https://github.com/Nardien/agent-distillation.
T1: Tool-integrated Self-verification for Test-time Compute Scaling in Small Language Models
Apr 07, 2025Recent studies have demonstrated that test-time compute scaling effectively improves the performance of small language models (sLMs). However, prior research has mainly examined test-time compute scaling with an additional larger model as a verifier, leaving self-verification by sLMs underexplored. In this work, we investigate whether sLMs can reliably self-verify their outputs under test-time scaling. We find that even with knowledge distillation from larger verifiers, sLMs struggle with verification tasks requiring memorization, such as numerical calculations and fact-checking. To address this limitation, we propose Tool-integrated self-verification (T1), which delegates memorization-heavy verification steps to external tools, such as a code interpreter. Our theoretical analysis shows that tool integration reduces memorization demands and improves test-time scaling performance. Experiments on the MATH benchmark demonstrate that, with T1, a Llama-3.2 1B model under test-time scaling outperforms the significantly larger Llama-3.1 8B model. Moreover, T1 generalizes effectively to both mathematical (MATH500) and multi-domain knowledge-intensive tasks (MMLU-Pro). Our findings highlight the potential of tool integration to substantially improve the self-verification abilities of sLMs.
Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Dec 13, 2024



We explore the use of Residual Vector Quantization (RVQ) for high-fidelity generation in vector-quantized generative models. This quantization technique maintains higher data fidelity by employing more in-depth tokens. However, increasing the token number in generative models leads to slower inference speeds. To this end, we introduce ResGen, an efficient RVQ-based discrete diffusion model that generates high-fidelity samples without compromising sampling speed. Our key idea is a direct prediction of vector embedding of collective tokens rather than individual ones. Moreover, we demonstrate that our proposed token masking and multi-token prediction method can be formulated within a principled probabilistic framework using a discrete diffusion process and variational inference. We validate the efficacy and generalizability of the proposed method on two challenging tasks across different modalities: conditional image generation} on ImageNet 256x256 and zero-shot text-to-speech synthesis. Experimental results demonstrate that ResGen outperforms autoregressive counterparts in both tasks, delivering superior performance without compromising sampling speed. Furthermore, as we scale the depth of RVQ, our generative models exhibit enhanced generation fidelity or faster sampling speeds compared to similarly sized baseline models. The project page can be found at https://resgen-genai.github.io
Lexico: Extreme KV Cache Compression via Sparse Coding over Universal Dictionaries
Dec 12, 2024



We introduce Lexico, a novel KV cache compression method that leverages sparse coding with a universal dictionary. Our key finding is that key-value cache in modern LLMs can be accurately approximated using sparse linear combination from a small, input-agnostic dictionary of ~4k atoms, enabling efficient compression across different input prompts, tasks and models. Using orthogonal matching pursuit for sparse approximation, Lexico achieves flexible compression ratios through direct sparsity control. On GSM8K, across multiple model families (Mistral, Llama 3, Qwen2.5), Lexico maintains 90-95% of the original performance while using only 15-25% of the full KV-cache memory, outperforming both quantization and token eviction methods. Notably, Lexico remains effective in low memory regimes where 2-bit quantization fails, achieving up to 1.7x better compression on LongBench and GSM8K while maintaining high accuracy.
