 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDailyTalk: Spoken Dialogue Dataset for Conversational Text-to-Speech
Paper and Code
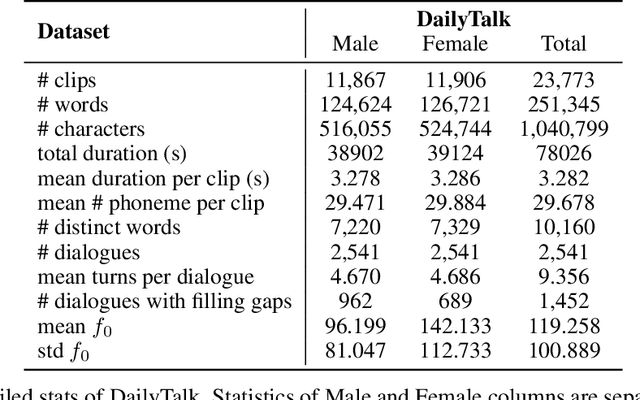
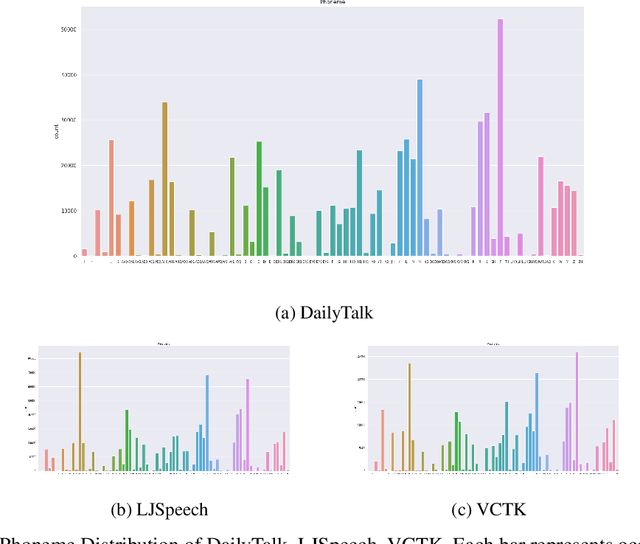

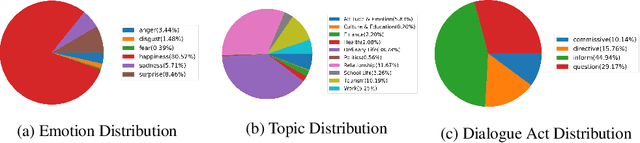
The majority of current TTS datasets, which are collections of individual utterances, contain few conversational aspects in terms of both style and metadata. In this paper, we introduce DailyTalk, a high-quality conversational speech dataset designed for Text-to-Speech. We sampled, modified, and recorded 2,541 dialogues from the open-domain dialogue dataset DailyDialog which are adequately long to represent context of each dialogue. During the data construction step, we maintained attributes distribution originally annotated in DailyDialog to support diverse dialogue in DailyTalk. On top of our dataset, we extend prior work as our baseline, where a non-autoregressive TTS is conditioned on historical information in a dialog. We gather metadata so that a TTS model can learn historical dialog information, the key to generating context-aware speech. From the baseline experiment results, we show that DailyTalk can be used to train neural text-to-speech models, and our baseline can represent contextual information. The DailyTalk dataset and baseline code are freely available for academic use with CC-BY-SA 4.0 license.