 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaon-OpenTTS: Open Models and Data for Robust Text-to-Speech
May 20, 2026Recent advances in text-to-speech (TTS) models show impressive speech naturalness and quality, yet the role of large-scale open data in driving this progress remains underexplored. In this work, we introduce Raon-OpenTTS, an open TTS model that performs competitively with state-of-the-art closed-data TTS models, and Raon-OpenTTS-Pool, a large-scale open dataset for reproducible TTS training. Raon-OpenTTS-Pool consists of 615K hours of 240M speech segments aggregated from publicly available English speech corpora and web-sourced recordings. With a model-based filtering pipeline applied to Raon-OpenTTS-Pool, we derive Raon-OpenTTS-Core, a curated, high-quality subset of 510K hours and 194M speech segments. Using Raon-OpenTTS-Core, we train Raon-OpenTTS, a series of diffusion transformer (DiT)-based TTS models from 0.3B to 1B parameters. On multiple benchmarks, Raon-OpenTTS-1B shows comparable performance to state-of-the-art models such as Qwen3-TTS and CosyVoice 3, which are trained on several million hours of proprietary speech data. Notably, on Seed-TTS-Eval, Raon-OpenTTS-1B achieves a word error rate (WER) of 1.78% and a speaker similarity (SIM) of 0.749, ranking second on WER and first on SIM among recent open-weight TTS baselines. On CV3-Hard-EN, Raon-OpenTTS-1B achieves a WER of 6.15% and a SIM of 0.775, ranking first on both metrics. Furthermore, to support robust evaluation, we introduce Raon-OpenTTS-Eval, a structured benchmark for assessing TTS robustness across diverse acoustic conditions including clean, noisy, in-the-wild, and expressive speech. On Raon-OpenTTS-Eval, Raon-OpenTTS-1B achieves the best average WER and SIM among all evaluated models, and the second-best human preference, as measured by comparative mean opinion score (CMOS). Our data pool, filtering pipeline, training code, and checkpoints are publicly available at https://github.com/krafton-ai/RAON-OpenTTS.
Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Dec 13, 2024



We explore the use of Residual Vector Quantization (RVQ) for high-fidelity generation in vector-quantized generative models. This quantization technique maintains higher data fidelity by employing more in-depth tokens. However, increasing the token number in generative models leads to slower inference speeds. To this end, we introduce ResGen, an efficient RVQ-based discrete diffusion model that generates high-fidelity samples without compromising sampling speed. Our key idea is a direct prediction of vector embedding of collective tokens rather than individual ones. Moreover, we demonstrate that our proposed token masking and multi-token prediction method can be formulated within a principled probabilistic framework using a discrete diffusion process and variational inference. We validate the efficacy and generalizability of the proposed method on two challenging tasks across different modalities: conditional image generation} on ImageNet 256x256 and zero-shot text-to-speech synthesis. Experimental results demonstrate that ResGen outperforms autoregressive counterparts in both tasks, delivering superior performance without compromising sampling speed. Furthermore, as we scale the depth of RVQ, our generative models exhibit enhanced generation fidelity or faster sampling speeds compared to similarly sized baseline models. The project page can be found at https://resgen-genai.github.io
DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Jun 17, 2024Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech
Apr 03, 2024



With the emergence of neural audio codecs, which encode multiple streams of discrete tokens from audio, large language models have recently gained attention as a promising approach for zero-shot Text-to-Speech (TTS) synthesis. Despite the ongoing rush towards scaling paradigms, audio tokenization ironically amplifies the scalability challenge, stemming from its long sequence length and the complexity of modelling the multiple sequences. To mitigate these issues, we present CLaM-TTS that employs a probabilistic residual vector quantization to (1) achieve superior compression in the token length, and (2) allow a language model to generate multiple tokens at once, thereby eliminating the need for cascaded modeling to handle the number of token streams. Our experimental results demonstrate that CLaM-TTS is better than or comparable to state-of-the-art neural codec-based TTS models regarding naturalness, intelligibility, speaker similarity, and inference speed. In addition, we examine the impact of the pretraining extent of the language models and their text tokenization strategies on performances.