Latent Paraphrasing: Perturbation on Layers Improves Knowledge Injection in Language Models
Nov 01, 2024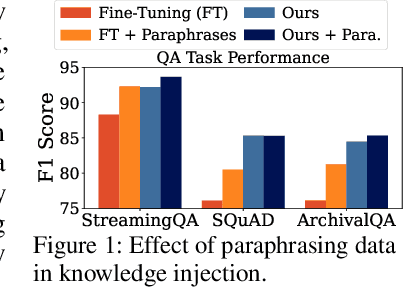

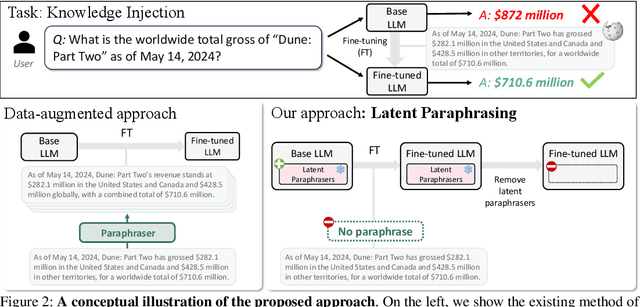
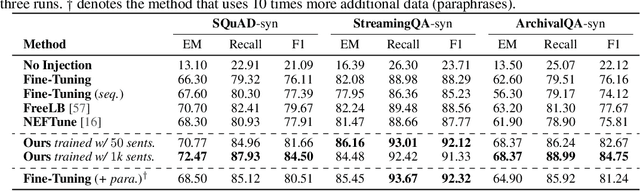
As Large Language Models (LLMs) are increasingly deployed in specialized domains with continuously evolving knowledge, the need for timely and precise knowledge injection has become essential. Fine-tuning with paraphrased data is a common approach to enhance knowledge injection, yet it faces two significant challenges: high computational costs due to repetitive external model usage and limited sample diversity. To this end, we introduce LaPael, a latent-level paraphrasing method that applies input-dependent noise to early LLM layers. This approach enables diverse and semantically consistent augmentations directly within the model. Furthermore, it eliminates the recurring costs of paraphrase generation for each knowledge update. Our extensive experiments on question-answering benchmarks demonstrate that LaPael improves knowledge injection over standard fine-tuning and existing noise-based approaches. Additionally, combining LaPael with data-level paraphrasing further enhances performance.
Rare-to-Frequent: Unlocking Compositional Generation Power of Diffusion Models on Rare Concepts with LLM Guidance
Oct 29, 2024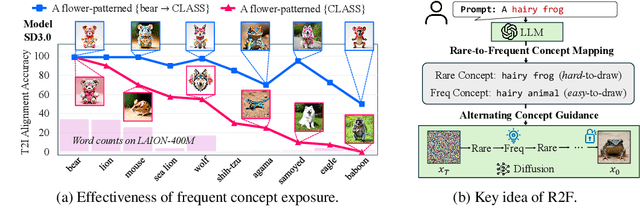
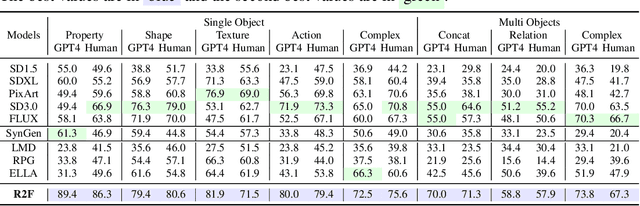
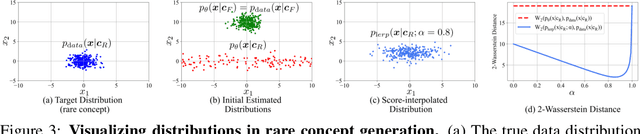
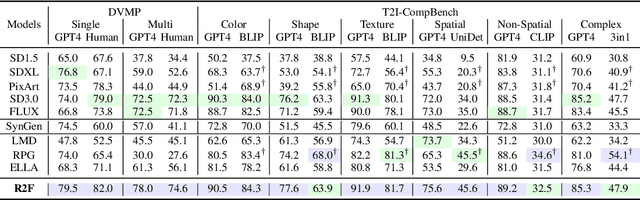
State-of-the-art text-to-image (T2I) diffusion models often struggle to generate rare compositions of concepts, e.g., objects with unusual attributes. In this paper, we show that the compositional generation power of diffusion models on such rare concepts can be significantly enhanced by the Large Language Model (LLM) guidance. We start with empirical and theoretical analysis, demonstrating that exposing frequent concepts relevant to the target rare concepts during the diffusion sampling process yields more accurate concept composition. Based on this, we propose a training-free approach, R2F, that plans and executes the overall rare-to-frequent concept guidance throughout the diffusion inference by leveraging the abundant semantic knowledge in LLMs. Our framework is flexible across any pre-trained diffusion models and LLMs, and can be seamlessly integrated with the region-guided diffusion approaches. Extensive experiments on three datasets, including our newly proposed benchmark, RareBench, containing various prompts with rare compositions of concepts, R2F significantly surpasses existing models including SD3.0 and FLUX by up to 28.1%p in T2I alignment. Code is available at https://github.com/krafton-ai/Rare2Frequent.