Mini-Batch Optimization of Contrastive Loss
Jul 12, 2023



Contrastive learning has gained significant attention as a method for self-supervised learning. The contrastive loss function ensures that embeddings of positive sample pairs (e.g., different samples from the same class or different views of the same object) are similar, while embeddings of negative pairs are dissimilar. Practical constraints such as large memory requirements make it challenging to consider all possible positive and negative pairs, leading to the use of mini-batch optimization. In this paper, we investigate the theoretical aspects of mini-batch optimization in contrastive learning. We show that mini-batch optimization is equivalent to full-batch optimization if and only if all $\binom{N}{B}$ mini-batches are selected, while sub-optimality may arise when examining only a subset. We then demonstrate that utilizing high-loss mini-batches can speed up SGD convergence and propose a spectral clustering-based approach for identifying these high-loss mini-batches. Our experimental results validate our theoretical findings and demonstrate that our proposed algorithm outperforms vanilla SGD in practically relevant settings, providing a better understanding of mini-batch optimization in contrastive learning.
Censored Sampling of Diffusion Models Using 3 Minutes of Human Feedback
Jul 06, 2023
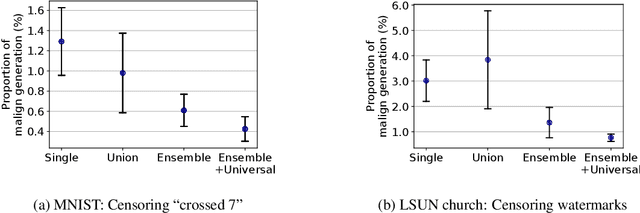
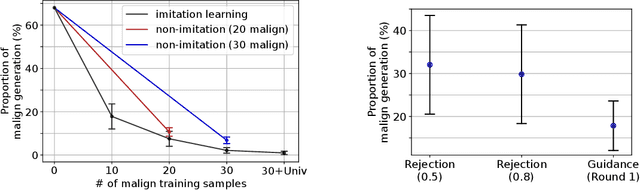
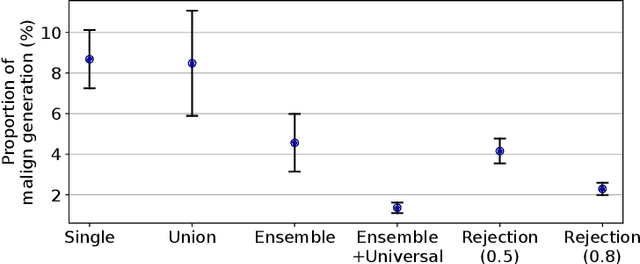
Diffusion models have recently shown remarkable success in high-quality image generation. Sometimes, however, a pre-trained diffusion model exhibits partial misalignment in the sense that the model can generate good images, but it sometimes outputs undesirable images. If so, we simply need to prevent the generation of the bad images, and we call this task censoring. In this work, we present censored generation with a pre-trained diffusion model using a reward model trained on minimal human feedback. We show that censoring can be accomplished with extreme human feedback efficiency and that labels generated with a mere few minutes of human feedback are sufficient. Code available at: https://github.com/tetrzim/diffusion-human-feedback.
RedPen: Region- and Reason-Annotated Dataset of Unnatural Speech
Oct 26, 2022Even with recent advances in speech synthesis models, the evaluation of such models is based purely on human judgement as a single naturalness score, such as the Mean Opinion Score (MOS). The score-based metric does not give any further information about which parts of speech are unnatural or why human judges believe they are unnatural. We present a novel speech dataset, RedPen, with human annotations on unnatural speech regions and their corresponding reasons. RedPen consists of 180 synthesized speeches with unnatural regions annotated by crowd workers; These regions are then reasoned and categorized by error types, such as voice trembling and background noise. We find that our dataset shows a better explanation for unnatural speech regions than the model-driven unnaturalness prediction. Our analysis also shows that each model includes different types of error types. Summing up, our dataset successfully shows the possibility that various error regions and types lie under the single naturalness score. We believe that our dataset will shed light on the evaluation and development of more interpretable speech models in the future. Our dataset will be publicly available upon acceptance.
DailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech
Jul 03, 2022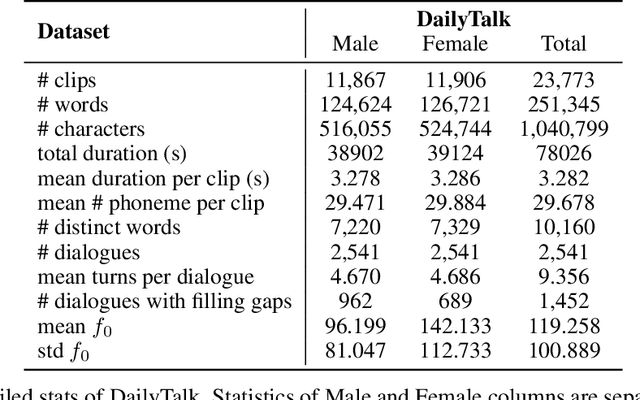
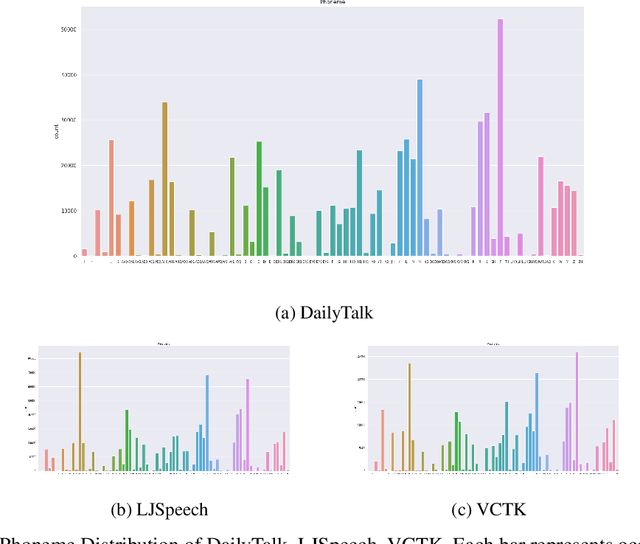

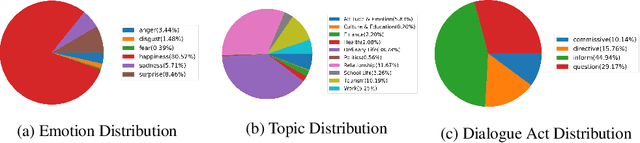
The majority of current TTS datasets, which are collections of individual utterances, contain few conversational aspects in terms of both style and metadata. In this paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for Text-to-Speech. We sampled, modified, and recorded 2,541 dialogues from the open-domain dialogue dataset DailyDialog which are adequately long to represent context of each dialogue. During the data construction step, we maintained attributes distribution originally annotated in DailyDialog to support diverse dialogue in DailyTalk. On top of our dataset, we extend prior work as our baseline, where a non-autoregressive TTS is conditioned on historical information in a dialog. We gather metadata so that a TTS model can learn historical dialog information, the key to generating context-aware speech. From the baseline experiment results, we show that DailyTalk can be used to train neural text-to-speech models, and our baseline can represent contextual information. The DailyTalk dataset and baseline code are freely available for academic use with CC-BY-SA 4.0 license.
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
Apr 04, 2021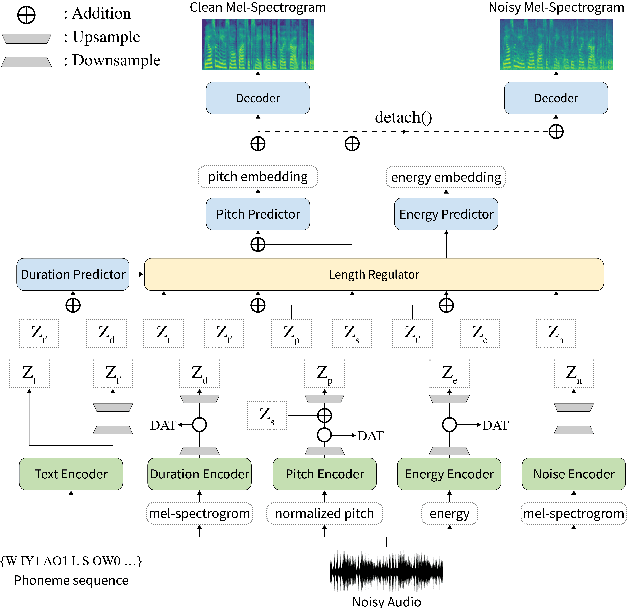
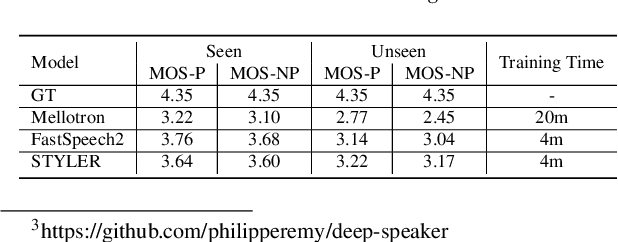
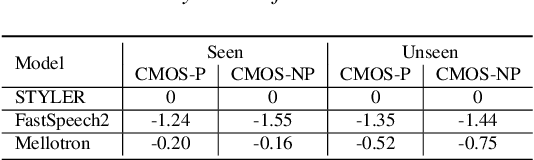
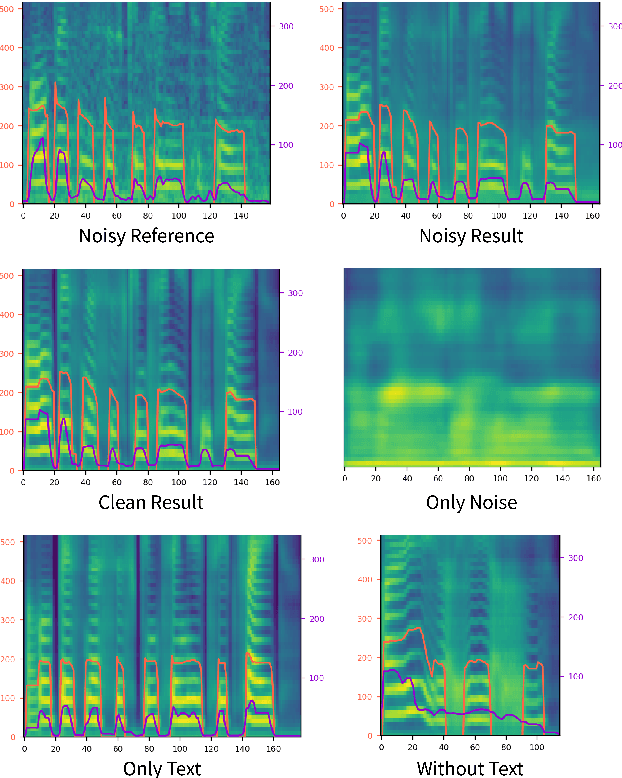
Previous works on neural text-to-speech (TTS) have been addressed on limited speed in training and inference time, robustness for difficult synthesis conditions, expressiveness, and controllability. Although several approaches resolve some limitations, there has been no attempt to solve all weaknesses at once. In this paper, we propose STYLER, an expressive and controllable TTS framework with high-speed and robust synthesis. Our novel audio-text aligning method called Mel Calibrator and excluding autoregressive decoding enable rapid training and inference and robust synthesis on unseen data. Also, disentangled style factor modeling under supervision enlarges the controllability in synthesizing process leading to expressive TTS. On top of it, a novel noise modeling pipeline using domain adversarial training and Residual Decoding empowers noise-robust style transfer, decomposing the noise without any additional label. Various experiments demonstrate that STYLER is more effective in speed and robustness than expressive TTS with autoregressive decoding and more expressive and controllable than reading style non-autoregressive TTS. Synthesis samples and experiment results are provided via our demo page, and code is available publicly.