Bridging the Gap between Expert and Language Models: Concept-guided Chess Commentary Generation and Evaluation
Oct 28, 2024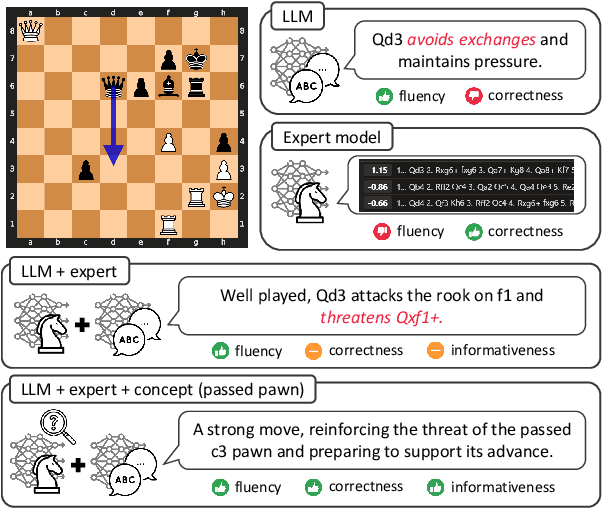
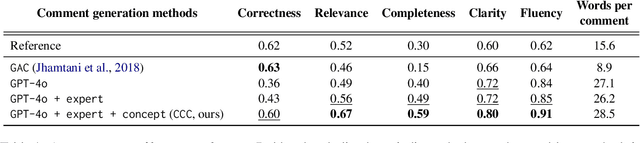
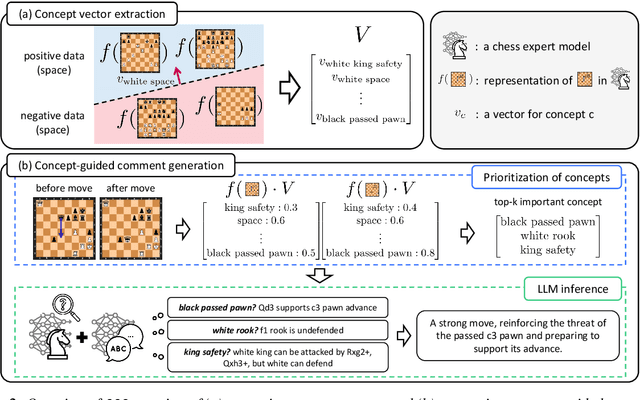
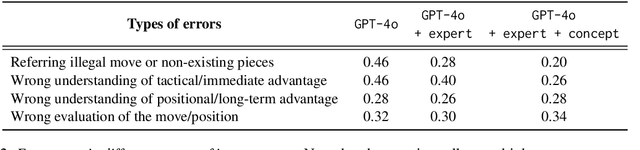
Deep learning-based expert models have reached superhuman performance in decision-making domains such as chess and Go. However, it is under-explored to explain or comment on given decisions although it is important for human education and model explainability. The outputs of expert models are accurate, but yet difficult to interpret for humans. On the other hand, large language models (LLMs) produce fluent commentary but are prone to hallucinations due to their limited decision-making capabilities. To bridge this gap between expert models and LLMs, we focus on chess commentary as a representative case of explaining complex decision-making processes through language and address both the generation and evaluation of commentary. We introduce Concept-guided Chess Commentary generation (CCC) for producing commentary and GPT-based Chess Commentary Evaluation (GCC-Eval) for assessing it. CCC integrates the decision-making strengths of expert models with the linguistic fluency of LLMs through prioritized, concept-based explanations. GCC-Eval leverages expert knowledge to evaluate chess commentary based on informativeness and linguistic quality. Experimental results, validated by both human judges and GCC-Eval, demonstrate that CCC generates commentary that is accurate, informative, and fluent.